背景
平台目前的分析任务主要以Hive为主,分析后的结果存储在HDFS,用户通过REST API或者Rsync的方式获取分析结果,这样的方式带来以下几个问题:
(1)任务执行结束时间未知,用户必须自行编写代码不断地通过REST API请求分析结果,直至获取到分析结果为止,其中还需要处理分析结果过大,转而通过Rsync方式获取;
(2)受限于Hive SQL的表达能力,用户的计算逻辑无法完全表述,获取分析结果后需要再计算,然后入库;
(3)基于(1)、(2)的原因,用户编写大量复杂且冗余的代码处理上述逻辑。
为了改善上述情况,平台设计的解决方案如下:
(1)使用Spark替换Hive(MapReduce)分析任务,结合Hive SQL和Spark API两种方式,使用户的计算逻辑可以得到很好的表述;
(2)用户无需使用“Pull”的方式获取结果,转而使用“Post”的方式将分析结果存入自己的MySQL数据库中;
(3)提供基于Python的MySQL通用批量写入工具方便用户使用。
方案
MySQL批量写入工具需要解决以下几个问题:
(1)通用:不受限于具体数据格式的束缚;
用户需要将不同格式的数据写入不同的数据库/表,意味着数据库的主机名、端口、用户名、密码、数据库实例可以通过参数定制,不同的数据格式使用SQL语句表达,如“insert into students (c_number, c_name) values (%s, %s)”。
(2)多线程:使用多线程的方式,提高写入的吞吐量;
典型的“生产者——消费者”问题,用户需要将数据首先写入一个线程安全的共享队列中;“消费者”线程不断的从这个共享队列中获取数据并缓存,待缓存数据达到一定数目时,将这批数据一次性写出;然后继续上述过程。
除此之外,“消费者”线程需要能够“正常”结束。
(3)数据库连接控制:需要避免连接过多或者频繁连接带来的性能开销;
“消费者”线程需要能够重复利用一定数目的数据库连接,数据库连接由专门的连接池提供,工作流程如下:
a. 从连接池中获取数据库连接;
b. 通过a中的连接将数据批量写出并commit;
c. 将数据库连接归还给连接池。
(4)API:简单易用
我们将批量写入工具定义为一个“存储引擎”,考虑到MySQL的吞吐量可能在大数据量的写入下会成为一个瓶颈,后期会考虑扩展其它工具。因此定义一个基类表示抽象的“存储引擎”,并扩展出本文具体讨论的MySQL“存储引擎”:MySQLStorageEngine。
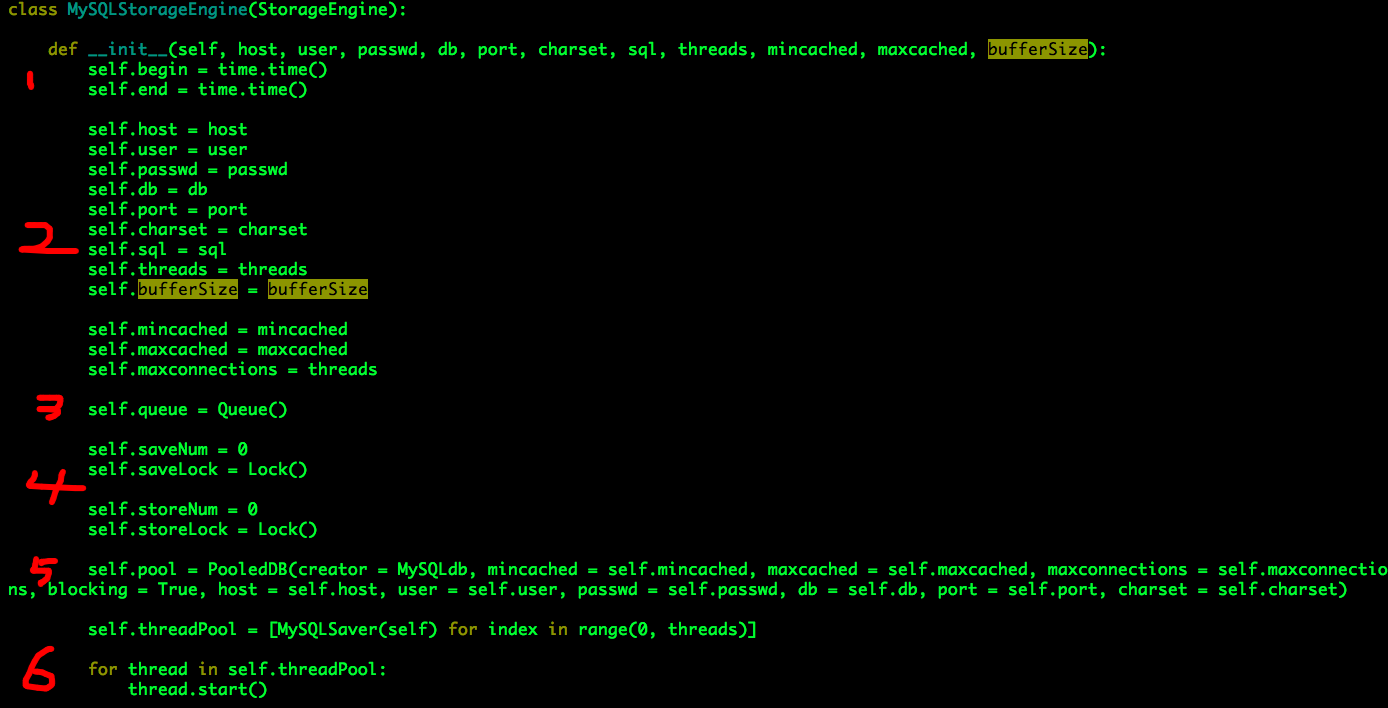
MySQLStorageEngine的初始化过程涉及以下六个方面:
(1)begin、end用于统计一次批量写入的耗时;
(2)接收用户定制的参数;
host:数据库主机名;
user:数据库登录用户名;
passwd:数据库登录密码;
db:数据库实例
port:数据库端口
charset:数据库字符编码
sql:写入数据时使用的SQL语句,如“insert into students (c_number, c_name) values (%s, %s)”
threads:写入线程数目;
bufferSize:写入线程内部的缓存区大小,亦即每一次“batch”的大小;
mincached:数据库连接池内部最小缓存连接数;
maxcached:数据库连接池内部最大缓存连接数;
maxconnections:数据库连接池所允许同时建立的最大连接数:目前与写入线程数目相同。
(3)构建共享队列queue;
(4)saveNum、storeNum用于统计用户写入总数及实际(成功)写入总数,考虑到多线程使用环境,分别构建相应的锁对象saveLock、storeLock;
(5)构建数据库连接池,这里使用的是DBUtils PooledDB;
(6)构建写入线程(多个)并启动。
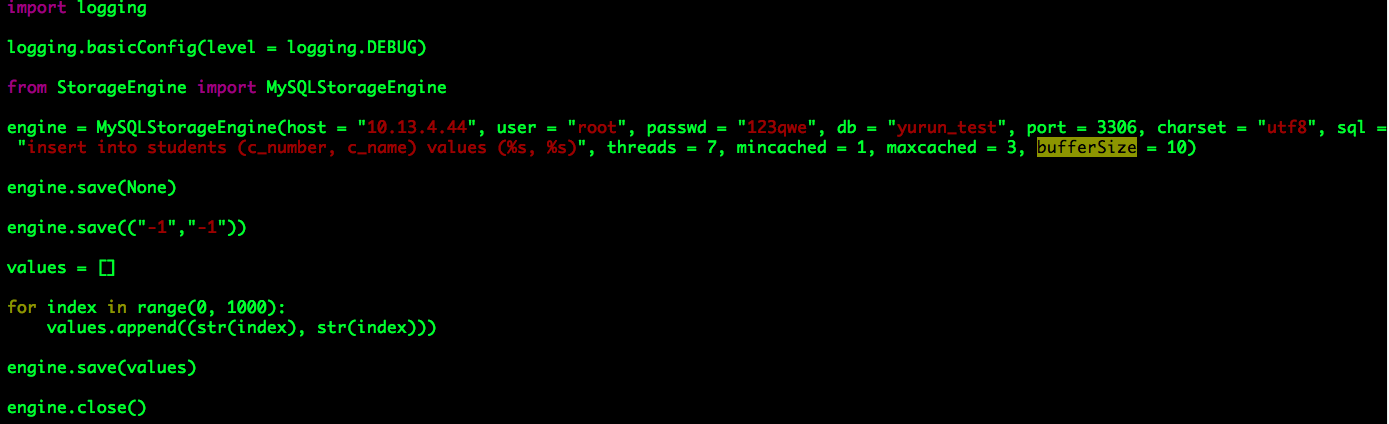
至此,MySQLStorageEngine实例创建完毕,并且启动内部多个写入线程用于消费队列queue中数据。用户可通过实例方法save写入数据:

可见,save支持两种类型的数据,一种是Tuple,另一种是Tuple数组,它们都被保存至队列queue中,由写入线程负责处理。
用户写入完成之后,可以通过方法close关闭“存储引擎”,
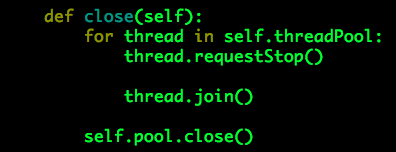
需要注意的是,用户写入的数据实际是保存在队列queue中的,“用户写入完成”并不代表队列queue中的数据已全部被写入线程消费且完成入库,因此必须首先通知写入线程用户数据已全部写入完毕(requestStop),然后等待写入线程运行完毕(join),最后关闭数据库连接池。
写入线程由MySQLSaver实现,它的初始化过程特别简单:
(1)接收“存储引擎”实例engine;
(2)定义实例变量stop,初始值为False,用于表示用户尚有数据写入;True表示用户写入结束。

MySQLSaver的工作流程如下:

(1)初始化缓存区buffer,用于保存从队列queue消费而来的数据;
(2)循环从队列queue获取数据,如果没有获取到数据,则执行(3);如果获取到数据,则执行(4);
(3)如果用户写入结束(stop值为True)而且队列中已经没有剩余数据,将缓冲区buffer中的数据一次性写入(__save),结束线程(break);
(4)将(2)中获取到的数据存入缓存区,如果缓存区的大小达到数目限制,则将缓冲区buffer中的数据一次性写入(__save),继续(2)。
__save的工作流程如下:
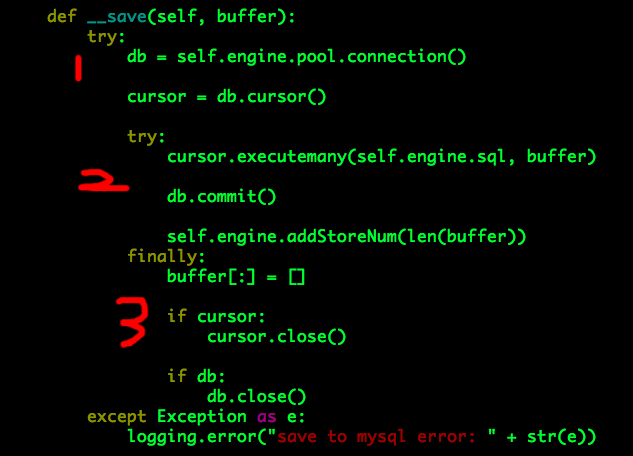
(1)从连接池pool中获取数据库连接db并构建实例cursor;
(2)写入buffer中的数据(executemany)并提交(commit);
(3)清空buffer、关闭实例cursor、将数据库连接db“归还”给连接池(close)。
使用示例如下: