1、EXPLAIN关键字
(1)概念
使用EXPLAIN关键字可以模拟优化器执行sQL查询语句,从而知道MySQL是如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈
(2)使用
mysql> select * -> from student; +------------+------------+---------+-------------+------+-------+-------+ | studentno | birthday | classno | phone | sex | sname | point | +------------+------------+---------+-------------+------+-------+-------+ | 2020043002 | 1998-11-18 | 202001 | 18739496123 | ? | ?? | 560 | | 2020043004 | 1998-11-10 | 202001 | 18739496100 | ? | ?? | 601 | | 2020043005 | 1998-11-09 | 202001 | 18739496577 | ? | ?? | 574 | | 2020043006 | 1997-01-18 | 202002 | 18739492332 | ? | ??? | 637 | | 2020043007 | 1998-11-19 | 202001 | 18739494123 | ? | ?? | 567 | | 2020043008 | 1997-02-18 | 202001 | 18739496109 | ? | ?? | 539 | | 2020043009 | 1998-11-15 | 202001 | 18739396145 | ? | ??? | 571 | | 2020043010 | 1998-11-12 | 202001 | 18739490123 | ? | ??? | 583 | +------------+------------+---------+-------------+------+-------+-------+ 8 rows in set (0.00 sec) mysql> explain select * from student; +----+-------------+---------+------+---------------+------+---------+------+------+-------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+---------+------+---------------+------+---------+------+------+-------+ | 1 | SIMPLE | student | ALL | NULL | NULL | NULL | NULL | 8 | NULL | +----+-------------+---------+------+---------------+------+---------+------+------+-------+ 1 row in set (0.00 sec)
2、id
(1)id相同
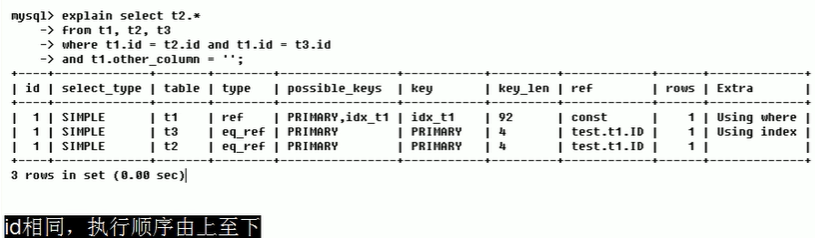
执行顺序是t1、t3、t2
(2)id不同
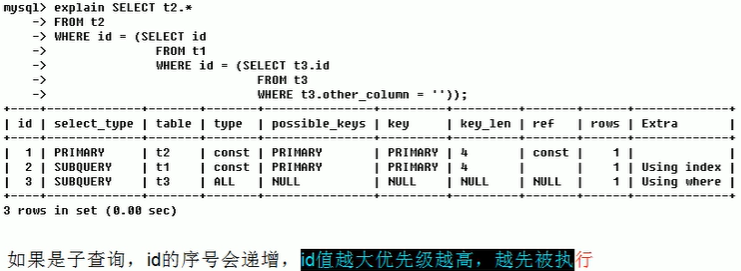
(3)id相同与不同同时存在

3、select_type
(1)类型

4、type
(1)类型
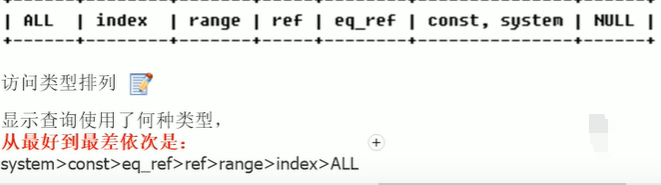
如果是ALL表示执行的sql语句是全表扫描,一般来说最少要达到range级别,最好能达到ref级别
System:表只有一行记录,一般不会出现,可以忽略不计
const:查询只有一个匹配行
mysql> select * -> from student -> where studentno='2020043002' -> ; +------------+------------+---------+-------------+------+-------+-------+ | studentno | birthday | classno | phone | sex | sname | point | +------------+------------+---------+-------------+------+-------+-------+ | 2020043002 | 1998-11-18 | 202001 | 18739496123 | ? | ?? | 560 | +------------+------------+---------+-------------+------+-------+-------+ 1 row in set (0.03 sec)
eq_ref:
唯一性索引扫描
例如:表A的主键与表B的主键进行关联查询,那么表A中的每一行最多不超过1行能与表B进行连接
ref:
返回匹配某个单独值的所有行
例如:表A与表B进行关联查询,表A中的某一个行对应表B中的多个行
查询姓名为'Tom'的学生信息
range:
范围扫描,例如:用between...and进行查询
index:
full index Scan:index只遍历索引树,比All快,all也是都全表,唯一的不同是All是从索引读取,all是从硬盘中读取
5、possibles_key
显示可能运用在这张表中的索引,一个或多个
查询涉及到的字段上若存在索引,则该索引将别列出,但是不一定在查询中被使用
6、key
实际使用的索引,如果为null,则表示没有使用索引
查询中若使用了覆盖索引 (建立索引的字段与查询的字段刚好匹配),则该索引仅出现在key列表中
7、key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好
key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的
查询的时候添加的条件越多,精度越高,但是key_len越大
8、ref
显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值(不理解)
9、rows
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数
10、extra
Using filesort:mysql无法利用事先创建的索引进行排序,只能使用外部的索引排序
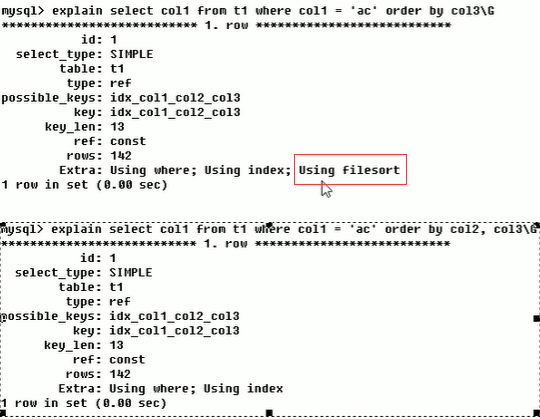
Using temporary:
使了用临时表保存中间结果,MysQL在对查询结果排序时使用临时表。常见于排序order by和分组查询group by
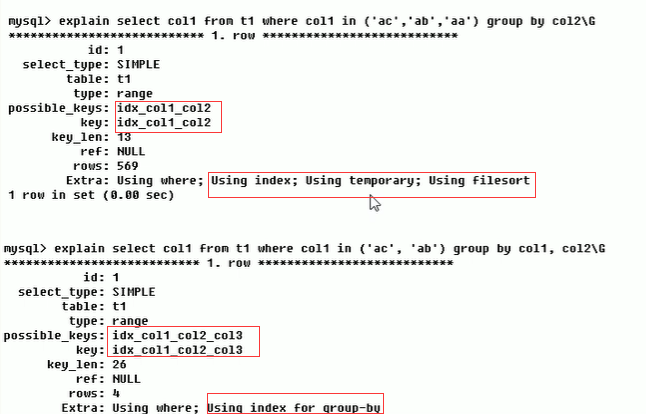
Using index:
表示相应的select操作中使用了覆盖索引(Covering Index),避免访问了表的数据行
如果同时出现using where,表明索引被用来执行索引键值的查找
如果没有同时出现using where,表明索引用来读取数据而非执行查找动作
