正则表达式
一、正则表达式定义
JavaScript 正则表达式
正则表达式(英语:Regular Expression,在代码中常简写为regex、regexp或RE)使用单个字符串来描述、匹配一系列符合某个句法规则的字符串搜索模式。
搜索模式可用于文本搜索和文本替换。
简单的说就是一个有规则的表达式,用于查找的通配符。
正则表达式就是一个用于查找含有匹配字符串 的 字符串
二、正则表达式对象
Js 正则表达式对象 就是 由正则表达式创建的对象,该对象可以进行匹配,提取和替换。
创建正则表达式对象
1、构造函数
var regex = new RegExp( 正则表达式字符串[, 匹配模式] );

匹配模式是可选参数:是一个可选的参数,包含属性 g,i,m,分别使用与全局匹配,不区分大小写匹配,多行匹配;
正则表达式g修饰符:
g修饰符用语规定正则表达式执行全局匹配,也就是在找到第一个匹配之后仍然会继续查找。


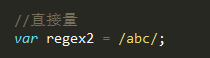
2、字面量 (直接量)
var regex = /正则表达式/;

三、使用正则表达式进行匹配
语法:
正则对象.test( 字符串 )
返回一个boolean值
如果参数字符串中含有 符合 正则匹配的 子字符串, 就返回 true, 否则返回 false
例如: 查询一段文字中是否包含 yangCJ

四、基本元字符
.[^ ] 除了换行和回车之外的任一字符
( )表示分组和提高优先级
[ ]表示一个字符, 出现在 [ ] 中的字符
用法: [abc]出现 [ ] 中的任意一个字符
匹配 a, 或 b, 或 c
foo[dt] 匹配 foot 或 food
|或 (优先级是最低的,需最后考虑)
用法:正则表达式|正则表达式
选取foot 或 food
foot|food
foo(t|d)
扩展:
. 任意的一个字符. 没有任何限制
[]是出现在[]中的一个字符. 认为 . 的限制级版本
[abc]: a 或者 b 或者 c
|可以认为是 允许使用多个字符的 匹配
a|b|c
aa|bb|cc
如果要表示 . [] () 这些符号 就要使用转义字符
转义字符
表示点: .
表示[]: [ ]
表示(): ( )
表示 : \
五、限定元字符
1>
*紧跟前面的一个字符或一组字符出现 0 次到多次
次数大于等于0
表示: 123333333 后面很多 3
正则: 1233*
123 0 次
1233 1 次
12333 2 次
...
1233333333333333333
也能表示一个组的次数
1(23)*
表示:
1 (出现0次)
1 23 (出现1次)
1 23 23 (出现2次)
1 23 23 23(出现3次)
2>
+紧跟在前面的字符出现 1 次到多次
次数大于等于1
字符串: 123333333
正则: 123+
3>
?紧跟在前面的字符出现 0 次或 1 次
检查在一段字符串中检查是否含有 http 协议的字符串或 https 协议的字符串
https?://.+
4>
{数字}紧跟在前面的字符出现指定次数
a{3}
匹配3个a
aaa
5>
{数字,}紧跟在前面的字符至少出现指定次数
a{3,}
匹配至少3个a:
aaa, aaaaaaaaa, aaaaaaaaaaaaaa, ...
6>
{数字, 数字} 紧跟在前面的字符出现的次数范围
a{1, 3}
匹配1到3个a
a, aa, aaa
六、首尾正则表达式
^表示必须以 xxx 开头
^a 必须以 a 开头的字符串
a 表示一个字符串中只要含有 a 就可以匹配
^a^a 非法的写法, ^ 如果是表示开头必须写在开头, 而且只能写一个
$表示 必须以 xxx 结尾
a$必须以 a 结尾
分析^a+$
匹配一个只有a 的字符串
七、案例
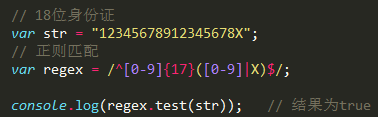
1> 写一个正则表达式匹配 身份证号码
身份证是 18 位数字
省 市 区 出生年月 随机编码X
1) 首先是要做匹配, 就一定要使用 ^ $
2) 是 18 位数字( 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 ). 可以使用
[0123456789]
0|1|2|3|4|5|6|7|8|9
[0-9]
d
3) 要求是 18 位. 限定 18 位, 即 {18}
组合: ^[0123456789]{18}$
如果最后一位是X
前面 17 位数字: ^[0123456789]{17}$
后面要么是数字: [0123456789] 要么是 x: x
写法: [0123456789x]
[0123456789]|x
0|1|2|3|4|5|6|7|8|9|x
最终得:
^[0123456789]{17}[0123456789x]$
或
^[0-9]{17}([0-9]|X)$
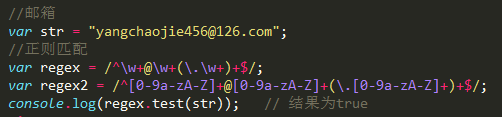
2> 匹配邮箱
12345678901@qq.com
abcdefg@126.com
abcdefg@163.com
abc@yahoo.com.cn
结尾还能是
.cc
.org
.edu
.中文
...
名字 @ 主机名
1) 是要验证邮箱, 那么就需要使用 ^ $
2) 名字:
数字与字母
[0123456789]
[abcdefghi...]
[ABCDEFG...]
[ ] 里面的字符如果是编码序号连续的可以使用连字符连接
数字: [0-9]
[9-0] 错误的, 编码逆序
字母: [a-z]
[A-Z]
整合: [0-9a-zA-Z]
名字的变式方法: [0-9a-zA-Z]+
3) 主机名
主机名也是一串字符串或数字
但是它多了一个 .com .cn
3.1) 只有名字 [0-9a-zA-Z]+
3.2) 只含有一个 .什么
开始 .
中间 [0-9a-zA-Z]+
只含有一个名字: .[0-9a-zA-Z]+
3.3) 含有多个名字
.com.con.cc.c1.c2.c3
即 .什么 出现一次到多次
(.[0-9a-zA-Z]+)+
最后主机名可以写成
[0-9a-zA-Z]+(.[0-9a-zA-Z]+)+
最后整合一下
/^[0-9a-zA-Z]+@[0-9a-zA-Z]+(.[0-9a-zA-Z]+)+$/
八、 匹配一个数字
1> 匹配一个数字
[0-9]+
1) 由于是匹配, 包含 ^ $
2) 首先第一个字符不允许是 0, 所以第一个可以写成 [1-9]
3) 后面的数字就是 [0-9]
4) 要求后面的数字出现 0 次到多次, 以匹配任意的 非 0 数字: [1-9][0-9]*
5) 由于还需要考虑 0, 因此写成 [1-9][0-9]*|0
6) 考虑 | 优先级最低: ^([1-9][0-9]*|0)$
/^(-?[1-9][0-9]*|0)$/

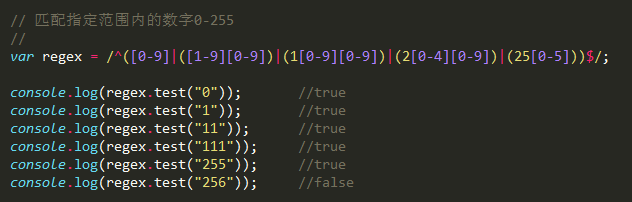
2> 匹配一个指定范围的数字
匹配 0 ~ 255 为例
如果写成这样子:
[0-255]0, 1, 2, 5错误的
如果要匹配指定范围的数字, 那么需要将字符串结构进行分类
1) 0 要匹配的, 所以在正则表达式中有 0 这一项
2) 任意的 2 位数, 即 [1-9][0-9]
3) 任意的 1 位数, 即 [0-9], 可以将 第 1) 结论合并
4) 考虑 3 位数的时候, 只允许出现 1xx 的任意数, 而 2xx 的有限制
因此在分组, 考虑 1xx 的任意数, 可以写成: 1[0-9][0-9]
5) 考虑 2xx 的数字, 在 200 到 250 之间允许任意取. 所以
写成: 2[0-4][0-9]
6) 考虑 250 到 255, 写成 25[0-5]
综合一起:
/^([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])$/
或
/^([0-9]|([1-9][0-9])|(1[0-9][0-9])|(2[0-4][0-9])|(25[0-5]))$/
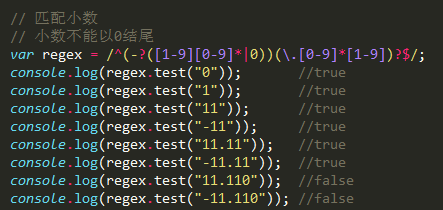
3> 匹配小数
要求, 小数不允许以 0 结尾
3.1415
/^(-?([1-9][0-9]*|0))(.[0-9]*[1-9])?$/;
(aaa)?这个内容出现或不出现
(aaa|)也是表达aaa可出现可不出现
^((-?[1-9][0-9]*|0)(.[0-9]*[1-9]|))$
九、简写元字符
s [f v] 不可见字符 (空白字符, 包括空格, tab, 回车换行)等
S [^/f/r/n/t/v] 可见字符 (非空白字符)
js 中常常使用 [sS] 表示任意字符
w [a-zA-Z0-9]_ 单词字符(表示字符, 包含字母, 数字, 下划线).
W [^a-zA-Z0-9_] 非字符
d [0-9] 数字
D [^0-9] 非数字
十、提取
核心功能:把匹配到的数据提取出来
使用正则表达式可以进行匹配, 使用 exec 可以将匹配到的数据提取出来
语法:
正则表达式对象.exec( 字符串 )
把匹配到的字符串返回到一个数组中[里面包含匹配到的字符串的信息,例如:匹配到的字符串,在元字符串中的索引值等]
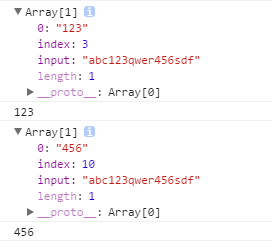
案例: 在 “abc123qwer456sdf”提取数字

这样值提取到了第一个符合条件的字符串
返回

十一、循环提取
在一个字符串中将所有复合的要求的字符串提取出来
1> 正则表达式需要使用全局模式
var r = new RegExp( '正则', 'g' );
var r = /正则/g;
2> 调用 exec 首先获得第一个匹配项
再调用一次该方法, 就可以获得 第二个匹配项
一直调用下去, 就可以得到所有的匹配项
直到最后全部匹配完, 如果还用该方法, 则返回 null
案例: 在 abc123qwer456sdf提取数字
var r = /d+/g;
r.exec( str ) => 123
r.exec( str ) => 456
r.exec( str ) => null
while ( res = r.exec( str ) ) {
// 操作 res, 处理捕获的结果
console.log(res);
console.log(res[0]); // 输出所有匹配字符串
}

十二、将匹配到的结果进行解析(正则表达式的强大之处:不仅能匹配出字符串,还能对匹配字符串进行操作)
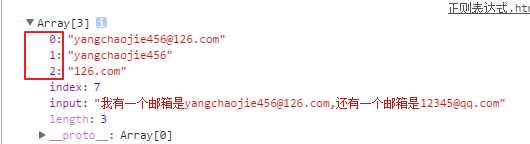
假如有一个字符串: yangchaojie456@126.com
匹配提取邮箱, 同时将邮箱地址部分的名字和主机名都提取出来
案例:
var str = '我有一个邮箱, 是 yangchoajie456@126.com, 还有 yangchaojie@163.com, 和 12345@qq.com'
要求将里面的邮箱全部提取出来, 然后将名字还有主机名也取出来
// 循环提取的正则表达式
var r = /[a-zA-Zd]+@[a-zA-Zd]+(.[a-zA-Zd]+)+/g;
// 如果需要将匹配到的结果再次分解, 可以使用分组的形式, 在正则中分组即可
var r = /([a-zA-Zd]+)@([a-zA-Zd]+(.[a-zA-Zd]+)+)/g;
// 注意, 正则表达式中, 分组是有编号的. 从左往右数 '('. 从 1 开始依次编号
// 匹配提取的结果中, 对应的编号就可以获得分解的数据


十三、 匹配但是不去捕获的元字符
(?:其他正则表达式内容)

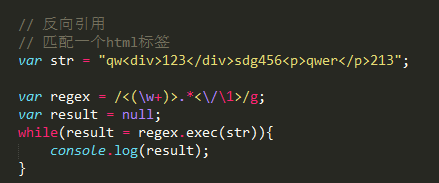
十四、反向引用
要截取一个字符串中的一个 html 标签
var str = '123<div>456</div>78<span>9</span>0';
1> 要截取 html 标签, 标签使用 <>. 因此正则表达式写成 <w+>
2> 与之匹配的标签名是什么?
如果在一个正则表达式中使用组匹配到某一个数据, 允许在该正则表达式中使用
'数字' 的方式引用该组
<(w+)>.*</1>
十五、贪婪模式
上面的例子有个问题
如果有两个<div>342</div>214<div>123</div>
将会这样匹配
凡是在正则表达式中, 涉及到次数限定的, 一般默认都是尽可能的多匹配.
取消贪婪模式. 在次数限定符后面加上 ?

注意: 贪婪模式性能会略高于非贪婪模式, 所以开发的时候. 一般不考虑贪婪的问题
只有代码匹配结果出现问题了, 一般一次多匹配了, 才会取消贪婪
多个贪婪在一起的时候的强度
d+d+d+
1234567
第一个d+将占12345
第二个d+将占6
第三个d+将占7
如果取消贪婪模式
d+?d+d+
第一个d+将占1
第二个d+将占23456
第三
个d+将占7
十六、否定元字符
语法:
[^字符]
不为这些字符的字符
[^abc] 不是 a 也不是 b 也不是 c 的字符
十七、 字符串的替换
语法:
字符串.replace( 查找字符串, 替换字符串 )
返回: 新字符串(替换结果)
1> 字符串替换方法
字符串1.replace( 字符串2, 字符串3 )
在 字符串1 中找到 字符串2, 将其替换成 字符串3, 返回替换后的字符串
特点: 只替换第一个找到的字符串
"aaa".replace( 'a', 'A' ) -> 'Aaa'
2> 正则替换
字符串.replace( 正则表达式, 字符串 )
返回:新字符串
1. 简单替换
'aaaaa-------bbbbbb------ccccc'.replace( /-+/, '-' )
结果:"aaaaa-bbbbbb------ccccc"
'aaaaa-------bbbbbb------ccccc'.replace( /-+/g, '-' )
结果:"aaaaa-bbbbbb-ccccc"
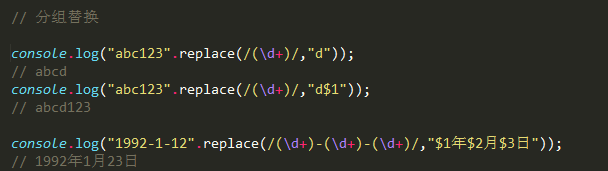
2. 分组替换
可以在替换字符串中, 使用 $数字 来引用替换的数据
'abc123'.replace( /(d+)/, 'd$1' ) -> 'abcd123'
'1991-1-1'
中国: 1991年1月1日
欧洲: 1/1/1991
... : 1991 1 1
'1991-1-19'.replace( /(d+)-(d+)-(d+)/, '$1年$2月$3日' )
3> 函数参数用法(了解)
语法:
字符串.replace( 正则表达式, fn )
// 根据匹配的数据用 函数fn操作 决定用什么替换
Fn 的参数 为 正则表达式中的 分组
第一个参数:与正则表达式匹配的全部字符串;
第二个参数:第一个分组;
第二个参数:第二个分组;
。。。。。。
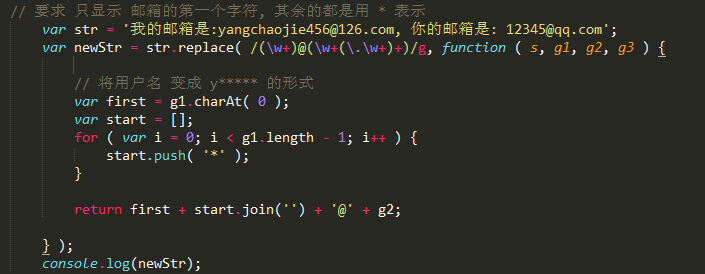
// 要求 只显示 邮箱的第一个字符, 其余的都是用 * 表示
var str = '我的邮箱是:yangchaojie456@126.com, 你的邮箱是: 12345@qq.com';
var newStr = str.replace( /(w+)@(w+(.w+)+)/g, function ( s, g1, g2, g3 ) {
// 将用户名 变成 y***** 的形式
var first = g1.charAt( 0 );
var start = [];
for ( var i = 0; i < g1.length - 1; i++ ) {
start.push( '*' );
}
return first + start.join('') + '@' + g2;
} );
console.log(newStr);