一、地址
GITH地址:https://github.com/haveadate/WordCount.git
结对伙伴的作业地址:https://www.cnblogs.com/haveadate/p/10652689.html
二、结对过程
在结对之后,选定了两方都有空的时间出来讨论,现制定了PSP表,然后根据各自水平,分配任务。各自的任务完成过后,先自审,再交由对方复审,然后汇总,封装成dll文件,进行单元测试和效能分析,并且改进代码,最后撰写博客。

三、PSP表
|
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
880 |
1395 |
|
· Estimate |
· 估计这个任务需要多少时间 |
880 |
1395 |
|
Development |
开发 |
760 |
1270 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
40 |
50 |
|
· Design Spec |
· 生成设计文档 |
30 |
35 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
50 |
60 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
20 |
15 |
|
· Design |
· 具体设计 |
30 |
50 |
|
· Coding |
· 具体编码 |
400 |
900 |
|
· Code Review |
· 代码复审 |
60 |
40 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
100 |
120 |
|
Reporting |
报告 |
120 |
125 |
|
· Test Report |
· 测试报告 |
60 |
60 |
|
· Size Measurement |
· 计算工作量 |
30 |
40 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
30 |
25 |
|
合计 |
880 |
1395 |
四、思路
看到这个题目时,觉得很难,但是在和结对伙伴讨论之后,发现还是可以解决。首先就是读取文件,然后把它存进一个字符串里面,就可以进行统计字符个数,然后用字符串的Split方法分割成字符串数组,通过循环对每个字符串数组中的元素进行判断,针对这个判断我们又重新制定了一个方法,用于专门判断它是否是一个单词,其思路为再将字符串转化为字符数组,如果它符合条件,就count进去。还查找了关于命令行参数的资料。
五、设计实现过程
有一个对文件的操作类 class fileOperate,里面有统计字符个数方法charNumber()、统计单词个数方法wordNumber()、统计文件行数方法lineNumber()、统计单词频率方法wordTimes()。展示一下结对方写的判断一字符串是否是一个单词的isWords(string word)方法、获取文件中的频率最高的n个词的wordTimes(int n)方法、获取文件中指定词组的wordGroup(int len)方法的流程图:
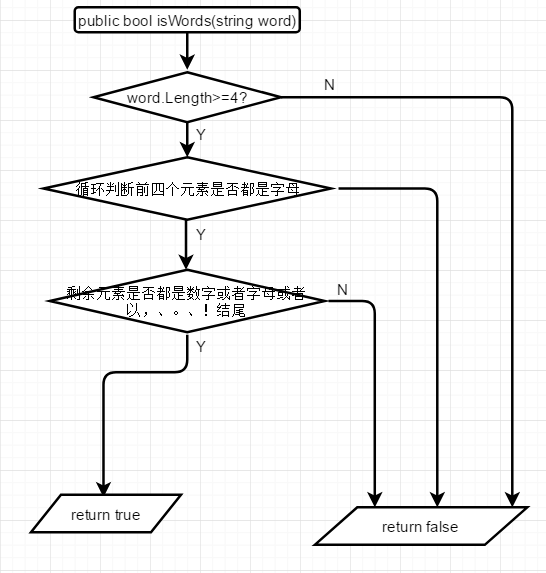
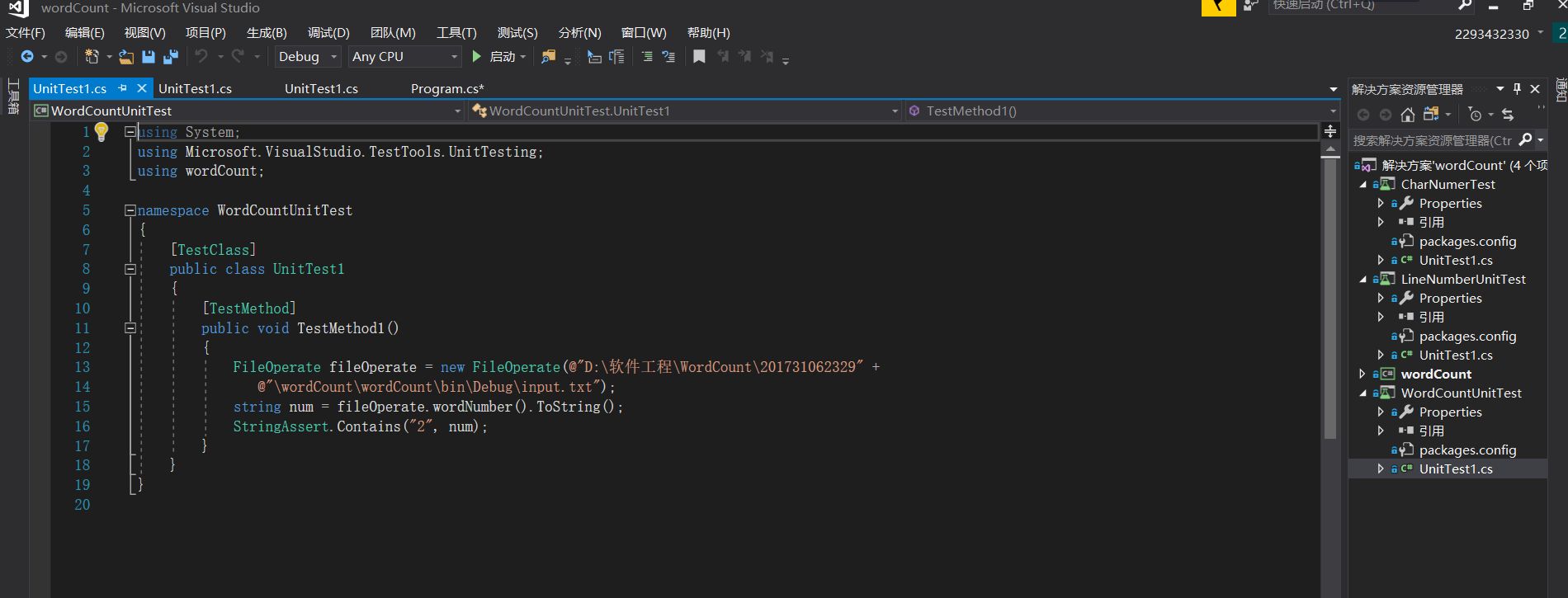
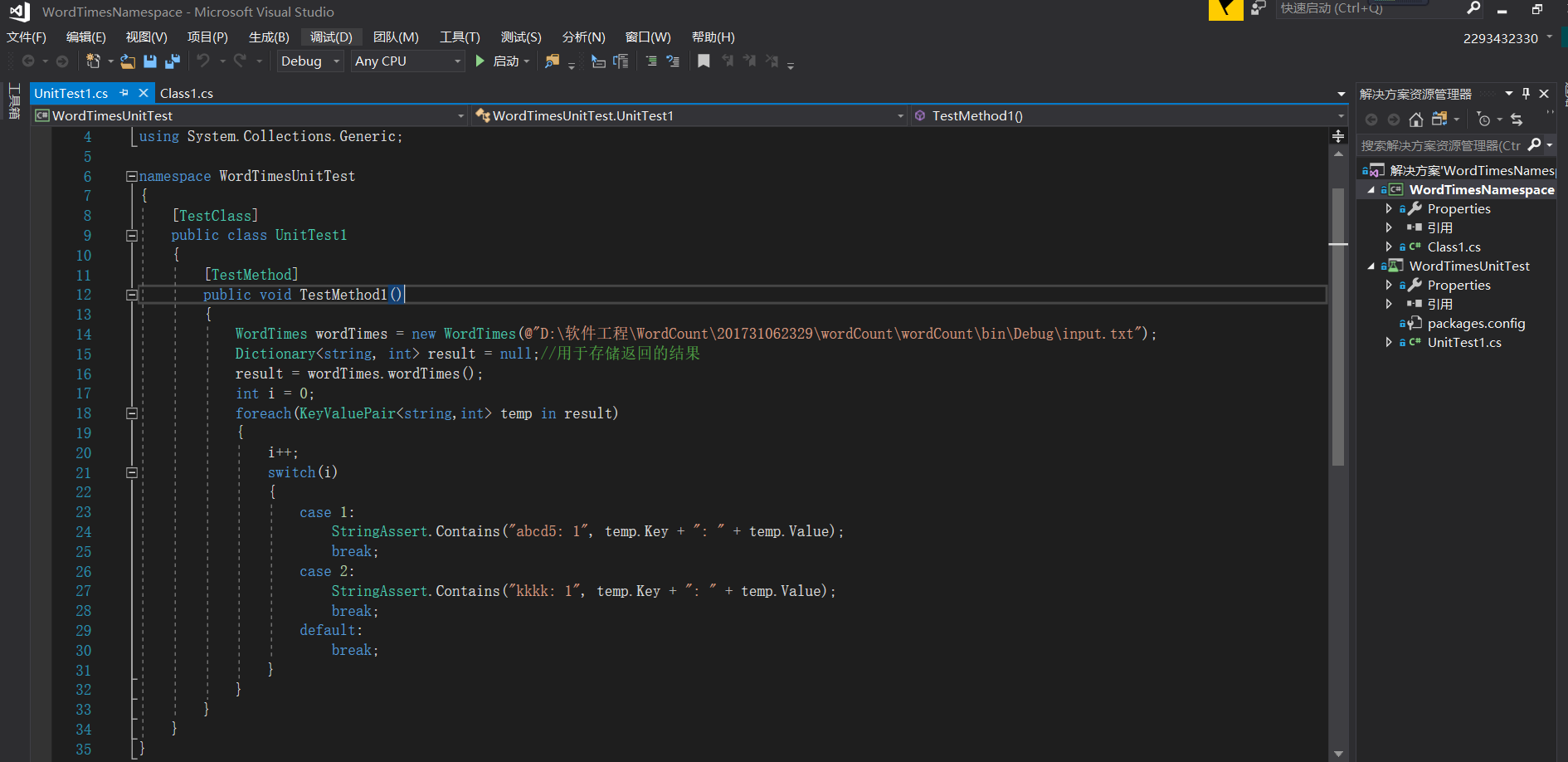
由于此次的方法都是有返回值的,所以在单元测试部分,都是创建一个FileOperate的对象,然后通过调用相应的方法,然后使用断言判断进行单元测试。
六、代码规范
1. 命名规则:使用驼峰命名法。给类或函数或字段命名,使用具有相应中文意思的英文单词。
2. 分行:不把多条语句放在一行上,不把多个变量定义在一行上。
3. 断行与空白的{}行:”{“、”}”单独在一行。
4. 注释:在类或方法的上面使用文档注释,在方法中使用单行注释。
七、代码复审
因为本人负责的部分比较简单,所以没有什么太大的问题。
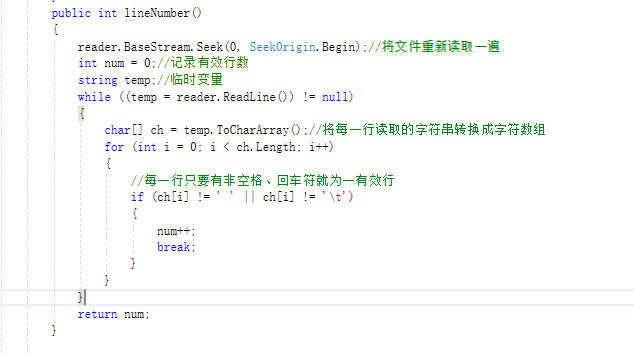
lineNumber()方法原来用的File类下的一个ReadAllLInes()方法,会把空白行也计算进去,所以在结对方的指导下,改成了下面的代码。
八、代码说明

读取文件,然后判断是否为空,用字符串来存,可以直接读取长度。
九、单元测试
大部分为结对方完成的测试 

十、说明
该部分由结对方完成
基本功能的实现:

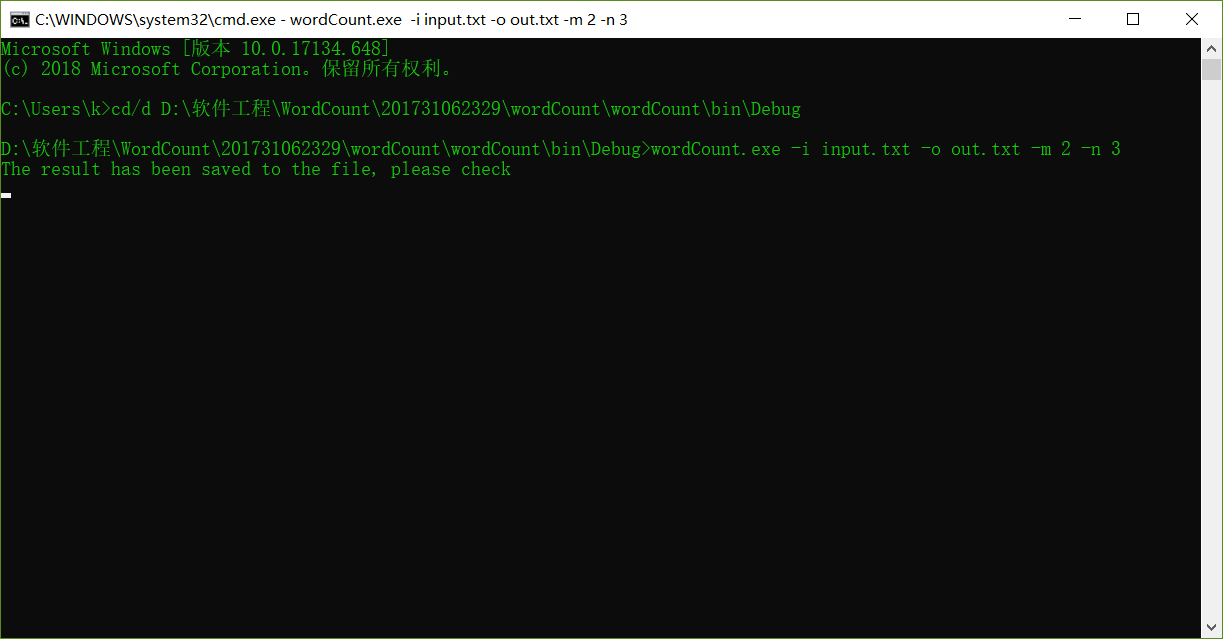

健壮性:

基本实现了错误提示功能;
新添功能: 仿照像cmd、matlab等等中的help命令:

获得帮助路径不唯一:
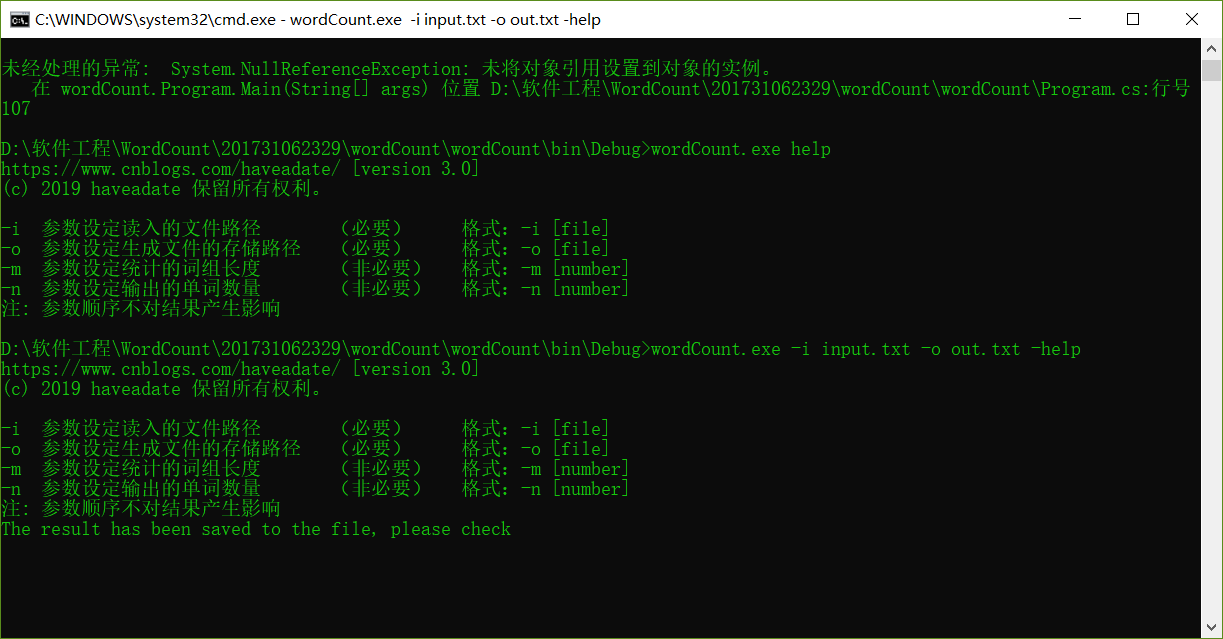
十一、总结
此次结对项目令自己深刻认识到了与同学之间的差距,看来平时还是要多敲代码多思考。在本次作业中,复习了一下类库知识,如何封装,并且复习了一下上次作业的git push 等操作。还学习了新的知识,命令行参数。在同学的身上也看到了很多值得我学习的地方,这次的作业令我收获颇多。还要努力提高自己的水平,减轻合作伙伴的压力。