第二章 置信区间估计
估计量和估计值的写法?

估计值希腊字母上边有一个hat
点估计中矩估计的原理?
用样本矩来估计总体矩,用样本矩的连续函数来估计总体矩的连续函数,这种估计法称为矩估计法。Eg:如果一阶矩则样本均值估计总体均值
公式化之后的表达:

其中的μ1的表达式:

矩估计和最大似然估计最终估计的特点是什么?
二项分布的均值两种估计都相同,正态分布的均值两种估计都相同。但是其他分布仍存在不同的现象。
无偏性是什么?
估计值的均值与总体均值相同,除中间值之外的部分是随机误差。
均值的无偏性特殊在哪里?
任何存在期望的分布估计均值都是无偏的。
什么是无偏化?
就是利用数学变换得到无偏表达
一个参数可以有不同的无偏估计量吗?
可以。
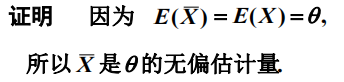
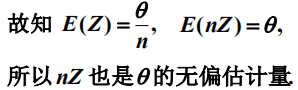
有效性的主体的是什么?
估计量的方差越小越有效。Eg:估计的总体均值的方差较小则比较有效。
区间估计和点估计谁是具有随机性的?
区间估计。因为点估计是估计一个原始数值,而区间估计是一个原始分布。
置信区间的定义举例解释?
想要估计总体均值,做100次实验,每次实验抽20个样本。处理后得到100个抽样分布区间,有95个区间中存在总体参数,就说有95%的把握认为你只使用一次实验数据的20个样本得到的置信区间中含有总体均值。
枢轴量是什么?
就是参数估计中的待估参数。
求置信区间的三步?
1.样本数据的总体分布2.置信度3.代公式计算
似然函数形式上是什么?
在已知样本来自于何分布之后,虽然不知道该分布中的参数是何值,但是可以反求出,所以一开始用某些字母代替,这样每一个样本x值通过分布率/概率密度对应一个该点概率值,将这些概率值的乘积连乘的结果就是似然函数。
点估计方法的使用顺序?
在统计问题中往往先使用最大似然估计法, 在最大似然估计法使用不方便时, 再用矩估计法。
伯努利大数定理是什么?

当样本量足够大的时候频率趋近于概率。
什么是用t分布的信号?
总体方差未知时
现阶段学习的估计条件是什么?
总体来自正态分布:


哪些问题要考虑单侧置信区间?
在某些实际问题中, 例如, 对于设备、元件的寿命来说, 平均寿命长是我们希望的, 我们关心的是平均寿命 的“下限”; 与之相反, 在考虑产品的废品率 p时, 我们常关心参数 p的 “上限” , 这就引出了单侧置信区间的概念。
对称分布和非对称分布的区别在抽样函数上有何区别?
对称函数的两边界取值是正负相反数即可:
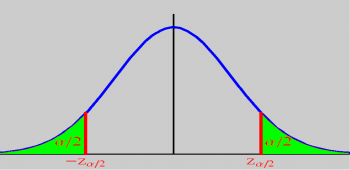
非对称函数的两边界取值要计算两边置信度相关数值: