要求:
删除有序数组(或有序单链表)中的重复项。
示例:
输入[1,1,2,2,3] 输出[1,2,3]
输入a->b->b->c->c 输入a->b->c
思路:
双指针,慢指针从第1个有效元素开始,快指针从第2个有效元素开始,快指针对应的元素与慢指针对应的元素比较,如果发现相同,说明有重复,快指针向前移,如果不同,说明该元素不重复,将其复制到慢指针的后一位,同时快、慢指针均向前移,不断重复,直到结束。
图解如下:
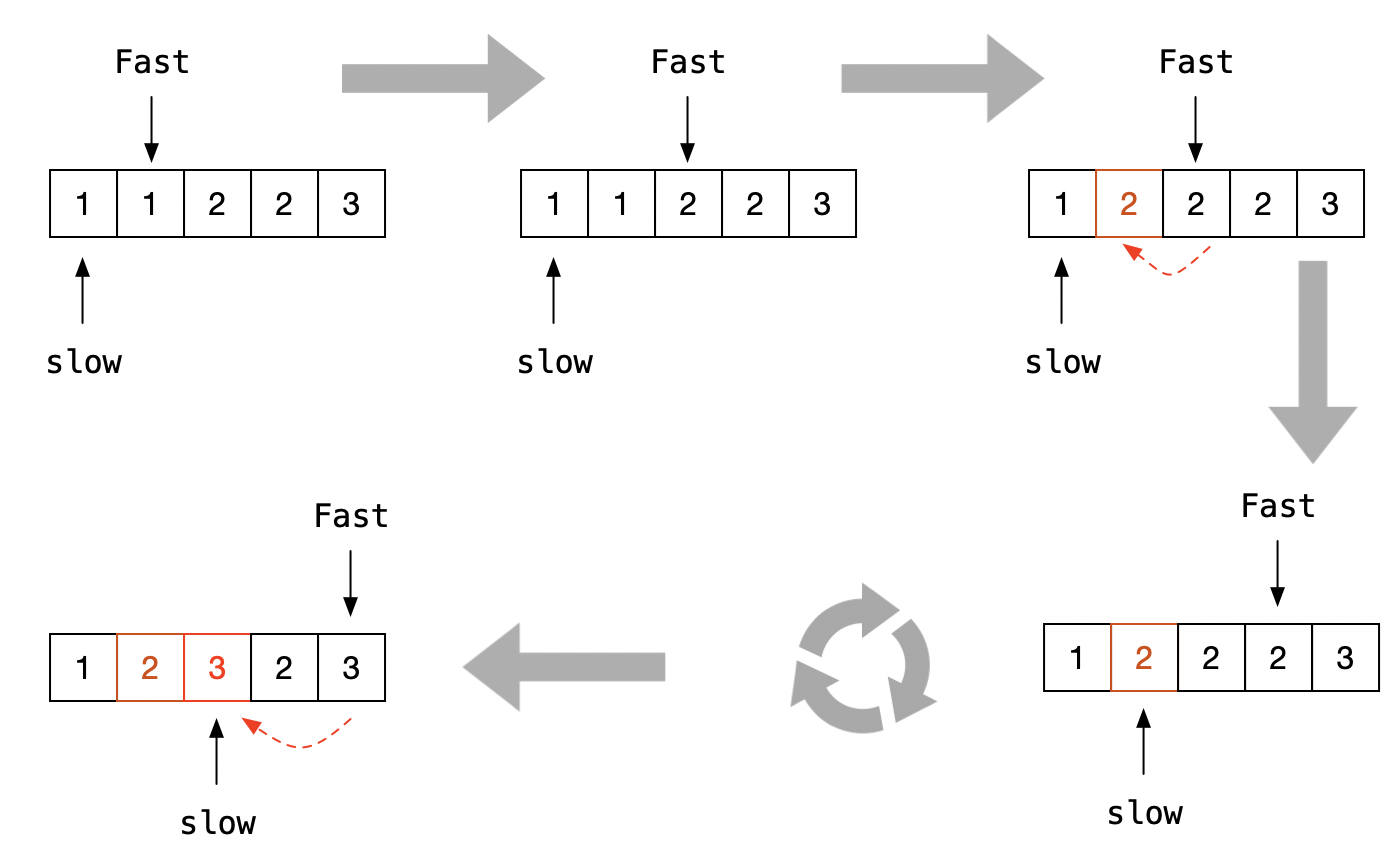
/**
* 有序数组删除重复项
* @param nums
* @return 去重后的元素个数
*/
public int removeDuplicates(int[] nums) {
if (nums == null) {
return 0;
}
int i = 0;
for (int j = 1; j < nums.length; j++) {
if (nums[i] != nums[j]) {
i++;
if (j - i > 0) {
nums[i] = nums[j];
}
}
}
return i + 1;
}
注:j即为快指针,i为慢指针,如果每个元素都不同的情况下,比如[1,2,3],为了减少无意义的移动赋值,所以加了if(j-i)>0的判断。
上述思路,也可以适用于单链表
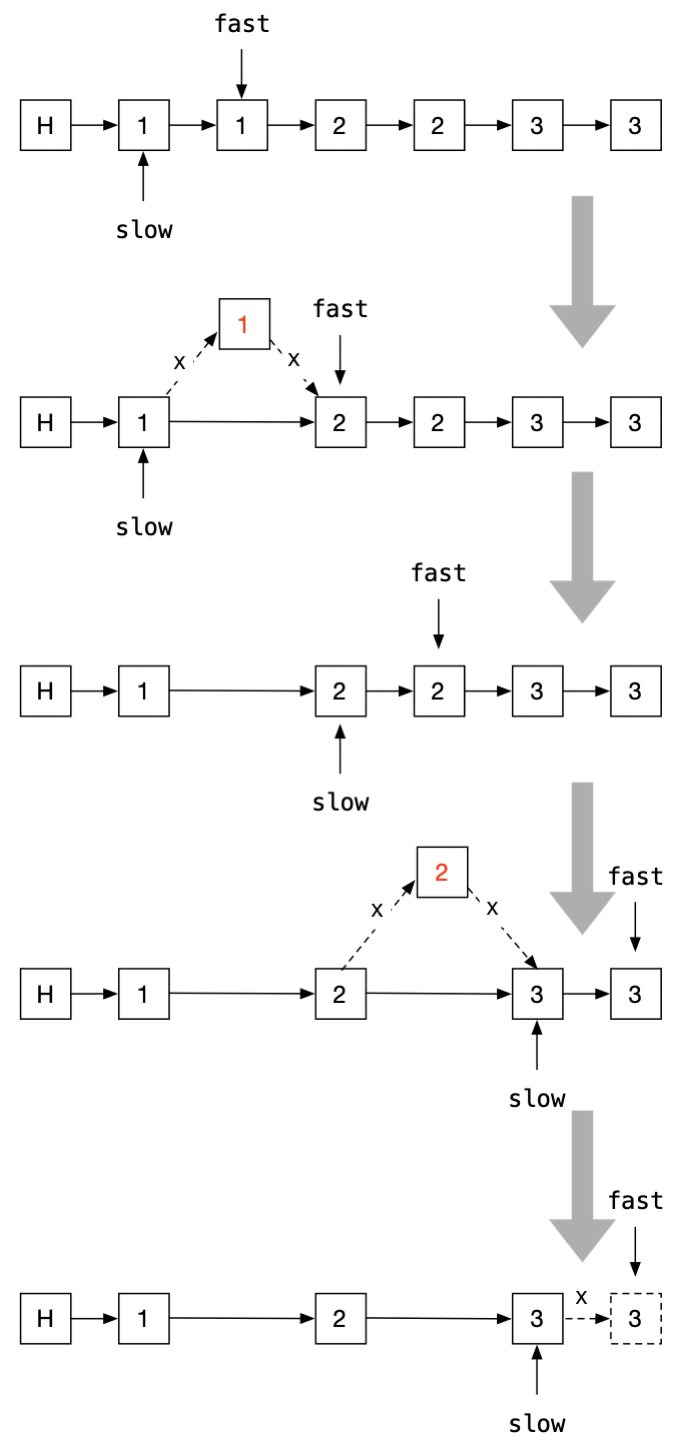
注:通常会在单链表头部加一个“哑”节点来简化问题,上图中的H即为“哑”节点。跟数组不同的是,当fast到达末节点时,slow的next必须设置为空,否则如果末端的几个节点出现重复时,尾巴上的重复节点甩不掉。
private void removeDuplicate(Node dummy) {
//辅助行,输出整个链表
printNode(dummy);
Node slow = dummy.next;
Node fast = slow.next;
while (true) {
if (fast.value != slow.value) {
slow.next = fast;
slow = slow.next;
}
fast = fast.next;
if (fast == null) {
slow.next = null;
break;
}
}
//辅助行,输出整个链表
printNode(dummy);
}
注:当然,如果考虑空链表(或链表只有1个元素)等边界条件,大家可以在最开始自行加一些判断,Node类的定义,可参考上一篇
扩展:如果要去重的数组,不是有序的,比如['a','a','b','a','c','c'] 这种如何去重呢?
仍然可以用双指针法,但是每次fast指针对应的元素,就必须再到慢指针之前的所有元素中,对比一次,才能知道是不是重复了。
数组:
private int removeDuplicate2(char[] src) {
if (src == null || src.length <= 1) {
return 0;
}
//辅助行,打印日志
System.out.println(new String(src));
int i = 0;
for (int j = 1; j < src.length; j++) {
boolean found = false;
for (int k = 0; k <= i; k++) {
if (src[k] == src[j]) {
found = true;
break;
}
}
if (!found) {
i++;
src[i] = src[j];
}
}
//辅助行,输出最终结果
System.out.println(new String(Arrays.copyOf(src, i + 1)));
return i + 1;
}
当然如果允许使用HashSet的话,也可以直接扔到Set里自动去重(面试时,如果这样回答,可能会让面试官觉得投机取巧^_^)
单链表:
private void removeDuplicate3(Node dummy) {
//辅助行,输出整个链表
printNode(dummy);
Node slow = dummy.next;
Node fast = slow.next;
while (true) {
Node temp = dummy.next;
boolean found = false;
while (temp != null) {
if (temp.value == fast.value) {
found = true;
break;
}
if (temp.next == slow.next) {
break;
}
temp = temp.next;
}
if (!found) {
slow.next = fast;
slow = slow.next;
}
fast = fast.next;
if (fast == null) {
slow.next = null;
break;
}
}
//辅助行,输出整个链表
printNode(dummy);
}
当然,如果考虑到java里的set集合,key不允许重复的特点,可以借助set进一步简化:
void removeDuplicate4(Node dummy) {
//辅助行,输出整个链表
printNode(dummy);
Node curr = dummy.next;
Set<String> set = new HashSet<>();
while (curr != null && curr.next != null) {
set.add(curr.value);
if (set.contains(curr.next.value)) {
curr.next = curr.next.next;
} else {
curr = curr.next;
}
}
//辅助行,输出整个链表
printNode(dummy);
}