py_while循环及基本运算符
一、字符串的格式化输出
现有一练习需求,问用户的姓名、年龄、工作、爱好 ,然后打印成以下格式

''' ------------ info of Alex Li ----------- Name : Alex Li Age : 22 job : Teacher Hobbie: girl ------------- end ----------------- '''
只需要把要打印的格式先准备好, 由于里面的 一些信息是需要用户输入的,你没办法预设知道,因此可以先放置个占位符,再把字符串里的占位符与外部的变量做个映射关系就好啦
name = input('请输入姓名:')
age = input('请输入年龄:')
job = input('请输入职业:')
hobbie = input('请输入爱好:')
msg = '''
------------ info of %s -----------
Name : %s
Age : %s
job : %s
Hobbie: %s
------------- end -----------------
'''%(name,name,age,job,hobbie)
print(msg)
------------ info of 烟雨江南 -----------
Name : 烟雨江南
Age : 18
job : 作者
Hobbie: 写书
------------- end -----------------
%s就是代表字符串占位符,除此之外,还有%d,是数字占位符, 如果把上面的age后面的换成%d,就代表你必须只能输入数字啦
msg = "我是%s,年龄%d,目前学习进度为80%"%('金鑫',18)
print(msg)
这样会报错的,因为在格式化输出里,你出现%默认为就是占位符的%,但是我想在上面一条语句中最后的80%就是表示80%而不是占位符,怎么办?
msg = "我是%s,年龄%d,目前学习进度为80%%"%('金鑫',18)
print(msg)
这样就可以了,第一个%是对第二个%的转译,告诉Python解释器这只是一个单纯的%,而不是占位符。
二、流程控制之while循环
程序中重复的做之前的事情,输入账号,密码,等操作。
1、基本循环:
while 条件:
循环体
例如:
sum = 0
while sum < 5: # 1、条件成立
print(666) # 2、进入循环体,由于条件一直成立,所以进入无线循环
# 条件成立则进入循环体
上述例子由于sum = 0 始终小于5,所以进入死循环,那么要想终止循环我们应该怎么做呢?
2、如何终止循环
- 改变条件
- break语句,用于完全结束一个循环,跳出循环体执行循环后面的语句
- 调用系统命令:quit() exit() ------>不建议使用
sum = 0
while sum < 5:
print(666)
sum = sum + 1
# 第一次循环,0<5条件成立,进入循环体,打印666,0+1赋值给sum,sum = 1,进行条件判断,1<5条件成立进入第二次循环以此类推......
666
666
666
666
666
-----------------------------------------------------------------------------------------
sum = 0
while sum < 5:
print(666)
break
print('hello world')
# 见到brek语句立即终止循环,执行循环后面的语句
666
hello world
3、continue语句:终止本次循环进入下一循环
sum = 0
while sum < 10:
sum += 1
if 3 < sum <8: # 如果3<sum<8则终止本次循环,不执行后面的语句,直接进行下一次循环
continue
print(sum)
1
2
3
8
9
10
4、while...else...
