最近组长安排我一项任务:利用ELK日志分析平台收集一个项目的日志;期间也遇到各种问题,便想记录下来,希望在记录我成长的过程中,为大家带来一点点帮助~~(如果存在有错误的地方,希望批评指正!)
一、概念介绍
ELK由ElasticSearch、Logstash和Kiabana三个开源工具组成:
1)ElasticSearch是一个基于Lucene的开源分布式搜索服务器。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
在elasticsearch中,所有节点的数据是均等的。
2)Logstash是一个完全开源的工具,它可以对你的日志进行收集、过滤、分析,支持大量的数据获取方法,并将其存储供以后使用(如搜索)。说到搜索,logstash带有一个web界面,搜索和展示所有日志。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
3)Kibana 是一个基于浏览器页面的Elasticsearch前端展示工具,也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
二、Logstash
1)输入(input):采集各种样式、大小和来源的数据
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。Logstash 支持各种输入支持(file,syslog,redis,beats) ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
file:从文件系统的文件中读取;
syslog:在514端口上监听系统日志消息,并根据RFC3164标准进行解析;
redis:从redis service中读取;
beats:从filebeat中读取;
2)过滤(filter):实时解析和转换数据
数据从源传输(input)到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
grok:解析任意文本数据,Grok 是 Logstash 最重要的插件。它的主要作用就是将文本格式的字符串,转换成为具体的结构化的数据,配合正则表达式使用。
mutate:对字段进行转换。例如对字段进行删除、替换、修改、重命名等。
drop:丢弃一部分events不进行处理。
3)输出(output):选择您的存储库,导出您的数据
尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。(在此处只详细说明Elasticsearch)
elasticsearch:可以高效的保存数据,并且能够方便和简单的进行查询。
三、ELK整体方案
Logstash是一个ETL工具,负责从每台机器抓取日志数据,对数据进行格式转换和处理后,输出到Elasticsearch中存储。
Elasticsearch是一个分布式搜索引擎和分析引擎,用于数据存储,可提供实时的数据查询。
Kibana是一个数据可视化服务,根据用户的操作从Elasticsearch中查询数据,形成相应的分析结果,以图表的形式展现给用户。
在这里还用到redis作为缓存使用。通过logstash搜集日志数据存入redis,再通过logstash对数据格式转化处理后储存到Elasticsearch中。
四、Logstash在linux下的安装部署
1)首先从官网 https://www.elastic.co/downloads 下载logstash 并解压
2)编写配置文件
--------------- test1.config
input:
path:指定日志文件路径。此处示例:可以添加多个不同路径的日志文件;
type:指定一个名称,设置type后,可以在后面的filter和output中对不同的type做不同的处理,适用于需要消费多个日志文件的场景。
start_position:指定起始读取位置,"beginning"表示从文件头开始,"end"表示从文件尾开始(类似tail -f).
sincedb_path:与Logstash的一个坑有关。通常Logstash会记录每个文件已经被读取到的位置,保存在sincedb中,如果Logstash重启,那么对于同一个文件,会继续从上次记录的位置开始读取。如果想重新从头读取文件,需要删除sincedb文件,sincedb_path则是指定
了该文件的路径。为了方便,我们可以根据需要将其设置为“/dev/null”,即不保存位置信息。
output:
host:redis所在服务器地址;
port:端口号;
data_type:
list:使用rpush
channel:使用publish
key:发布通道名称;
password:redis密码,默认不使用密码;
db:使用redis的数据库,默认使用0号;
input {
file {
path => ["/data/log/test1.log","/data/log/test2.log","/data/home/test2.log",.....]
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
#输入到redis
output {
redis {
host => "XXX"
port => "XXX"
data_type => "list"
key => "XXXX"
db => XX
password => "XXX"
}
}
-------------- test2.config
input:
上一个配置文件的输出即为该配置文件的输入(对应的字段信息要保持一致)
filter:
此处就介绍我在处理日志用到的相关过滤插件;
drop():从配置文件可以看出如果message(即:输出的每条日志信息)不包含字符串“response_log_”就丢弃过滤该条日志,开始处理下一条日志。
grok:过滤掉不想要的日志,想要的的日志我们就要通过grok进行下一步处理;此处通过正则表达式抠出自己想要的json部分信息,并存放在mesg字段里。
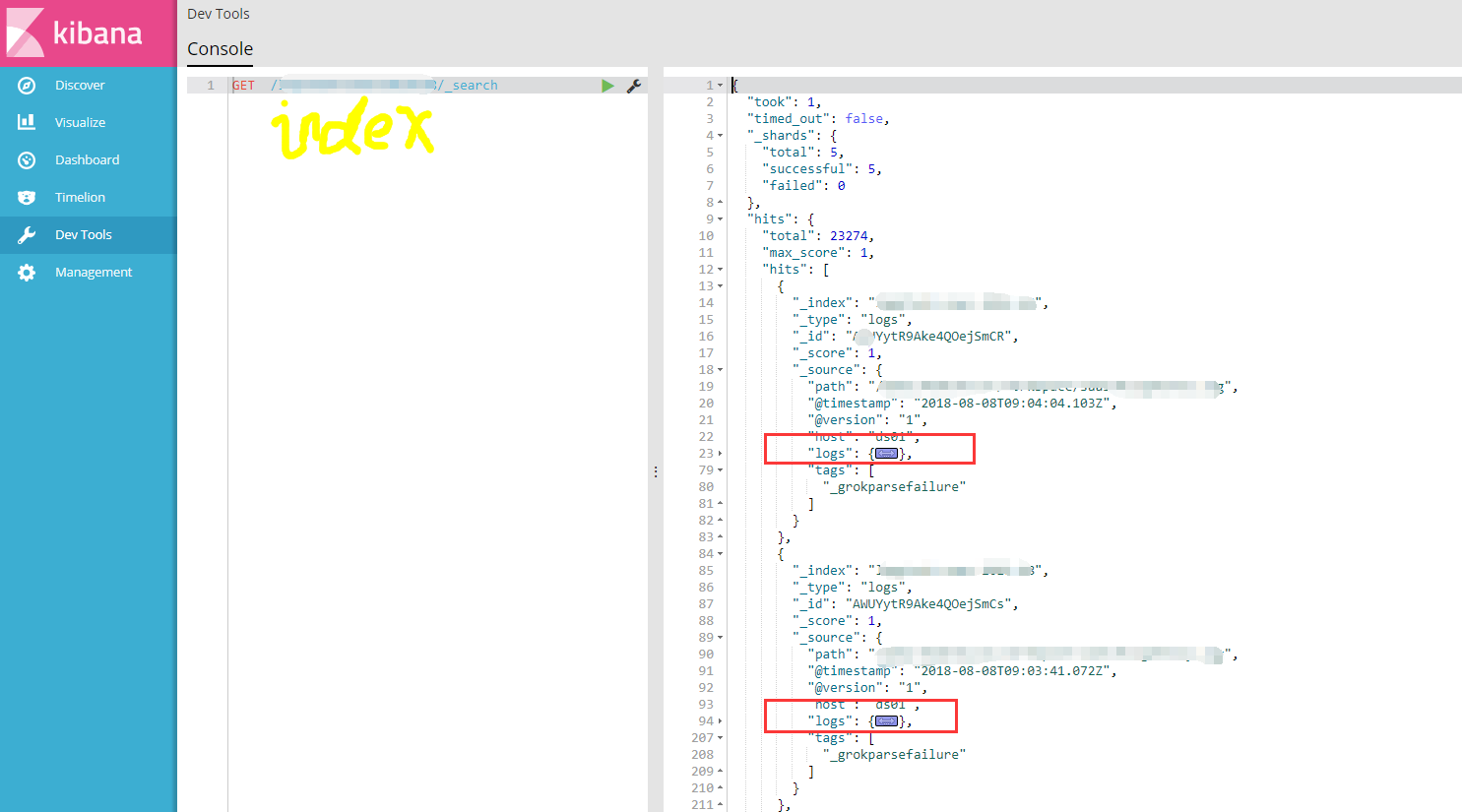
json:再进一步的对mesg进行json解析,放入到logs字段,处理结束后就把不需要的message、mesg删除掉;
(对于logstash 的filter详细功能介绍可通过官网查看)
output:
最后将处理后的结果存入到es中(把日志进行json解析是为了提高es查询搜索效率)
#需要处理的日志(示例)
2018-08-08T07:22:44.266Z ds01 2018-07-24 16:15:16.528 INFO 18879 --- [XNIO-2 task-150] c.i.s.gateway.controller.test: _response_log_{"clientInfo":"test"}
input {
redis {
host => "XXX"
port => "XXX"
data_type => "list"
key => "XXXX"
db => XX
password => "XXX"
}
}
filter{
if([message] =~ "^(?!.*?response_log_).*$")){
drop {}
}
grok {
match=>{"message" => ".*response_log_(?<mesg>(.*))"}
}
json {
source => "mesg"
target => "logs"
remove_field=>["mesg"]
remove_field=>["message"]
}
}
output{
elasticsearch {
index => "XXXX"
hosts => ["XXXXX:XXX"]
}
}
运行logstash:bin/logstash -f ./configs/ (configs与bin处于同级目录test1.conf、test2.conf处于configs目录下)这种写法可以自动执行该目下的所有配置文件,单个执行也是可以的。
最后通过Kibana查询结果如下图所示: