urllib库的使用
urllib库是Python内置的HTTP请求库,它包含了4个模块:
request:最基本的HTTP请求模块,用来模拟发送请求
error:异常处理模块。出现请求错误后,我们可以捕获异常,然后进行下一步的操作。
parse:工具模块。提供了很多URL处理方法。
robotparse:主要用来识网站的robots.text文件,用的比较少
1.发送请求
urllib的request模块可以帮助我们方便的发送请求并得到响应。下面我们来看一下用法:
1.urlopen()
urlopen()参数有url、data、timeout、context、cafile、capath、cadefault,我们只详细了解三个,他们比较重要:
url:要请求的网址
下面我们以Python官网为例,我们来把它抓取下来:
import urllib.request
response = urllib.request.urlopen("https://www.python.org/")
print(response)
我们充满期待的想要看到网页内容,却发现是这样:

显而易见,我们得到的结果是一个HTTPResponse类的对象,我们想要得到它的内容得使用它的read()方法,另外read()得到的是bytes类型的数据,我们将它解码,方便观看
import urllib.request
response = urllib.request.urlopen("https://www.python.org/") print(response.read().decode("UTF-8"))
这次得到的结果,如我们所愿,不就是网页的源代码嘛:
下来我们说一下这个HTTPResponse类型的对象,他有很多属性和方法,
https://www.cnblogs.com/kissdodog/archive/2013/02/06/2906677.html 这个博客中有详细说明,我就不多提了^_^
data:data参数是可选的,但必须给bytes类型,一旦设置data参数,请求的方式就会变成POST,如果不设置则默认为GET
我们通过代码看一下:
import urllib.parse import urllib.request
data = bytes(urllib.parse.urlencode({"word":"hello"}),encoding="UTF-8") #我们借助urllib库的parse中的urlencode方法将字典转化为字符串 response = urllib.request.urlopen("http://httpbin.org/post",data=data) #这个网站用来做HTTP请求测试,我们用来进行POST请示测试 print(response.read().decode("UTF-8"))
我们来看一下结果:
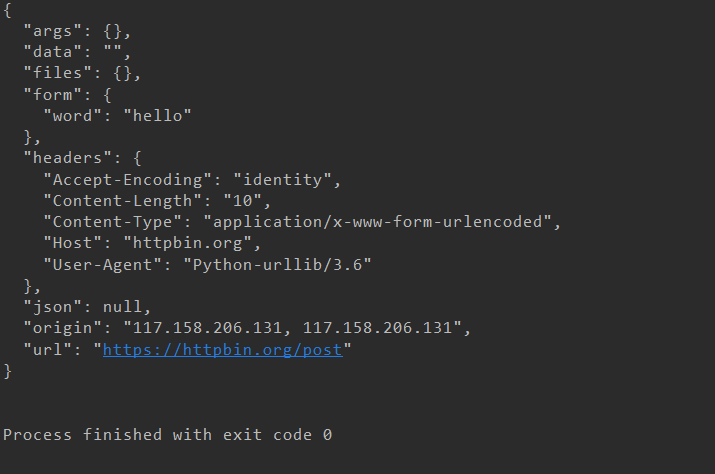
我们可以很清楚的看到我们传进的data参数出现在了form里面,我们知道只有POST请求才会把数据封装到form表单中。data设置的参数会被封装到form表单中,封装到请求头中传递给服务器。
timeout:设置超时时间,单位为秒,当超过这个时间,请求没有得到响应,就会抛出异常。
import urllib.request
response = urllib.request.urlopen("http://httpbin.org/get",timeout=0.1) #我们将这个时间设置的短一点,请求不可能这么快得到响应,这样就会抛出异常 print(response.read())
果然不出所料:


但是,我们都知道Python有try except异常处理机制,我们在这里可以用到
import socket import urllib.request import urllib.error
try: response = urllib.request.urlopen("http://httpbin.org/get",timeout=0.1) except urllib.error.URLError as e: if isinstance(e.reason,socket.timeout): print("超时了")

所以我们通过设置timeout,一旦超时进行异常处理,这样能很好的提高爬取速率
context:用来指定SSL设置。
cafile:CA证书。
capath:CA证书的路径。
cadefault:现在已弃用,默认值为false。
2.Request
我们可以利用urlopen()方法来发送请求,但是urlopen()中几个参数并不能构成一个完整的请求。我们需要借助Request类构建对象,对象中可以携带Headers等信息,从而实现完整的请求。
我们先来看一下Request的用法:
import urllib.request
request = urllib.request.Request("https://python.org") print(type(request)) response = urllib.request.urlopen(request) #我们仍然使用urlopen()来发送请求,但是方法的参数不是URL,而是一个request对象,我们将参数独立成对象,可以灵活的进行参数配置。 print(response.read().decode("UTF-8"))
下面我们看一下Request对象的参数有哪些:
url:用于请求的URL,必传参数,其他都是选传。
data:必须传bytes类型的。如果是字典,我们可以借助urllib.parse模块中的urlencode()进行编码。
headers:请求头,是一个字典。我们可以直接构造,也可以通过调用add_header()方法添加
ps:请求头中最常改的就是User-Agent,默认的User-Agent为Python-urllib,我们可以通过修改它来伪造浏览器。比如我们要伪装为火狐浏览器,可以设置为:
Mozilla/4.0 (compatible; MSIE 5.5; Window NT)
origin_req_host:请求放的host名称或IP地址
unverifiable:用户用没有权限来选择接收请求的结果。默认为False,如果没有权限贼为True,否则为False。
method:请求使用的方法,如GET、POST和PUT
话不多说,我们来看一下:
from urllib import request,parse url = "http://httpbin.org/post" headers = { "User-Agent":"Mozilla/4.0 (compatible; MSIE 5.5; Windows NT", "Host":"httpbin.org" } dict = { "name":"Germey" } data = bytes(parse.urlencode(dict),encoding="UTF-8") req = request.Request(url=url,data=data,headers=headers,method="POST") response = request.urlopen(req) print(response.read().decode("UTF-8"))
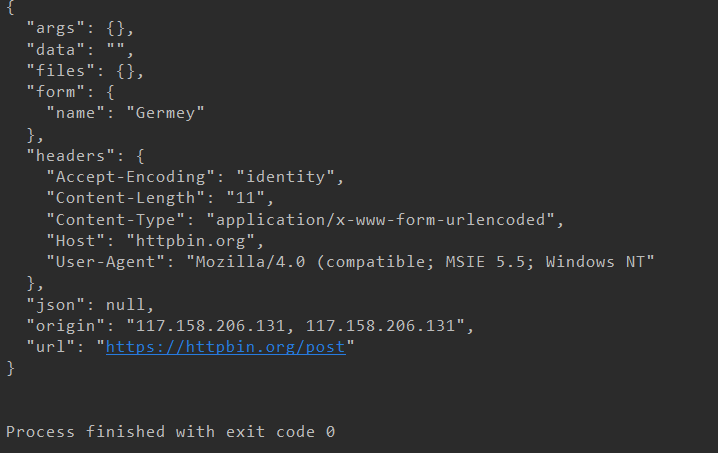 明显的看到,我们成功的设置了headers,method,data。
明显的看到,我们成功的设置了headers,method,data。
headers信息我们还可以使用add_headers来添加
from urllib import request,parse url = "http://httpbin.org/post" dict = { "name":"Germey" } data = bytes(parse.urlencode(dict),encoding="UTF-8") req = request.Request(url=url,data=data,method="POST") req.add_header("User-Agent","Mozilla/4.0 (compatible; MSIE 5.5; Windows NT") #add_headers(key,value) response = request.urlopen(req) print(response.read().decode("UTF-8"))
2.处理异常
我们已经了解了怎样发送请求,但是请求不是每次都能得到响应,可能会出现异常,不去处理它程序可能因此停掉,所以很有必要去处理异常。
urllib的error模块定义了由request模块产生的异常。如果出现问题,request模块会抛出error模块中定义的异常。
1.URLError
URLError类来自error模块,是error异常模块的基类,由request模块产生的异常都可以通过捕获这个类来处理,它的属性reason可以返回错误原因。
from urllib import request,error try: response = request.urlopen("https://cuiqingcai.com/index.htm") #我们打开的页面不存在 except error.URLError as e: print(e.reason)
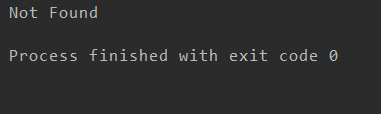
我们打开的页面不存在,按理说会报错,但是我们将异常捕获,并输出异常得原因,通过这样的操作,我们可以避免程序异常终止,而且异常得到了很好的处理。
2.HTTPError
他是URLError的子类,专门用来处理HTTP请求错误。他有三个属性:
code:返回HTTP状态码,比如404表示页面不存在,500表示服务器内部出错
reason:返回错误的原因
headers:返回请求头
from urllib import request,error try: response = request.urlopen("http://cuiqingcai.com/index.htm") except error.HTTPError as e: print(e.reason,e.code,e.headers,sep=" ")
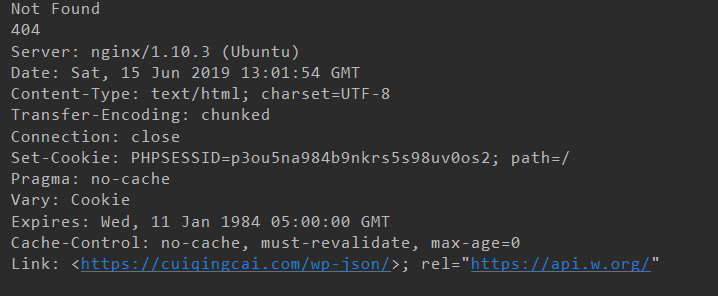
同样的网页,我们通过捕获HTTPError来获得reson,code和headers属性。因为URLError是HTTPError的子类,所以我们可以选择捕获子类的错误,如果没有再去捕获父类错误,代码如下:
from urllib import request,error try: response = request.urlopen("http://cuiqingcai.com/index.htm") except error.HTTPError as e: print(e.reason,e.code,e.headers,sep=" ") except error.URLError as e: print(e.reason) else: print("Request Successfully")
但是有时候reason属性返回的不是字符串,而是一个对象:
from urllib import request,error try: response = request.urlopen("http://cuiqingcai.com/index.htm",timeout=0.01) except error.HTTPError as e: print(e.reason,e.code,e.headers,sep=" ") print(type(e.reason)) except error.URLError as e: print(e.reason) print(type(e.reason)) else: print("Request Successfully")
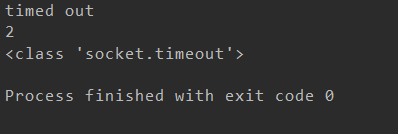 我们可以很清楚的看到e.reson是一个socket.timeout对象,我们简单的记住就行了,请求超时后,返回的错误为timed out,是socket.timeout类的对象
我们可以很清楚的看到e.reson是一个socket.timeout对象,我们简单的记住就行了,请求超时后,返回的错误为timed out,是socket.timeout类的对象
学了处理异常后,通过捕获异常并处理,可以使我们的程序更加的稳健。
3.解析链接
前面提到了urllib库里的parse模块,他提供了很多处理链接的方法,实现了URL各部分的抽取、合并、以及链接转化。
1.urlparse()
该方法可以实现URL的识别和分段,共有三个参数,返回的结果是一个元组我们可以通过属性或索引拿到相应的值
urlstring:待解析的URL,必选项
scheme:默认的协议,如果链接没有带协议会解析出默认协议,否则解析出链接带的协议
allow_fragments:是否忽略fragment,如果为false,fragment部分就会被忽略,会被解析成path、params或query的一部分
urlparse()会把URL解析成6个部分,标准的链接格式如下:
scheme://netloc/path;params?query#fragment
协议://域名/访问路径;参数?查询条件#锚点
查询条件一般用作GET类型的URL,锚点用于定位页面内部的下拉位置
from urllib.parse import urlparse result = urlparse("http://www.baidu.com/index.html;user?id=5#comment") print(type(result),result,sep=" ")

2.urlunparse()
该方法接受一个可迭代对象,长度必须是6,对可迭代对象进行遍历,构造URL
from urllib.parse import urlunparse data = ["http","www.baidu.com","index.html","user","a=6","comment"] print(urlunparse(data))
![]()
3.urlsplit()
该方法与urlparse()方法类似,只不过它不再单独解析params,params合并到path中,返回的也是个元组,长度为5
from urllib.parse import urlsplit result = urlsplit("http://www.baidu.com/index.html;user?a=6#comment") print(result)

4.urlunsplit()
参照urlunparse(),但是长度为5
5.urljoin()
有两个参数,第一个为base_url(基础链接),第二个为new_url(新的链接),该方法会解析base_url的scheme,netloc和path,如果新的链接存在就是用新的链接的部分,如果不存在就补充。
from urllib.parse import urljoin print(urljoin("http://www.baidu.com","FAQ.html")) print(urljoin("http://www.baidu.com","https://cuiqingcai.com/FAQ.html")) print(urljoin("http://www.baidu.com/about.html","https://cuiqingcai.com/FAQ.html")) print(urljoin("http://www.baidu.com/about.html","http://cuiqingcai.com/FAQ.html?question=2")) print(urljoin("http://www.baidu.com?wd=abc","https://cuiqingcai.com/index.php")) print("http://www.baidu.com","?category=2#comment") print("www.baidu.com","?category=2#comment") print("www.baidu.com#comment","?category=2")

6.urlencode()
在构造GET请求的参数时,可以将字典类型的数据转化为GET请求参数
from urllib.parse import urlencode params = { "name":"heesch", "age":18 } base_url = "http://baidu.com?" url = base_url + urlencode(params) print(url)

7.parse_qs()
与urlencode()相反,将GET请求的参数化为字典的形式
from urllib.parse import parse_qs query = "name=heesch&age=18" print(parse_qs(query))

8.parse_qsl()
他是将GET请求的参数转化为元组组成的列表
from urllib.parse import parse_qsl query = "name=heesch&age=18" print(parse_qsl(query))
![]()
9.quote()
将内容转化为URL编码的格式,URL中带有中文参数时,有时可能会导致乱码的问题。
from urllib.parse import quote keyword = "壁纸" url = "http://www.baidu.com" + quote(keyword) print(url)
![]()
10.unquote()
与quote相反,将URL进行解码
from urllib.parse import unquote url = "http://www.baidu.com%E5%A3%81%E7%BA%B8" print(unquote(url))

4.分析Robots协议
1.Robots协议
Robots协议也称作爬虫协议、机器人协议,用来告诉爬虫和搜索引擎哪些页面可以爬取,哪些不可以抓取。通常是一个叫做robots.txt的文本文件,放在网站的根目录下
当搜索爬虫访问一个站点是,首先会检查这个站点的根目录下是否存在robots.txt文件,如果存在,搜索爬虫则会根据其中定义的爬取范围来爬取。如果没有,则搜索爬虫会访问所有可直接访问的站点。
下面看一个robots.text样例:
User-agent:* Disallow:/ Allow:/public/
User-agent:设置爬虫的名称,* 表示该协议对任何爬虫都有效
Dislalow:制定了不允许抓取的目录,若为/ 表示不允许抓取任何页面
Allow:和Disallow一起出现,限制访问路径
2.常见爬虫

3.robotparse
了解完Robots协议之后,我们可以使用robotparser模块来解析robot.txt。该模块提供一个类RobotFileParse,它可以根据robots.txt文件来判断一个爬虫是否有权限来爬取这个页面
声明:urllib.robotparser.RobotFileParser(url="")
这个类常用的方法:
set_url():设置robots.txt文件的链接。如果创建RobotFileParse对象时传入链接,就不需要用这个方法进行设置了
read():读取robots.text文件并分析,不会返回结果,但是执行了读取操作,如果不执行,下面的方法判断都为false
parse():用来解析robots.txt文件
can_fetch():有两个参数,第一个是User-agent,第二个是要抓取的URL,返回的结果为True或False,用来判断是否能抓取这个页面
mtime():返回上次抓取robot.txt的时间,对于长时间分析或抓取的搜索爬虫需要定期检查
modified():将当前时间设置为上次抓取和分析robots.txt的时间
我们先用can_fetch()方法来判断网页是否能抓取:
from urllib.robotparser import RobotFileParser rp = RobotFileParser() rp.set_url("http://jianshu.com/robot.txt") rp.read() print(rp.can_fetch("*","http://www.jianshu.com/p/b67554025d7d")) print(rp.can_fetch("*","http://www.jianshu.com/search?q=python&page=1&type=collections"))
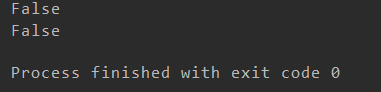 两个false,都不让抓取。
两个false,都不让抓取。
我们再用parse()方法来判断网页是否能抓取:
from urllib.robotparser import RobotFileParser from urllib import request,parse url = "https://www.jianshu.com/robots.txt" headers = { "User-Agent":"Mozilla/4.0 (compatible; MSIE 5.5; Windows NT", } rp = RobotFileParser() req = request.Request(url=url,headers=headers,method="GET") rp.parse(request.urlopen(req).read().decode("UTF-8").split(" ")) print(rp.can_fetch("*","http://www.jianshu.com/p/b67554025d7d")) print(rp.can_fetch("*","http://www.jianshu.com/search?q=python&page=1&type=collections"))
 我们学完robotparser模块后,我们可以方便的判断哪些一面可以抓取,哪些页面不能抓取。
我们学完robotparser模块后,我们可以方便的判断哪些一面可以抓取,哪些页面不能抓取。