转自:http://blog.beginman.cn/blog/133/
协程概念
1.并发编程的种类:多进程,多线程,异步,协程
2.进程,线程,协程的概念区别:
进程:拥有自己独立的堆和栈,既不共享堆也不共享栈,进程由操作系统调度。
线程:线程拥有自己独立的栈和共享的堆,共享堆,不共享栈,线程亦由操作系统调度(标准线程是的)。
协程:协程和线程一样共享堆,不共享栈,协程由程序员在协程的代码里显式调度
3.协程:
协程可以认为是一种用户态的线程,与系统提供的线程不同点是,它需要主动让出CPU时间,而不是由系统进行调度,即控制权在程序员手上。
4.进程,线程,协程在python中的表现
关于进程,python有multiprocessing模块进行处理;关于线程,python的Thread和Threading处理;关于异步,有各种python框架如Tornado等调用linux下的select,poll,epoll等异步实现;关于协程,由yield来实现。
5.协程与yield
在廖雪峰的python博客中学习总结协程如下:
1).子程序调用通过栈实现,一个线程执行一个子程序,有明确的执行顺序,而协程不同于此,协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。注意的一点是:如A,B两个子程序, A执行过程中可以去执行B,并不是调用B,B可以中断(挂起)转而回到A.
所以可以看到执行过程在A,B两个子程序中切换,但是A并没有调用B,B的中断可以通过yield来保存,A,B的执行过程像多线程,但是协程的特点在于一个线程执行。
2).协程的优势:
最大的优势就是协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
第二大优势就是不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
因为协程是一个线程执行,那怎么利用多核CPU呢?最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。
下面通过多线程的生产者消费者与协程的生产者消费者实例进行演示:
# 多线程# coding=utf-8from threading import Threadfrom threading import Conditionimport timeimport random#为了达到理解效果,这里没有使用简便的Queuequeue = []condition = Condition()MAX_LENGTH = 20#代码实例:http://blog.jobbole.com/52412/#生产者的工作是产生一块数据,放到buffer中,如此循环。#与此同时,消费者在消耗这些数据(例如从buffer中把它们移除),每次一块。#这里的关键词是“同时”。所以生产者和消费者是并发运行的,我们需要对生产者和消费者做线程分离。#这个为描述了两个共享固定大小缓冲队列的进程,即生产者和消费者。class ProducerThread(Thread):def run(self):nums = range(5)global queuewhile True:num = random.choice(nums)condition.acquire() # 锁定以生成数据if len(queue) == MAX_LENGTH:print u'队列已满,等待消费中...'condition.wait() # 线程等待queue.append(num) # 往队列中生成数据print "Produced", numcondition.notify() # 通知线程等待的消费者消费数据condition.release() # 释放线程锁time.sleep(random.random())class ConsumerThread(Thread):def run(self):global queuewhile True:condition.acquire() #线程锁if not queue:print u"队列为空,等待生产者生成数据...."condition.wait() # 线程等待num = queue.pop(0) # 消费数据print "Consumed", numcondition.notify() # 通知线程等待的生产者继续生成数据(生产者线程等待条件是队列已满)condition.release() # 释放线程锁time.sleep(2) #执行时间长点,让生产者生成更多数据来测试ProducerThread().start()ConsumerThread().start()
传统的生产者-消费者模型是一个线程写消息,一个线程取消息,通过锁机制控制队列和等待,但一不小心就可能死锁。
下面改用协程的方式:
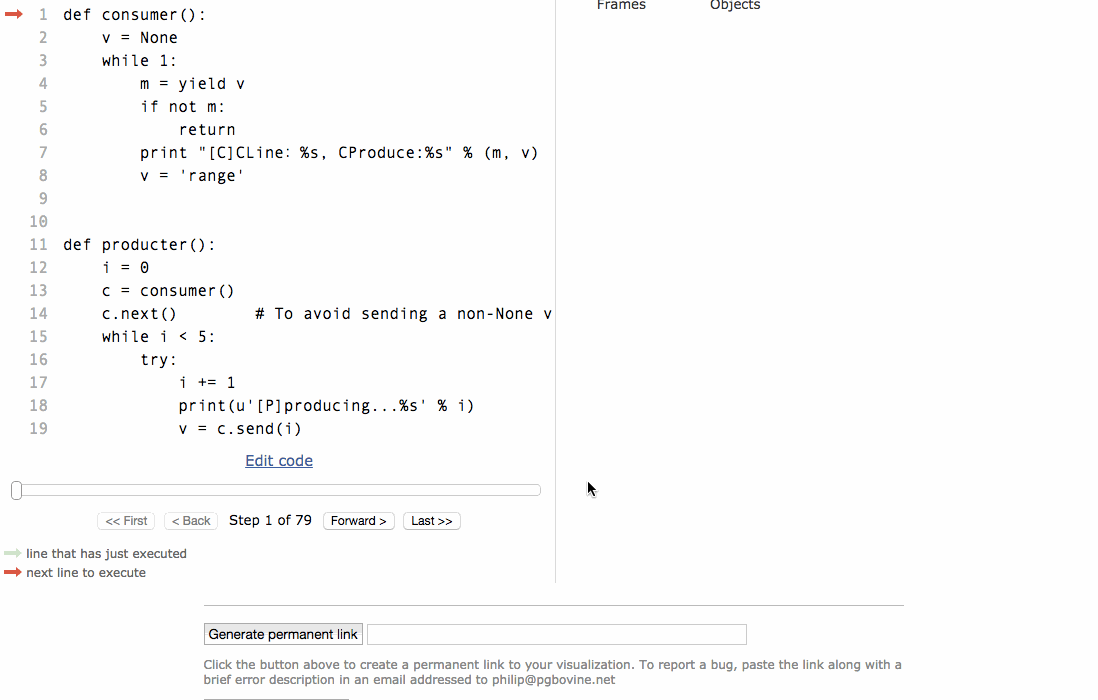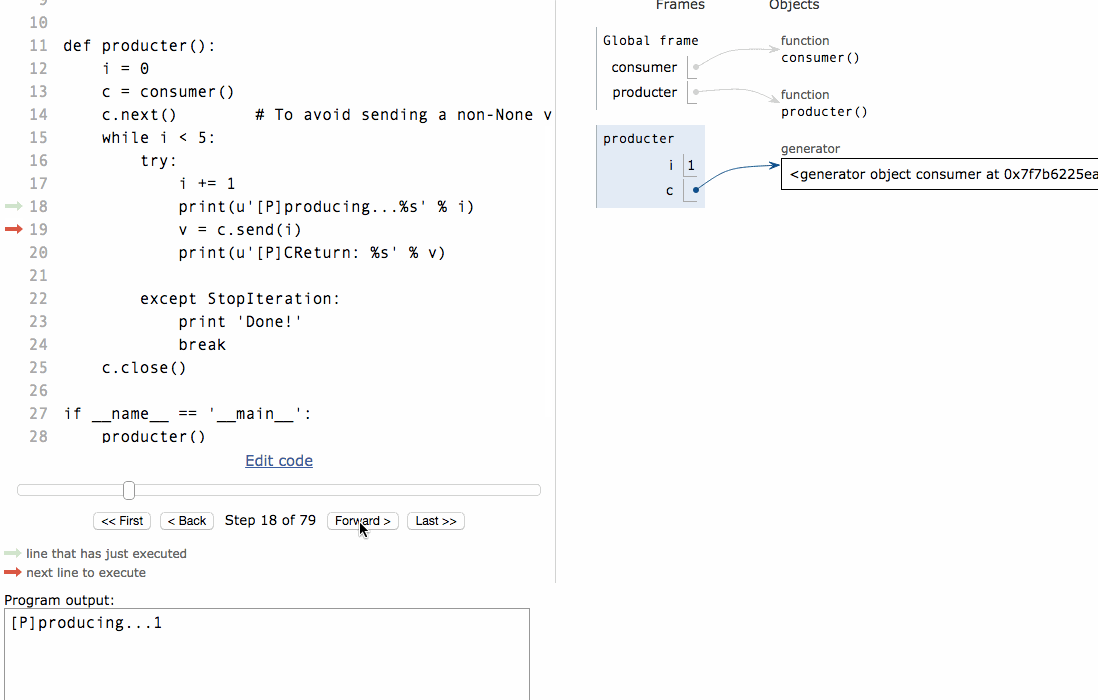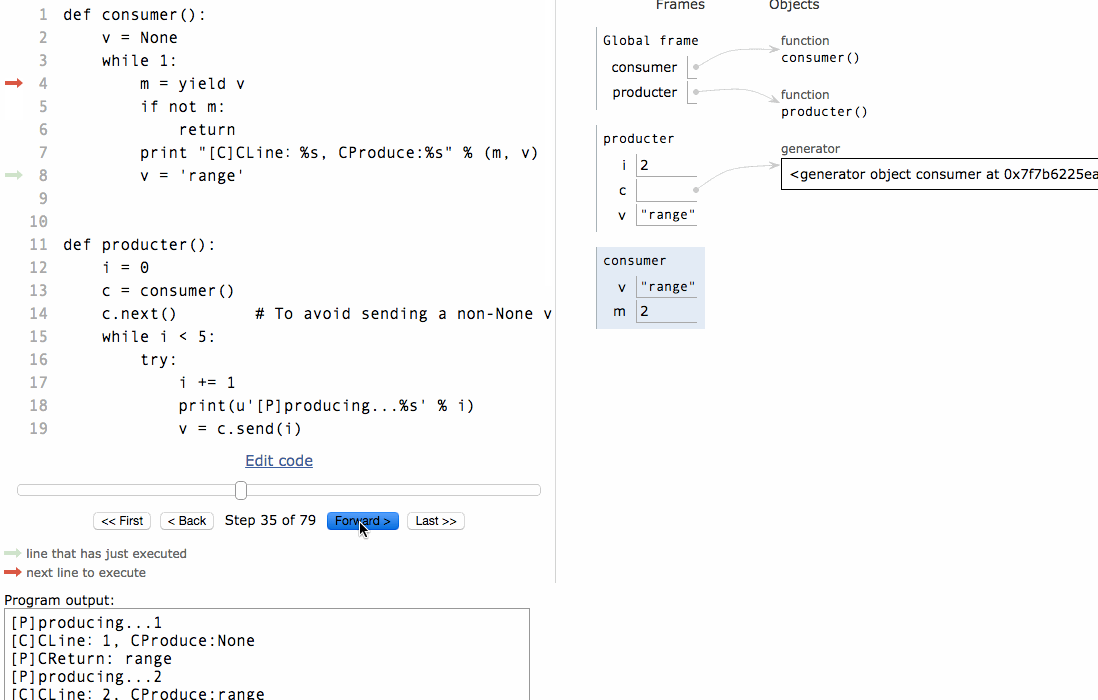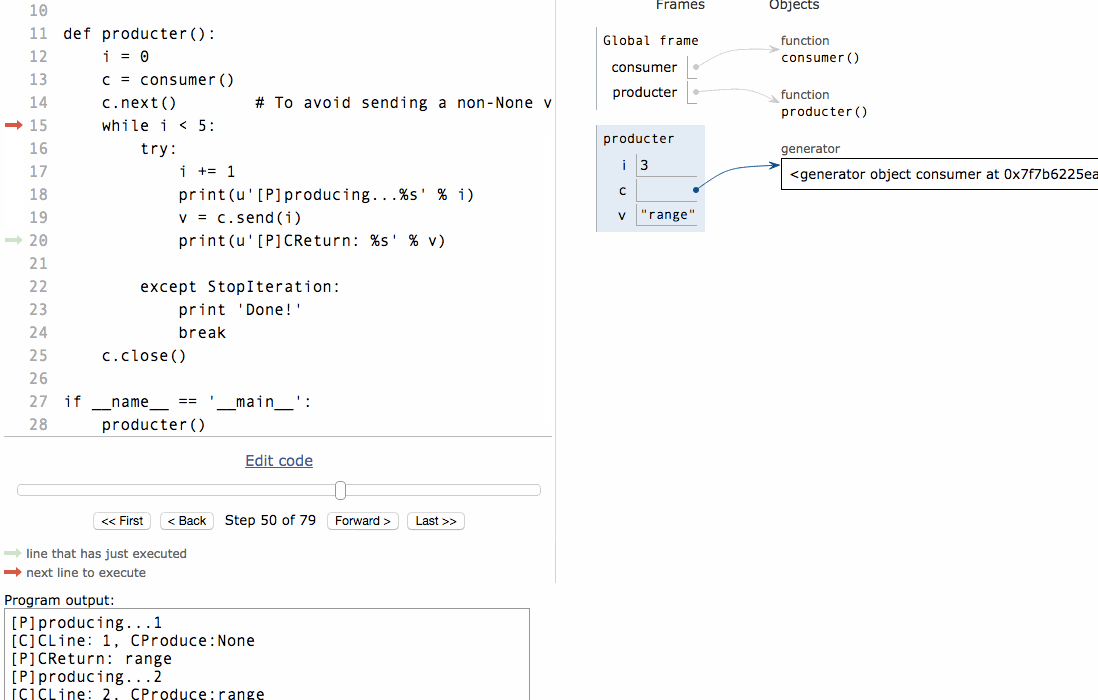
# 协程#生产者生产消息后,直接通过yield跳转到消费者开始执行,待消费者执行完毕后,切换回生产者继续生产,效率极高:def consumer():v = Nonewhile 1:m = yield vif not m:returnprint "[C]CLine:%s, CProduce:%s" % (m, v)v = 'range'def producter():i = 0c = consumer()c.next() # To avoid sending a non-None value to a just-started generator, you need to call next or send(None) first.while i < 5:try:i += 1print(u'[P]producing...%s' % i)v = c.send(i)print(u'[P]CReturn: %s' % v)except StopIteration:print 'Done!'breakc.close()if __name__ == '__main__':producter()
执行结果如下:
[P]producing...1[C]CLine:1, CProduce:None[P]CReturn: range[P]producing...2[C]CLine:2, CProduce:range[P]CReturn: range[P]producing...3[C]CLine:3, CProduce:range[P]CReturn: range[P]producing...4[C]CLine:4, CProduce:range[P]CReturn: range[P]producing...5[C]CLine:5, CProduce:range[P]CReturn: range
引用廖雪峰python协程的理解:
注意到consumer函数是一个generator(生成器),把一个consumer传入produce后:
首先调用c.next()启动生成器;
然后,一旦生产了东西,通过c.send(n)切换到consumer执行;
consumer通过yield拿到消息,处理,又通过yield把结果传回;
produce拿到consumer处理的结果,继续生产下一条消息;
produce决定不生产了,通过c.close()关闭consumer,整个过程结束。
整个流程无锁,由一个线程执行,produce和consumer协作完成任务,所以称为“协程”,而非线程的抢占式多任务。
最后套用Donald Knuth的一句话总结协程的特点:
“子程序就是协程的一种特例。”
执行动态图如下:
下节要点:
1.Python异步与yield的总结
2.Tornado异步非阻塞实例与yield的总结
作者:BeginMan
在未标明转载的情况下,本文版权归作者,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。