一:日志如何监控
在上一篇博客Grafana、Prometheus-监控平台中,简单了解了Grafana与Prometheus对项目做特定的监控打点,可视化的配置操作。
但是对于没有设置监控或者不容易进行监控的遗留应用程序,有时重写、修补或重构该应用程序以暴露内部状态的成本绝对不是一项有利的工程投资,
或者还可能存在监控上的技术限制。但是你仍然需要了解应用程序内部发生的情况,最简单的方法之一是调整日志输出。
就例如在我的另一篇博客 分布式调度任务-ElasticJob 中遇到的bug,com.dangdangelastic-job中间件会出现一直在选主,导致业务程序执行不下去的问题,
日志会一直在打印 LeaderElectionService [traceId=] - Elastic job: leader node is electing, waiting for 100 ms at server '192.168.0.6',
像这种问题就很难通过业务打点去监控,因此就需要监控业务系统的日志文件,进而去监控系统是否出问题。
网上对于业务日志的监控,我比较过这三个
1:ELK-“ELK”是三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch、Logstash 和 Kibana。
Elasticsearch 是一个搜索和分析引擎。
Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等“存储库”中。
Kibana 则可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化。
2:Loki,Grafana Labs 团队最新的开源项目,是一个水平可扩展,高可用性,多租户的日志聚合系统。
3:mtail :它是一个google开发的日志提取工具,从应用程序日志中提取指标以导出到时间序列数据库或时间序列计算器,
用途就是: 实时读取应用程序的日志、 再通过自己编写的脚本进行分析、 最终生成时间序列指标。
工具适合自己的才是最好的,无论是ELK还是Loki都是功能齐全的日志采集系统,当然它们也有各自的优势,
但是因为本人当前只是为了采集生产日志中的一个error,所有并不想去安装配置多个基建,因为才采用最简单的mtail。
二:mtail 安装启动
下载地址:https://github.com/google/mtail/releases
安装:
chmod 0755 mtail sudo cp mtail /usr/local/bin
编写监控脚本
touch /etc/mtail/Elastic_job_electing_count.mtail
内容如下:
counter elastic_job_electing_count /leader node is electing, waiting for 100 ms at server/ { elastic_job_electing_count ++ }
统计 “leader node is electing, waiting for 100 ms at server” 出现的次数。
当然mtail支持的脚本语法还是比较全的,可以参考:https://github.com/google/mtail/blob/main/docs/Programming-Guide.md
运行:
sudo mtail --progs /etc/mtail --logs '/var/log/*.log'
第一个参数--progs告诉mtail在哪里找到我们的程序,第二个参数--logs告诉mtail在哪里找到要解析的日志文件。
我们使用glob模式(https://godoc.org/path/filepath#Match)来匹配/var/log目录中的所有日志文件。
你可以指定以逗号分隔的文件列表,也可以多次指定--logs参数。
参数详解:控制台运行 mtail --help
下面列举几个简单的参数
参数 描述
-address 绑定HTTP监听器的主机或IP地址
-alsologtostderr 记录标准错误和文件
-emit_metric_timestamp 发出metric的记录时间戳。如果禁用(默认设置),则不会向收集器发送显式时间戳。
-expired_metrics_gc_interval metric的垃圾收集器运行间隔(默认为1h0m0s)
-ignore_filename_regex_pattern 需要忽略的日志文件名字,支持正则表达式。
-log_dir mtail程序的日志文件的目录,与logtostderr作用类似,如果同时配置了logtostderr参数,则log_dir参数无效
-logs 监控的日志文件列表,可以使用,分隔多个文件,也可以多次使用-logs参数,也可以指定一个文件目录,支持通配符*,指定文件目录时需要对目录使用单引号。如:
-logs a.log,b.log
-logs a.log -logs b.log
-logs ‘/export/logs/*.log’
-logtostderr 直接输出标准错误信息,编译问题也直接输出
-override_timezone 设置时区,如果使用此参数,将在时间戳转换中使用指定的时区来替代UTC
-port 监听的http端口,默认3903
-progs mtail脚本程序所在路径
-trace_sample_period 用于设置跟踪的采样频率和发送到收集器的频率。将其设置为100,则100条收集一条追踪。
-v v日志的日志级别,该设置可能被 vmodule标志给覆盖.默认为0.
-version 打印mtail版本
程序启动后默认监听3903端口,可以通过http://ip:3903访问,metrics可以通过http://ip:3903/metrics访问
三:配置Prometheus数据源
Prometheus的安装部署见:Grafana、Prometheus-监控平台
vim prometheus-config.yml
# 全局配置 global: scrape_interval: 15s evaluation_interval: 15s scrape_configs: # 监控mtail日志 - job_name: 'mtail' static_configs: - targets: ['内网ip:3903']
重启Prometheus后,在grafana大盘里新增一个新的panel,再为其配置已经设置好的datasource
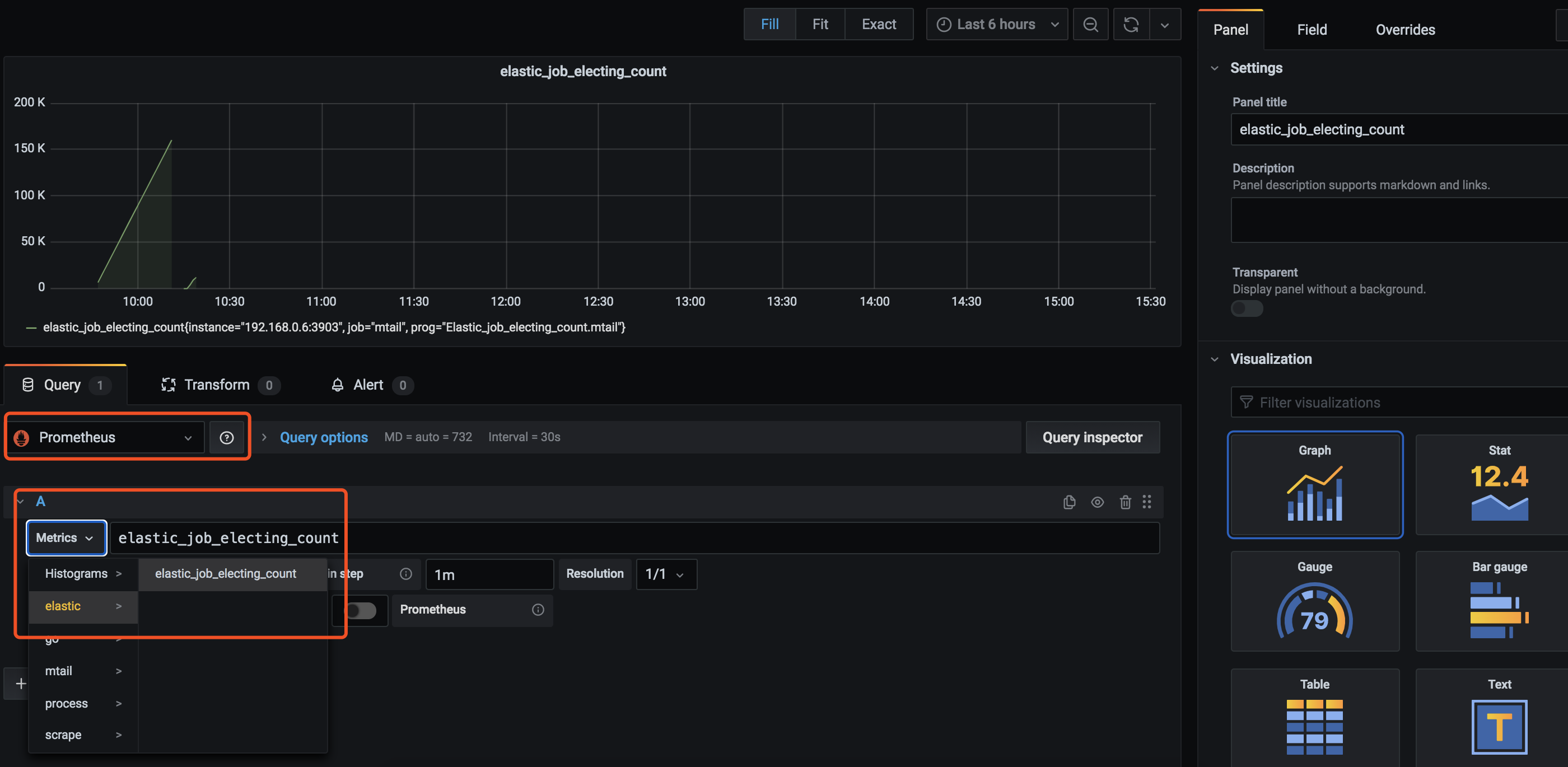
至此,一个简单去监控业务系统日志中,出现某段日志的统计就实现了, 然后再为其配置一个告警规则,并发送钉钉或邮件,就可以方便及时的处理线上的问题了。