概述:
本地化是系统或软件运行的语言和文化环境。设置NLS_LANG环境参数是规定Oracle数据库软件本地化行为最简单的方式。
NLS_LANG参数不但指定了客户端应用程序和Oracle数据库所使用的语言和地区;同时也指定了客户端程序输入数据和显示数据所使用的字符集。
本文主要包含如下五部分
◆
NLS_LANG环境变量的构成
◆ NLS_LANG环境变量的格式
◆
如何查看数据库NLS参数设置
◆ 举例说明如何设置NLS_LANG环境变量
◆
举例说明一些特殊情况
一,NLS_LANG环境变量的构成
NLS_LANG环境变量由如下三部分构成:
1,LANGUAGE:客户端系统所使用的语言。
指定Oracle数据库反馈的消息(例如异常信息,提示信息等)、字符数据的排列顺序(当指定ORDER BY时)、日(年月日中的天)名称,月名称等所使用的语言。
每个支持的语言都有唯一的名称。例如,若操作系统使用简体中文,则为SIMPLIFIED CHINESE;若操作系统使用美式英文操作系统,则为AMERICAN。
LANGUAGE参数中隐含地区和字符集参数的信息。如果没有指定LANGUAGE参数的值,则默认值为AMERICAN。
2,TERRITORY:客户端系统所在的地区。
指定默认的日期,货币以及数字格式。
每一个支持的地区都有唯一的名称。如,CHINA,AMERICA或CANADA。
如果没有指定TERRITORY参数,则此参数的值由LANGUAGE参数推理得出。
3,CHARSET:客户端应用程序所使用的字符集。
正确地设置NLS_LANG环境变量,则使得字符数据能够在客户端字符集和数据库字符集之间正确地转换。
设置NLS_LANG不会改变客户端系统的字符集,它仅仅是让Oracle数据库知道客户端应用程序使用的是什么字符集,从而进行相应的字符集转换。
如果客户端和数据库字符集相同,则Oracle数据库忽略字符集校验,不执行字符集转换。
Oracle所支持的每个字符集都有唯一的缩写。如,ZHS16GBK(GBK),AL32UTF8(UTF-8)等。
每一个LANGUAGE默认都有一个和它关联的字符集。
二,NLS_LANG环境变量的格式
NLS_LANG = LANGEAGE_TERRITORY.CHARSET
注意,此处的.为英文逗号。
三,如何查看数据库NLS参数设置
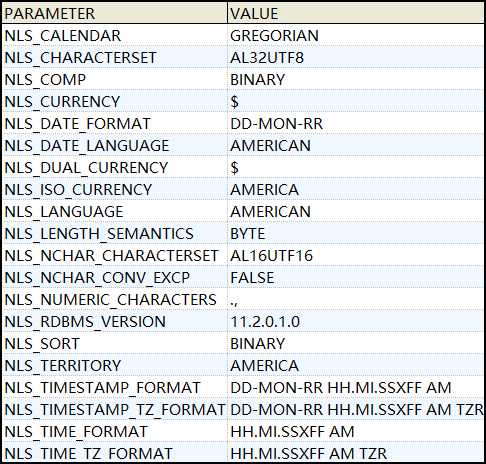
1,通过NLS_DATABASE_PARAMETERS视图查看数据库的NLS参数。
SELECT
* FROM NLS_DATABASE_PARAMETERS ORDER BY PARAMETER;
查询如下图所示。其中,NLS_CHARACTERSET参数的值就表示数据库所使用的字符集(创建数据库时所指定的字符集)。
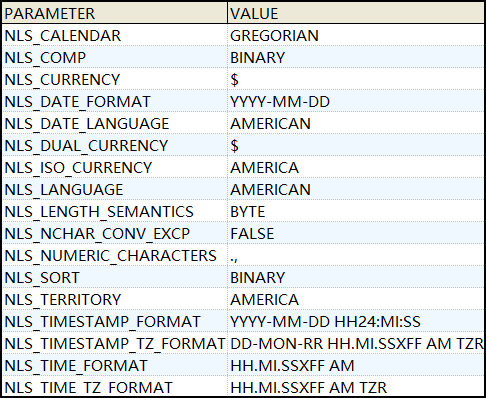
2,通过NLS_SESSION_PARAMETERS视图查看当前用户会话的NLS参数。
SELECT * FROM NLS_SESSION_PARAMETERS ORDER
BY PARAMETER;
查询如下图所示:
四,举例说明如何设置NLS_LANG环境变量
此部分主要通过Oracle数据库自带的SQL PLUS数据库客户端程序说明如何设置NLS_LANG中的字符集。
实验环境:
数据库NLS参数设置:数据库NLS参数设置如第三部分(查看数据库NLS参数设置)中第一个图所示,NLS_CHARACTERSET=AL32UTF8。
操作系统:Windows
10英文企业版64位。
实验准备:
1,创建一个表CHINESE_DATA
CREATE TABLE CHINESE_DATA( CH_DATA VARCHAR2(64) );
实验一:
此实验举例说明如何正确地设置命令行窗口和系统的NLS_LANG环境变量,从而能够正确地显示查询结果。
1,设置客户端系统的NLS_LANG环境变量
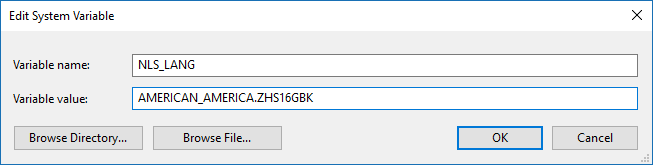
如上图所示,Windows系统环NLS_LANG境变量的值为AMERICAN_AMERICA.ZHS16GBK,而数据库的字符集为AL32UTF8。
很显然,数据库字符集和客户端NLS_LANG中的字符集不一样。这就有可能导致客户端查询数据时出现乱码。
2,插入一条数据
INSERT INTO CHINESE_DATA VALUES('汉字'); COMMIT;
注意:插入数据时可以借助PL/SQL Developer等工具,以确保数据能正确地输入并存储到数据库中。
3,使用默认环境,在不改变命令行窗口代码页(每个代码页都对应着一个字符集)的情况下查询数据。
437代码页对应的字符集主要包含拉丁字母。
437代码页所包含的字符分类:
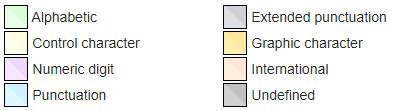
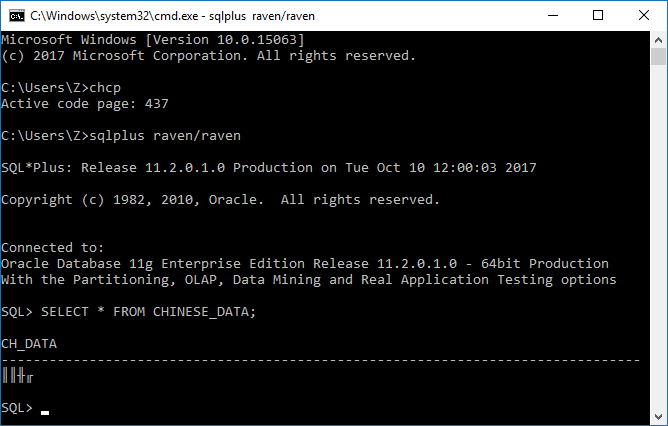
如上图所示,不出所料,查询结果出现乱码。
实验说明:
数据库字符集为AL32UTF8,Oracle通过NLS_LANG得知客户端字符集为ZHS16GBK。
Oracle在返回查询结果时,把数据转换为GBK格式,而437代码页所包含的字符中根本没有汉字字符,所以显示为乱码。
4,把命令行窗口的代码页改为65001,其对应的字符集为UTF-8。
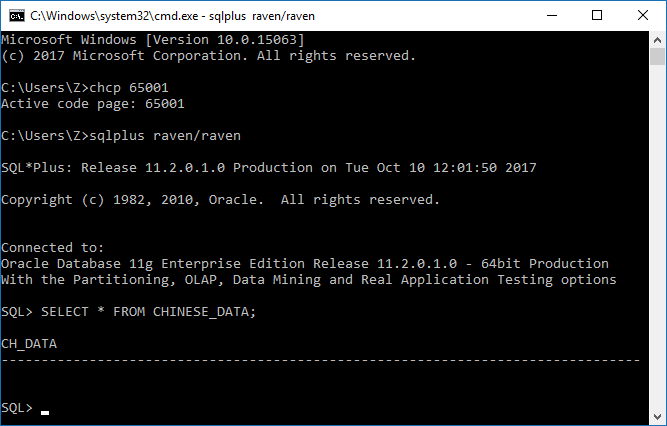
如上图所示,查询结果为不可见字符,也属于乱码。
实验说明:
Oracle返回的数据为GBK字符集,而控制台为UTF-8字符集。尽管UTF-8字符集是GBK字符集的超集(其包含了所有GBK字符集中的字符),
但是两者对同一个字符的编码是不一样的。如图所示,GBK中“汉字”这两个字符所包含的字节(Bytes)在UTF-8字符集中都表示不可见字符。
所以,其显示结果是不正确的。
5,把控制台代码页设置为936,其对应的字符集为GB2312。
注意,由于本次实验的环境为英文系统,故而需要设置命令行窗口的字体。不然,无法正确显示中文字符。
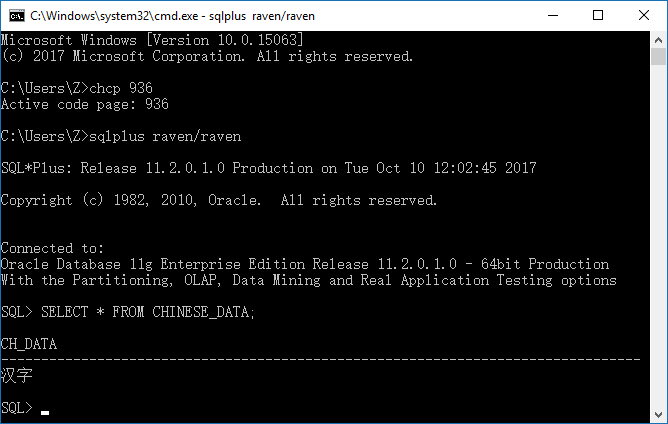
如图所示,其查询结果是正确的。
实验说明:
尽管GBK字符集是GB2312字符集的超集,其比GB2312字符集包含更多的字符。
但是GBK字符集向前兼容GB2312字符集。“汉字”这两个字符在GBK和GB2312字符集中的编码完全相同,所以查询能够正确显示。
实验结论:
1,NLS_LANG环境变量中所指定的字符集其实就是数据库客户端应用程序所使用的字符集。
如果客户端应用程序不支持NLS_LANG中所包含的字符集或者所支持的字符集与NLS_LANG中的字符集不兼容,则会出现乱码。
2,此外,即使客户端字符集和数据库字符集相同,也可能会出现乱码。
假如,Oracle数据库为AL32UTF8字符集,客户端使用UTF-8字符集。
然而,现实情况总是很复杂的。如果客户端和数据库所支持的UNICODE标准不一样,则在很罕见的情况下仍有可能出现乱码。
实验二:
此实验举例说明数据库不支持客户端字符集所包含的字符时会产生什么样的结果。
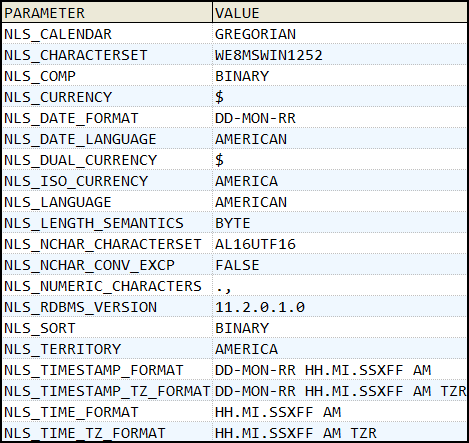
1,创建一个使用WE8MSWIN1252字符集的数据库。
本次实验创建了一个名为TALRASHA的数据库,其使用WE8MSWIN1252字符集。
以下是通过NLS_DATABASE_PARAMETERS视图所查询到的数据库NLS参数。
2,设置客户端系统的NLS_LANG环境变量
3,插入并查询数据
由于需要存储中文字符,故此处将代码页设置为936。
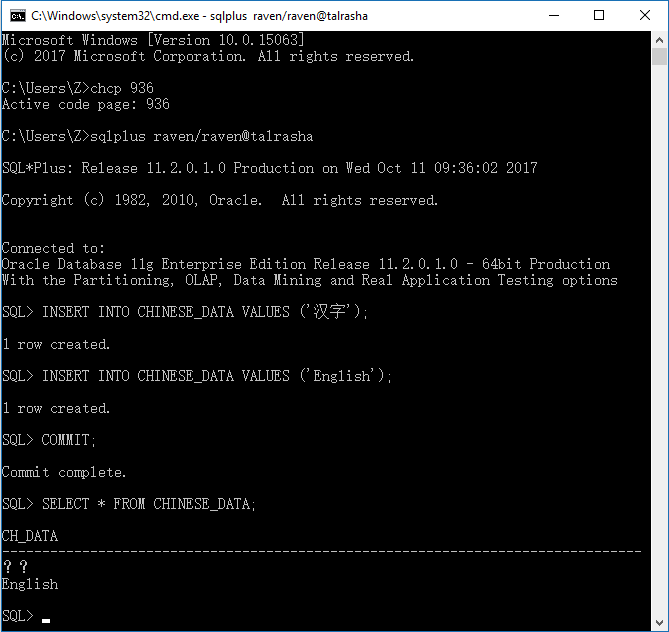
实验说明:
如上图所示,由于数据库字符集为WE8MSWIN1252,其不能正确地存储中文字符,但可以正确存储英文字符。
所以,查询结果中,中文为乱码,英文正常显示。
实验结论:
1,如果客户端应用程序所使用的字符集是数据库字符集的超集,或者客户端应用程序中的某些字符不在数据库字符集所表示的范围之内,则数据库在进行字符集转换时会产生错误的结果。
2,属于客户端字符集和数据库字符集交集中的字符能够正常存储和显示。
最终结论:
1,在查询数据时,客户端字符集应该等于数据库字符集或者是数据库字符集的超集。从而避免显示结果出现乱码的问题。
2,在数据输入时,客户端字符集应该等于数据库字符集或者是数据库字符集的子集。从而使得输入字符能够在数据库中正确地保存。
3,在创建数据库时,尽可能使用UNICODE字符集,从而避免字符数据不能正确存储的问题。
五,举例说明一些特殊情况
通过以上两个实验基本说明了客户端应用程序字符集,客户端系统的NLS_LANG所包含的字符集和Oracle数据库字符集三者之间的关系。
但是,某些数据库客户端应用程序有自己独立的客户端环境配置,其不依赖于客户端系统中的NLS环境变量或者依仅赖于某些系统环境变量。
例如,PL/SQL Developer和SQL Developer。它们的编辑器有自己的字符集和字体的设置,同时这两个软件也支持一些其他设置(如日期格式或者地区等)。
所以,在进行第四部分的试验一时,建议先通过这两个应用程序插入数据。
此外,还需要注意字体对数据显示的影响。有的字体不能正确地显示输入或查询结果中的字符也会产生问题。