while 后面的else 作用是指,当while 循环正常执行完,中间没有被break 中止的话,就会执行else后面的语句
循环正常结束:
sum = 0
while sum < 10:
sum += 1
if 3 < sum <8:
continue
print(sum)
else:
print('打印完成')
1
2
3
8
9
10
打印完成
-------------------------------------------------------
当break出现终止循环时
sum = 0
while sum < 10:
sum += 1
if 5 < sum :
break
print(sum)
else:
print('打印完成')
1
2
3
4
5
三、基本运算符
运算符
计算机可以进行的运算有很多种,可不只加减乘除这么简单,运算按种类可分为算数运算、比较运算、逻辑运算、赋值运算、成员运算、身份运算、位运算,今天我们暂只学习算数运算、比较运算、逻辑运算、赋值运算、成员运算
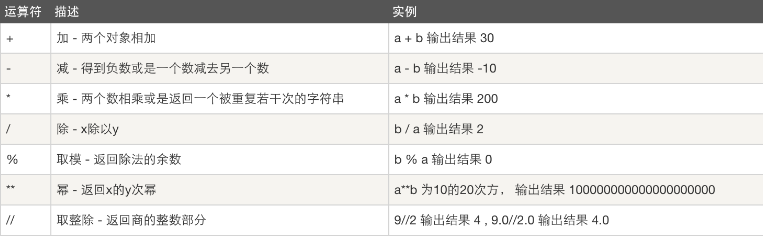
算数运算
以下假设变量:a=10,b=20
比较运算
以下假设变量:a=10,b=20
字符串进行比较的话,使用的是字符对应的ascii码值。

赋值运算
以下假设变量:a=10,b=20

逻辑运算

针对逻辑运算的进一步研究:
1、 在没有()的情况下not 优先级高于 and,and优先级高于or,即优先级关系为( )>not>and>or,同一优先级从左往右计算。
2 、 x or y , x为真,值就是x,x为假,值是y;
x and y, x为真,值是y,x为假,值是x;
例如:
1 > 1 or 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6 not 2 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6 逻辑运算符的结果到底是什么类型??? 结果取决于两个操作数的类型!!! 针对and操作:第一个操作数如果是可以转成False的话,那么第一个操作数的值,就是整个逻辑表达式的值。 如果第一个操作数可以转成True,第二个操作数的值就是整个表达式的值。 针对or操作:第一个操作数如果是可以转成False的话,第二个操作数的值就是整个表达式的值。 如果第一个操作数可以转成True, 第一个操作数的值,就是整个逻辑表达式的值。
逻辑运算符规则和短路操作



成员运算:
除了以上的一些运算符之外,Python还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组。

判断子元素是否在原字符串(字典,列表,集合)中:
例如:
#print('喜欢' in 'dkfljadklf喜欢hfjdkas')
#print('a' in 'bcvd')
#print('y' not in 'ofkjdslaf')
Python运算符优先级
以下表格列出了从最高到最低优先级的所有运算符:
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 'AND' |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
身份运算符
身份运算符用于比较两个对象的存储单元

# 判断两个标识符是不是引用同一个对象或不同对象,返回布尔值 a = "烟雨江南" b =a print(b is a) # 类似id(b) = id(a) print(a is b) # 类似id(a) = id(b
三、编码初识
ASCII码的由来:
在计算机中,所有的数据在存储和运算时都要使用二进制数表示(因为计算机用高电平和低电平分别表示1和0),例如,像a、b、c、d这样的52个字母(包括大写)以及0、1等数字还有一些常用的符号(例如*、#、@等)在计算机中存储时也要使用二进制数来表示,而具体用哪些二进制数字表示哪个符号,当然每个人都可以约定自己的一套(这就叫编码),而大家如果要想互相通信而不造成混乱,那么大家就必须使用相同的编码规则,于是美国有关的标准化组织就出台了ASCII编码,统一规定了上述常用符号用哪些二进制数来表示。
ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。
python2解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),而python3对内容进行编码的默认为utf-8。
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。

ASCII标准表:
|
Bin
(二进制)
|
Oct
(八进制)
|
Dec
(十进制)
|
Hex
(十六进制)
|
缩写/字符
|
解释
|
|
0000 0000
|
00
|
0
|
0x00
|
NUL(null)
|
空字符
|
|
0000 0001
|
01
|
1
|
0x01
|
SOH(start of headline)
|
标题开始
|
|
0000 0010
|
02
|
2
|
0x02
|
STX (start of text)
|
正文开始
|
|
0000 0011
|
03
|
3
|
0x03
|
ETX (end of text)
|
正文结束
|
|
0000 0100
|
04
|
4
|
0x04
|
EOT (end of transmission)
|
传输结束
|
|
0000 0101
|
05
|
5
|
0x05
|
ENQ (enquiry)
|
请求
|
|
0000 0110
|
06
|
6
|
0x06
|
ACK (acknowledge)
|
收到通知
|
|
0000 0111
|
07
|
7
|
0x07
|
BEL (bell)
|
响铃
|
|
0000 1000
|
010
|
8
|
0x08
|
BS (backspace)
|
退格
|
|
0000 1001
|
011
|
9
|
0x09
|
HT (horizontal tab)
|
水平制表符
|
|
0000 1010
|
012
|
10
|
0x0A
|
LF (NL line feed, new line)
|
换行键
|
|
0000 1011
|
013
|
11
|
0x0B
|
VT (vertical tab)
|
垂直制表符
|
|
0000 1100
|
014
|
12
|
0x0C
|
FF (NP form feed, new page)
|
换页键
|
|
0000 1101
|
015
|
13
|
0x0D
|
CR (carriage return)
|
回车键
|
|
0000 1110
|
016
|
14
|
0x0E
|
SO (shift out)
|
不用切换
|
|
0000 1111
|
017
|
15
|
0x0F
|
SI (shift in)
|
启用切换
|
|
0001 0000
|
020
|
16
|
0x10
|
DLE (data link escape)
|
数据链路转义
|
|
0001 0001
|
021
|
17
|
0x11
|
DC1 (device control 1)
|
设备控制1
|
|
0001 0010
|
022
|
18
|
0x12
|
DC2 (device control 2)
|
设备控制2
|
|
0001 0011
|
023
|
19
|
0x13
|
DC3 (device control 3)
|
设备控制3
|
|
0001 0100
|
024
|
20
|
0x14
|
DC4 (device control 4)
|
设备控制4
|
|
0001 0101
|
025
|
21
|
0x15
|
NAK (negative acknowledge)
|
拒绝接收
|
|
0001 0110
|
026
|
22
|
0x16
|
SYN (synchronous idle)
|
同步空闲
|
|
0001 0111
|
027
|
23
|
0x17
|
ETB (end of trans. block)
|
结束传输块
|
|
0001 1000
|
030
|
24
|
0x18
|
CAN (cancel)
|
取消
|
|
0001 1001
|
031
|
25
|
0x19
|
EM (end of medium)
|
媒介结束
|
|
0001 1010
|
032
|
26
|
0x1A
|
SUB (substitute)
|
代替
|
|
0001 1011
|
033
|
27
|
0x1B
|
ESC (escape)
|
换码(溢出)
|
|
0001 1100
|
034
|
28
|
0x1C
|
FS (file separator)
|
文件分隔符
|
|
0001 1101
|
035
|
29
|
0x1D
|
GS (group separator)
|
分组符
|
|
0001 1110
|
036
|
30
|
0x1E
|
RS (record separator)
|
记录分隔符
|
|
0001 1111
|
037
|
31
|
0x1F
|
US (unit separator)
|
单元分隔符
|
|
0010 0000
|
040
|
32
|
0x20
|
(space)
|
空格
|
|
0010 0001
|
041
|
33
|
0x21
|
!
|
叹号 |
|
0010 0010
|
042
|
34
|
0x22
|
"
|
双引号 |
|
0010 0011
|
043
|
35
|
0x23
|
#
|
井号 |
|
0010 0100
|
044
|
36
|
0x24
|
$
|
美元符 |
|
0010 0101
|
045
|
37
|
0x25
|
%
|
百分号 |
|
0010 0110
|
046
|
38
|
0x26
|
&
|
和号 |
|
0010 0111
|
047
|
39
|
0x27
|
'
|
闭单引号 |
|
0010 1000
|
050
|
40
|
0x28
|
(
|
开括号
|
|
0010 1001
|
051
|
41
|
0x29
|
)
|
闭括号
|
|
0010 1010
|
052
|
42
|
0x2A
|
*
|
星号 |
|
0010 1011
|
053
|
43
|
0x2B
|
+
|
加号 |
|
0010 1100
|
054
|
44
|
0x2C
|
,
|
逗号 |
|
0010 1101
|
055
|
45
|
0x2D
|
-
|
减号/破折号 |
|
0010 1110
|
056
|
46
|
0x2E
|
.
|
句号 |
|
0010 1111
|
057
|
47
|
0x2F
|
/
|
斜杠 |
|
0011 0000
|
060
|
48
|
0x30
|
0
|
数字0 |
|
0011 0001
|
061
|
49
|
0x31
|
1
|
数字1 |
|
0011 0010
|
062
|
50
|
0x32
|
2
|
数字2 |
|
0011 0011
|
063
|
51
|
0x33
|
3
|
数字3 |
|
0011 0100
|
064
|
52
|
0x34
|
4
|
数字4 |
|
0011 0101
|
065
|
53
|
0x35
|
5
|
数字5 |
|
0011 0110
|
066
|
54
|
0x36
|
6
|
数字6 |
|
0011 0111
|
067
|
55
|
0x37
|
7
|
数字7 |
|
0011 1000
|
070
|
56
|
0x38
|
8
|
数字8 |
|
0011 1001
|
071
|
57
|
0x39
|
9
|
数字9 |
|
0011 1010
|
072
|
58
|
0x3A
|
:
|
冒号 |
|
0011 1011
|
073
|
59
|
0x3B
|
;
|
分号 |
|
0011 1100
|
074
|
60
|
0x3C
|
<
|
小于 |
|
0011 1101
|
075
|
61
|
0x3D
|
=
|
等号 |
|
0011 1110
|
076
|
62
|
0x3E
|
>
|
大于 |
|
0011 1111
|
077
|
63
|
0x3F
|
?
|
问号 |
|
0100 0000
|
0100
|
64
|
0x40
|
@
|
电子邮件符号 |
|
0100 0001
|
0101
|
65
|
0x41
|
A
|
大写字母A |
|
0100 0010
|
0102
|
66
|
0x42
|
B
|
大写字母B |
|
0100 0011
|
0103
|
67
|
0x43
|
C
|
大写字母C |
|
0100 0100
|
0104
|
68
|
0x44
|
D
|
大写字母D |
|
0100 0101
|
0105
|
69
|
0x45
|
E
|
大写字母E |
|
0100 0110
|
0106
|
70
|
0x46
|
F
|
大写字母F |
|
0100 0111
|
0107
|
71
|
0x47
|
G
|
大写字母G |
|
0100 1000
|
0110
|
72
|
0x48
|
H
|
大写字母H |
|
0100 1001
|
0111
|
73
|
0x49
|
I
|
大写字母I |
|
01001010
|
0112
|
74
|
0x4A
|
J
|
大写字母J |
|
0100 1011
|
0113
|
75
|
0x4B
|
K
|
大写字母K |
|
0100 1100
|
0114
|
76
|
0x4C
|
L
|
大写字母L |
|
0100 1101
|
0115
|
77
|
0x4D
|
M
|
大写字母M |
|
0100 1110
|
0116
|
78
|
0x4E
|
N
|
大写字母N |
|
0100 1111
|
0117
|
79
|
0x4F
|
O
|
大写字母O |
|
0101 0000
|
0120
|
80
|
0x50
|
P
|
大写字母P |
|
0101 0001
|
0121
|
81
|
0x51
|
Q
|
大写字母Q |
|
0101 0010
|
0122
|
82
|
0x52
|
R
|
大写字母R |
|
0101 0011
|
0123
|
83
|
0x53
|
S
|
大写字母S |
|
0101 0100
|
0124
|
84
|
0x54
|
T
|
大写字母T |
|
0101 0101
|
0125
|
85
|
0x55
|
U
|
大写字母U |
|
0101 0110
|
0126
|
86
|
0x56
|
V
|
大写字母V |
|
0101 0111
|
0127
|
87
|
0x57
|
W
|
大写字母W |
|
0101 1000
|
0130
|
88
|
0x58
|
X
|
大写字母X |
|
0101 1001
|
0131
|
89
|
0x59
|
Y
|
大写字母Y |
|
0101 1010
|
0132
|
90
|
0x5A
|
Z
|
大写字母Z |
|
0101 1011
|
0133
|
91
|
0x5B
|
[
|
开方括号 |
|
0101 1100
|
0134
|
92
|
0x5C
|
反斜杠 | |
|
0101 1101
|
0135
|
93
|
0x5D
|
]
|
闭方括号 |
|
0101 1110
|
0136
|
94
|
0x5E
|
^
|
脱字符 |
|
0101 1111
|
0137
|
95
|
0x5F
|
_
|
下划线 |
|
0110 0000
|
0140
|
96
|
0x60
|
`
|
开单引号 |
|
0110 0001
|
0141
|
97
|
0x61
|
a
|
小写字母a |
|
0110 0010
|
0142
|
98
|
0x62
|
b
|
小写字母b |
|
0110 0011
|
0143
|
99
|
0x63
|
c
|
小写字母c |
|
0110 0100
|
0144
|
100
|
0x64
|
d
|
小写字母d |
|
0110 0101
|
0145
|
101
|
0x65
|
e
|
小写字母e |
|
0110 0110
|
0146
|
102
|
0x66
|
f
|
小写字母f |
|
0110 0111
|
0147
|
103
|
0x67
|
g
|
小写字母g |
|
0110 1000
|
0150
|
104
|
0x68
|
h
|
小写字母h |
|
0110 1001
|
0151
|
105
|
0x69
|
i
|
小写字母i |
|
0110 1010
|
0152
|
106
|
0x6A
|
j
|
小写字母j |
|
0110 1011
|
0153
|
107
|
0x6B
|
k
|
小写字母k |
|
0110 1100
|
0154
|
108
|
0x6C
|
l
|
小写字母l |
|
0110 1101
|
0155
|
109
|
0x6D
|
m
|
小写字母m |
|
0110 1110
|
0156
|
110
|
0x6E
|
n
|
小写字母n |
|
0110 1111
|
0157
|
111
|
0x6F
|
o
|
小写字母o |
|
0111 0000
|
0160
|
112
|
0x70
|
p
|
小写字母p |
|
0111 0001
|
0161
|
113
|
0x71
|
q
|
小写字母q |
|
0111 0010
|
0162
|
114
|
0x72
|
r
|
小写字母r |
|
0111 0011
|
0163
|
115
|
0x73
|
s
|
小写字母s |
|
0111 0100
|
0164
|
116
|
0x74
|
t
|
小写字母t |
|
0111 0101
|
0165
|
117
|
0x75
|
u
|
小写字母u |
|
0111 0110
|
0166
|
118
|
0x76
|
v
|
小写字母v |
|
0111 0111
|
0167
|
119
|
0x77
|
w
|
小写字母w |
|
0111 1000
|
0170
|
120
|
0x78
|
x
|
小写字母x |
|
0111 1001
|
0171
|
121
|
0x79
|
y
|
小写字母y |
|
0111 1010
|
0172
|
122
|
0x7A
|
z
|
小写字母z |
|
0111 1011
|
0173
|
123
|
0x7B
|
{
|
开花括号 |
|
0111 1100
|
0174
|
124
|
0x7C
|
|
|
垂线 |
|
0111 1101
|
0175
|
125
|
0x7D
|
}
|
闭花括号 |
|
0111 1110
|
0176
|
126
|
0x7E
|
~
|
波浪号 |
|
0111 1111
|
0177
|
127
|
0x7F
|
DEL (delete)
|
删除
|
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果是如下代码的话:
报错:ascii码无法表示中文
|
1
2
3
4
5
6
7
8
9
10
|
#!/usr/bin/env python print "你好,世界"改正:应该显示的告诉python解释器,用什么编码来执行源代码,即:#!/usr/bin/env python# -*- coding: utf-8 -*- print "你好,世界" |
编码总结
'''
----编码----
计算机的最小存储单位bit,8bit=1字节(bytes)
ASCII:8bit--->1bytes
unicode:32bit---->4bytes 无论表示中文英文都是4个字节
GBK:16bit---->2bytes 表示英文用1个字节
utf-8: 表示英文用一个字节
英文:8bit--->1bytes
欧洲:16bit---->2bytes
中国:24bit---->3bytes
'''
二进制:
比如:
一个空格对应的数字是0 , 翻译成二进制就是0(注意字符'o'和整数0是不同的)
一个对勾√对应的而数字是251, 翻译成二进制就是11111011
提问:假如我们要打印两个空格一个对勾 ,写作二进制就是应该是0011111011,但是问题来了,我们怎么知道从哪到哪是一个字符呢?
所以把所有的二进制数都转换成8位的,不足的用0替换,这样一来刚刚的两个空格一个对勾九写作00000000-00000000-11111011,读取的时候只要每次读取8个字符就能知道每个字符的二进制了。
在这里每一位0或者1所占的空间单位为bit(比特),是计算机中最小的表示单位,每8个bit组成一个字符
bit 位 计算机中最小的表示单位
8bit = 1bytes 字节 最小的存储单位 ,1bytes 缩写为 1B
1K = 1024B
1MB = 1024KB
1GB = 1024MB
1TB = 1024GB
......
作业:
1、 利⽤while语句写出猜⼤⼩的游戏: 设定⼀个理想数字⽐如:66,让⽤户输⼊数字,如果⽐66⼤,则显示猜测的结果⼤ 了;如果⽐66⼩,则显示猜测的结果⼩了;只有等于66,显示猜测结果正确,然后退出 循环。
2、 给⽤户三次猜测机会,如果三次之内猜测对了,则显示猜测正确,退出循环,如果 三次之内没有猜测正确,则⾃动退出循环,并显示‘太笨了你....’。
3、 使⽤while循环输出 1 2 3 4 5 6 8 9 10
4、 求1-100的所有数的和
5、 输出 1-100 内的所有奇数
6、 输出 1-100 内的所有偶数
7、 求1-2+3-4+5 ... 99的所有数的和
8、 ⽤户登陆(三次输错机会)且每次输错误时显示剩余错误次数(提示:使⽤字符串格 式化)
9、用户输入一个数,判断这个数是否是质数!(注意质数只能被1和他本身整除,2是唯一一个偶数的质数)


从第二题开始: ran = 66 func = 1 while func < 4: num = int(input('请输入:')) if num == ran: print('ok') break elif func == 3: print('你太笨了') break elif num > ran: print('大了') elif num < ran: print('小了') func += 1 --------------------------- msg = 0 while msg < 10: msg += 1 if msg == 7: continue print(msg) --------------------------- x = 1 y = 0 while x < 101: y += x x += 1 print(y) --------------------------- a = 1 while a < 101: print(a) a += 2 --------------------------- a = 2 while a < 101: print(a) a += 2 --------------------------- sum = 0 count = 1 while count < 100: if count %2 ==0: sum -= count else: sum += count count = count + 1 print(sum) -------------------------- # 升级版登录验证一 USERNAME = 'seven' PASSWD= '123' flag = 1 while flag < 4: username = input('请输入用户名:') passwd = input('请输入密码:') if username == USERNAME and passwd: print('登录成功,欢迎您进入京东商城!') break else: print('用户名或密码错误,请重新输入!剩余%s次'%(3-flag)) flag += 1 # 升级版登录验证二 USERNAME = ['seven','alex'] PASSWD= '123' flag = 1 while flag < 4: username = input('请输入用户名:') passwd = input('请输入密码:') if username in USERNAME and passwd == PASSWD: print('登录成功,欢迎您进入京东商城!') break else: print('用户名或密码错误,请重新输入!剩余%s次'%(3-flag)) flag += 1 -------------------------------------------------------------------- msg = int(input('请输入一个数字:')) if msg <= 1: print('这不是质数!') elif msg == 2: print('这是质数!') else: i = 2 while i < msg: if msg % i == 0: print('这不是质数!') break i += 1 #例如输入21,计算机不知道21能不能被21之前的所有数字整除,所以需要用21将21之前的所有数字都除一遍 else: print('这是质数') 答案