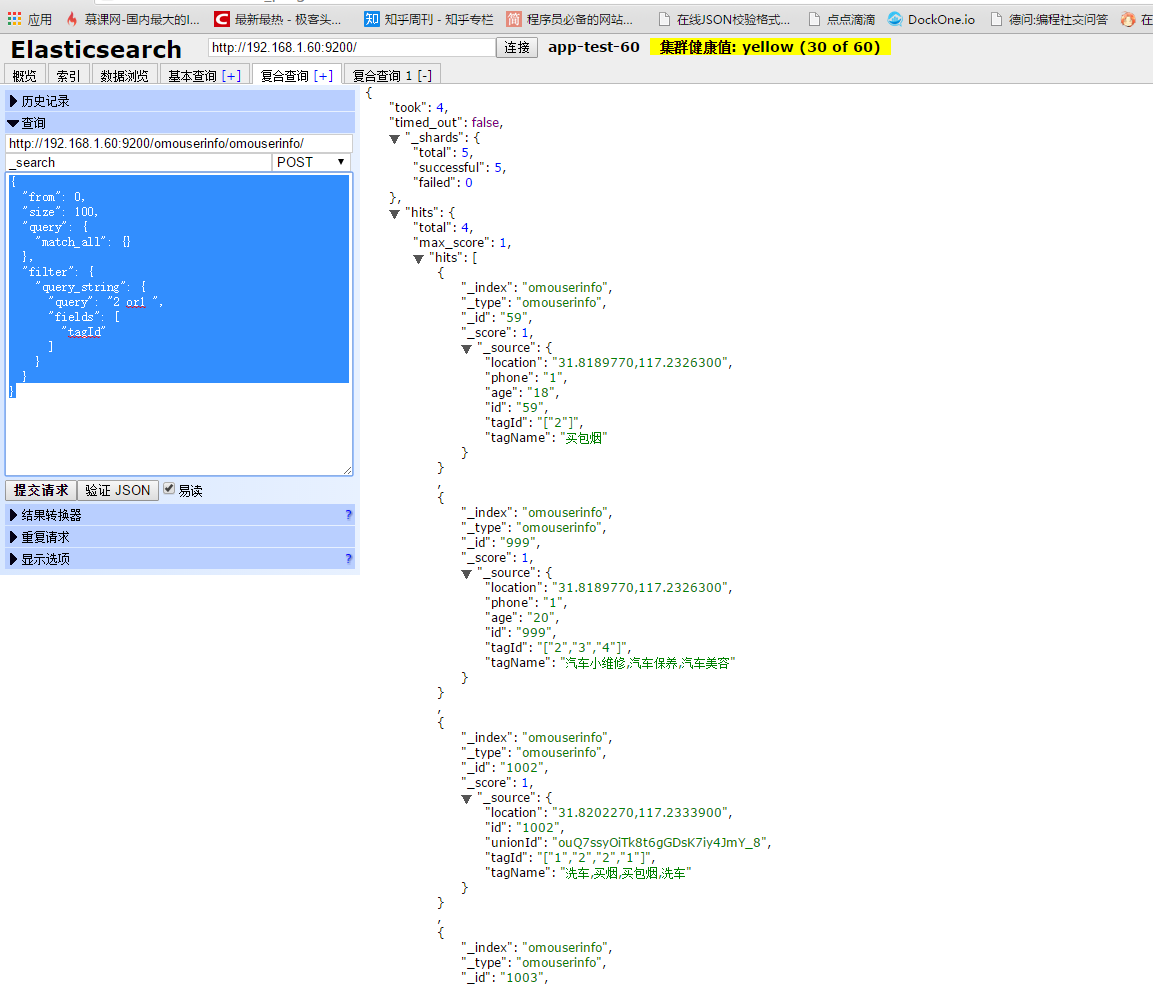
对于字符串在搜索匹配的时候,字符串是数字的话需要匹配的是精准匹配,如果是部分匹配字符串的话,需要进行处理,把数字型字符串作为一个字符中的数组表示插入之后显示如下:
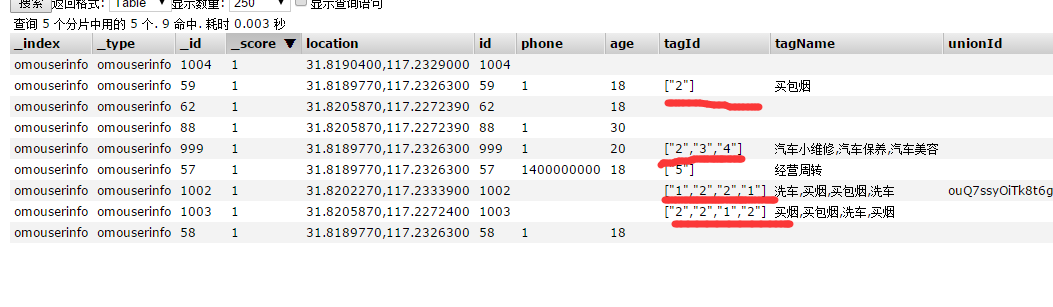
如果插入之后显示如画线部分的话,则表示精准匹配
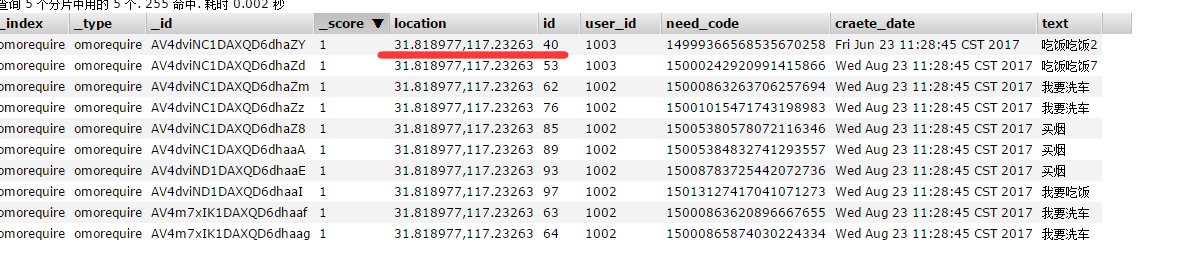
在用clien的java api插入的时候:
String json=null;
if (req.getTagId() != null) {
String[] test = req.getTagId().split(",");
json = JSON.toJSONString(test);
System.out.println(json);
}else {
json = "{"+""location":"+"""+req.getLatitude()+","+req.getLongitude()+"""+","
+""id":"+"""+req.getId()+"""+","+""union_id":"+"""+req.getUnionId()+"""+","
+""tag_id":"+"""+req.getTagId()+"""+","+""tag_name":"+"""+req.getTagName()+"""+","
+""nickname":"+"""+req.getNickname()+"""+","+""phone":"+"""+req.getPhone()+"""+","
+""name":"+"""+req.getName()+"""+","+""age":"+"""+req.getAge()+"""+","
+""code":"+"""+req.getCode()+"""+","+""gender":"+"""+req.getGender()+"""+","
+""province":"+"""+req.getProvince()+"""+","+""city":"+"""+req.getCity()+"""+","
+""coountry":"+"""+req.getCountry()+"""+","+""avatarUrl":"+"""+req.getAvatarUrl()+"""+","
+""app_code":"+"""+req.getAppCode()+"""+"}";
System.out.println(json);
}
通过这种插入方式,默认的是json,在json验证的时候显示的json,而在table格式下不能显示:因此通过类的字符形式插入在显示table格式:
public boolean insertIndexUserDoc(String indexname, String type,List<UserEntity> list)
throws ApplicationException, Exception {
// TODO Auto-generated method stub
String location=null;
JestClient jestHttpClient = Connection.getClient();
JestResult jr = null;
try {
// Bulk.Builder bulk = new Bulk.Builder().defaultIndex(indexname)
// .defaultType(type);
for(UserEntity req:list){
UserEntity user = new UserEntity();
user.setId(req.getId());
user.setUnionId(req.getUnionId());
user.setTagName(req.getTagName());
user.setLocation(req.getLatitude().toString()+","+req.getLongitude().toString());
user.setAge(req.getAge());
user.setPhone(req.getPhone());
user.setCode(req.getCode());
user.setGender(req.getGender());
user.setProvince(req.getProvince());
user.setCity(req.getCity());
user.setCountry(req.getCountry());
user.setAppCode(req.getAppCode());
user.setAvatarUrl(req.getAvatarUrl());
user.setNickname(req.getNickname());
if (req.getTagId()!=null){
String[] mids=req.getTagId().split(",");
user.setTagId(JSON.toJSONString(mids));;
}
jr=jestHttpClient.execute(new Index.Builder(user)
.index("omouserinfo").id(user.getId())
.type("omouserinfo").build());
boolean flag = jr.isSucceeded();
System.out.println(flag);
}
return true;
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
return false;
}
}
其中, jr=jestHttpClient.execute(new Index.Builder(user)
.index("omouserinfo").id(user.getId())
.type("omouserinfo").build());这个设置的id,如果不设置,在批量插入处理的时候,id第一次自动分配,后面容易冲突
第一段
代码如果批量插入时候可以不设置id,由于id可以在一次之后自增id,不需要设置id;因此,在批量单条处理的时候需要加id。执行之后如下:
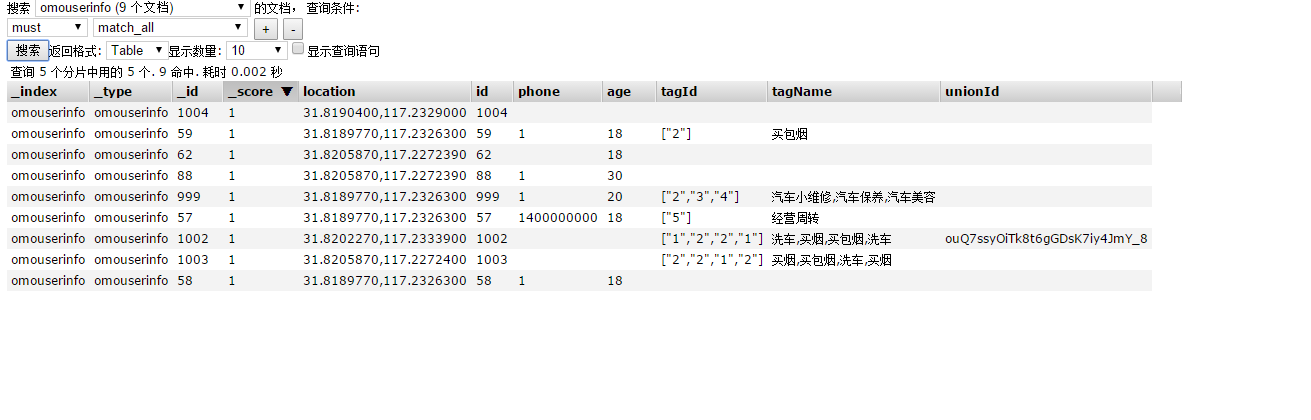
在查询的时候实现精准匹配:

做查询的时候需要对字符串进行处理如下:
ublic static void main(String[] args) {
int from = 0, size = 100;
String serviceTypeIds = "823,770,1182,1431,1432";
System.out.println(serviceTypeIds);
StringBuilder stringBuilder = new StringBuilder("{")
.append(""from":")
.append(from)
.append(",")
.append(""size":")
.append(size)
.append(",")
.append(""query" : {")
.append(""match_all" : {}")
.append("},")
.append(""filter" : {"and" : [")
.append(org.apache.commons.lang3.StringUtils
.isBlank(serviceTypeIds) ? "" : (serviceTypeIds
.contains(",") ? "{"query_string" : {"query" : ""
+ StringUtils.replace(serviceTypeIds, ",", " or ")
+ "","fields":["tagId"]}}"
: "{"term" : {"tagId" : " + serviceTypeIds
+ "}},"));
System.out.println(stringBuilder);
}
花了一上午的时间,做出来,小小激动一下啊!
打印出来的json如下:
{
"from": 0,
"size": 100,
"query": {
"match_all": {}
},
"filter": {
"query_string": {
"query": "2 or1 ",
"fields": [
"tagId"
]
}
}
}
查询结果如下: