泛型
什么是泛型
泛型:广泛通用的类型
一开始还不确定是什么类型,在使用的时候,才能确定是什么类型
(1)在开始定义的时候,留一个插口
(2)在创建对象的时候,再去插入对应的类型
泛型也可以理解为“参数化类型”。一提到参数,最熟悉的就是定义方法时有形参,然后调用此方法时传递实参。
顾名思义,就是将类型由原来的具体的类型参数化,类似于方法中的变量参数,此时类型也定义成参数形式(可以称之为类型形参),然后在使用/调用时传入具体的类型(类型实参)。
泛型是为了参数化类型(在不创建新的类型的情况下,通过泛型指定的不同类型来控制形参具体限制的类型)。也就是说在泛型使用过程中,操作的数据类型被指定为一个参数,这种参数类型可以用在类、接口和方法中,分别被称为泛型类、泛型接口、泛型方法。
泛型的定义
泛型类:public class Demo<T> {} ,T表示未知类型。
泛型接口:public interface ImplDemo<T,V>{} ,和定义类一样(接口就是一个特殊类)。
泛型方法:public <T> void demo1(T name){ } , public <T> T demo2(T t){ return t;}
<>括号中,名字可以是任意的,通常使用 T:Type,E:Element,K:Key,V:Value。
代码模板中类型不确定,谁调用该段代码,谁就可以来指明这个类型。
如果没有指明泛型类型,它默认就是Object类型
泛型的好处
(1)编译时确定类型,保证类型安全,避免类型转换异常。
(2)避免了强制类型转换。
(3)代码利于重用,增加通用性。
泛型的本质
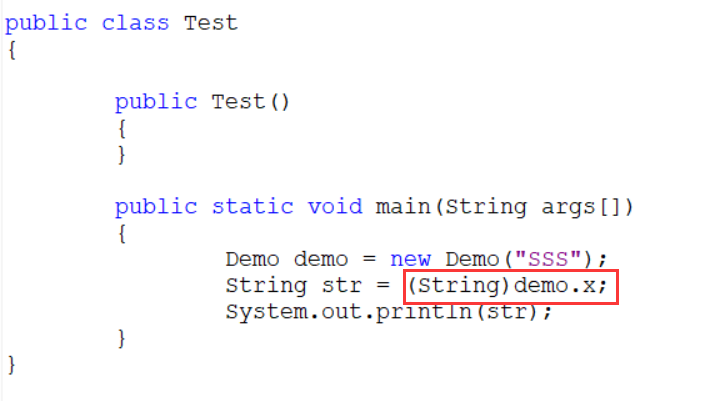
泛型其实是一个语法糖,本质还是Object,内部其实还是要做强转。
class Demo<T> {
T x;
public Demo(T x) {
this.x = x;
}
public T getX() {
return x;
}
}
public class Test {
public static void main(String[] args) {
Demo<String> demo = new Demo<>("SSS");
String str = demo.x;
System.out.println(str);
}
}
反编译后:
class Demo
{
Object x;
public Demo(Object x)
{
this.x = x;
}
public Object getX()
{
return x;
}
}
public class Test
{
public Test()
{
}
public static void main(String args[])
{
Demo demo = new Demo("SSS");
String str = (String)demo.x;
System.out.println(str);
}
}

泛型类和泛型方法
(1)泛型类
在类上面定义的泛型,class 类名<T>{},在创建对象的时候,要指明泛型的类型。
泛型类当中定义的泛型只能用在普通方法上面,不能使用在静态方法上面。
(2)泛型方法
就是在方法上面添加了泛型,是在使用方法时,参数传递确定具体的类型。
方法想要单独使用泛型,必须要有参数才有意义。
class Demo {
public <T> void demo1(T t) {
System.out.println(t.getClass());
}
public <T> T demo2(T t) {
System.out.println(t.getClass());
return t;
}
public static <T> void demo3(T t) {
System.out.println(t.getClass());
}
}
public class Test {
public static void main(String[] args) {
Demo demo = new Demo();
demo.demo1("str");// class java.lang.String
demo.demo1(10);// class java.lang.Integer
demo.demo1(10.5);// class java.lang.Double
Demo.demo3(true);// class java.lang.Boolean
}
}
泛型通配符
通配符:不知道使用什么类型来接收的时候,可以使用?表示未知。
(1)无边界的通配符
无边界的通配符的主要作用就是让泛型能够接受未知类型的数据。
public static void printList(List<?> list) {
for (Object o : list) {
System.out.println(o);
}
}
public static void main(String[] args) {
List<String> l1 = new ArrayList<>();
l1.add("aa");
l1.add("bb");
l1.add("cc");
printList(l1);
List<Integer> l2 = new ArrayList<>();
l2.add(11);
l2.add(22);
l2.add(33);
printList(l2);
}
这种使用 List<?> 的方式就是父类引用指向子类对象。注意,这里的printList方法不能写成public static void printList(List<Object> list)的形式,虽然Object类是所有类的父类,但是List<Object>跟其他泛型的List如List<String>, List<Integer>不存在继承关系,因此会报错。
我们不能对List<?>使用add方法,仅有一个例外,就是add(null)。 为什么呢?因为我们不确定该List的类型,不知道add什么类型的数据才对,只有null是所有引用数据类型都具有的元素
public static void addTest(List<?> list) {
list.add(new Object()); // 编译报错
list.add(1); // 编译报错
list.add("ABC"); // 编译报错
list.add(null);
}
public static void main(String[] args) {
List<?> list = new ArrayList<>();
addTest(list);
}
由于我们根本不知道list会接受到具有什么样的泛型List,所以除了null之外什么也不能add。
还有, List<?>也不能使用get方法,只有Object类型是个例外。 原因也很简单,因为我们不知道传入的List是什么泛型的,所以无法接受得到的get,但是Object是所有数据类型的父类,所以只有接受他可以。
public static void getTest(List<?> list) {
String s = list.get(0); // 编译报错
Integer i = list.get(1); // 编译报错
Object o = list.get(2);
}
public static void main(String[] args) {
List<?> list = Arrays.asList(1, 2, 3, 4);
getTest(list);
}
(2)固定上边界的通配符
用来限定元素的类型必须得指定类的子类(包括指定类和指定类的子类)
public static double sumOfList(List<? extends Number> list) {
double s = 0.0;
for (Number n : list) {
// 注意这里得到的n是其上边界类型的, 也就是Number, 需要将其转换为double.
s += n.doubleValue();
}
return s;
}
public static void main(String[] args) {
List<Integer> list1 = Arrays.asList(1, 2, 3, 4);
System.out.println(sumOfList(list1));
List<Double> list2 = Arrays.asList(1.1, 2.2, 3.3, 4.4);
System.out.println(sumOfList(list2));
}
List<? extends E> 不能使用add方法
public static void addTest2(List<? extends Number> l) {
// l.add(1); // 编译报错
// l.add(1.1); //编译报错
l.add(null);
}
泛型<? extends E>指的是E及其子类,这里传入的可能是Integer,也可能是Double,我们在写这个方法时不能确定传入的什么类型的数据,所以除了null之外什么也不能add。但是get的时候是可以得到一个Number, 也就是上边界类型的数据的,因为不管存入什么数据类型都是Number的子类型,得到这些就是一个父类引用指向子类对象。
(3)固定下边界的通配符
用来限定元素的类型必须得指定类的父类(包括指定类和指定类的父类)
public static void addNumbers(List<? super Integer> list) {
for (int i = 1; i <= 10; i++) {
list.add(i);
}
}
public static void main(String[] args) {
List<Object> list1 = new ArrayList<>();
addNumbers(list1);
System.out.println(list1);
List<Number> list2 = new ArrayList<>();
addNumbers(list2);
System.out.println(list2);
List<Double> list3 = new ArrayList<>();
addNumbers(list3); // 编译报错
}
List<? super E>是能够调用add方法的,因为我们在addNumbers所add的元素就是Integer类型的,而传入的list不管是什么,都一定是Integer或其父类泛型的List,这时add一个Integer元素是没有任何疑问的。但是, 我们不能使用get方法,因为我们所传入的类都是Integer的类或其父类,所传入的数据类型可能是Integer到Object之间的任何类型,这是无法预料的,也就无法接收。唯一能确定的就是Object,因为所有类型都是其子类型。
泛型的限制和规则
(1)泛型的类型参数只能是引用类型,不能使用值类型(是不会自动装箱的)。
(2)泛型的类型参数可以有多个。
(3)泛型前后类型必须得要保持一致,即 ArrayList<String> list = new ArrayList<String>(); 从JAVA7开始,后面的类型可以不写 ArrayList<String> list = new ArrayList<>(); 菱形语法。
(4)泛型类不是真正存在的类,不能使用instanceof运算符。
(5)泛型类的类型参数不能用在静态申明。
(6)如果定义了泛型,不指定具体类型,泛型默认指定为Ojbect类型。
(7)泛型使用?作为类型通配符,表示未知类型,可以匹配任何类型。因为是未知,所以无法添加元素。
(8)类型通配符上限:<? extends T>,?代表是T类型本身或者是T的子类型。常用于泛型方法,避免类型转换。
(9)类型通配符下限。<? super T>,?代表T类型本身或者是T的父类型。
除了通配符可以实现限制,类、接口和方法中定义的泛型参数也能限制上限和下限。
泛型擦除
泛型擦除:把泛型给去掉。
// 泛型擦除(把泛型给去掉)
List<String> list = new ArrayList<>();
list.add("aa");
List list2 = null;
list2 = list; // 把list当中的泛型给擦除掉
list2.add(10);
list2.add("bb");
System.out.println(list2);
Set 接口
常用方法
由 Collection 接口继承
/*
* 向 collection 中添加指定的元素,
* 如果添加成功返回 true,没有添加返回 false。
* 确保此 collection 包含指定的元素。
*/
boolean add(E e)
/*
* 将指定 collection 中的所有元素都添加到此 collection 中
* 如果此 collection 由于调用而发生更改,则返回 true。 否则返回 false。
*/
boolean addAll(Collection<? extends E> c)
// 移除此 collection 中的所有元素
void clear()
// 如果此 collection 包含指定的元素,则返回 true。否则返回 false。
boolean contains(Object o)
// 如果此 collection 包含指定 collection 中的所有元素,则返回 true。否则返回 false。
boolean containsAll(Collection<?> c)
/*
* 比较此 collection 与指定对象是否相等。
* 如果所定义的两个列表以相同的顺序包含相同的元素,则返回 true。
*/
boolean equals(Object o)
// 如果此 collection 不包含元素,则返回 true。
boolean isEmpty()
// 返回在此 collection 的元素上进行迭代的迭代器。
Iterator<E> iterator()
// 从此 collection 中移除指定元素的单个实例,如果存在的话,移除成功,则返回 true。
boolean remove(Object o)
/*
* 移除此 collection 中,此 collection和指定 collection的交集
* 如果此 collection 由于调用而发生更改,则返回 true
*/
boolean removeAll(Collection<?> c)
/*
* 把此 collection和指定 collection的交集赋值给调用者
* 如果此 collection 由于调用而发生更改,则返回 true
*/
boolean retainAll(Collection<?> c)
// 返回此 collection 中的元素数。
int size()
// 返回包含此 collection 中所有元素的数组
Object[] toArray()
// 返回包含此 collection 中所有元素的数组;返回数组的运行时类型与指定数组的运行时类型相同。
<T> T[] toArray(T[] a)
Set 接口特有
// 返回 set 的哈希码值。
int hashCode()
hashCode
1. Hash
Hash,一般翻译做散列、杂凑,或音译为哈希,是把任意长度的输入通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
Hash算法是一个广义的算法,也可以认为是一种思想,使用Hash算法可以提高存储空间的利用率,可以提高数据的查询效率,也可以做数字签名来保障数据传递的安全性。所以Hash算法被广泛地应用在互联网应用中。
Hash算法也被称为散列算法,Hash算法虽然被称为算法,但实际上它更像是一种思想。Hash算法没有一个固定的公式,只要符合散列思想的算法都可以被称为是Hash算法。
hash是一个函数,该函数中的实现就是一种算法,就是通过一系列的算法来得到一个hash值,这个时候,我们就需要知道另一个东西,hash表,通过hash算法得到的hash值就在这张hash表中,也就是说,hash表就是所有的hash值组成的,有很多种hash函数,也就代表着有很多种算法得到hash值。
2. hashcode
hashcode就是通过hash函数得来的,通俗的说,就是通过某一种算法得到的,hashcode就是在hash表中有对应的位置。每个对象都有hashcode,对象的hashcode怎么得来的呢?
首先一个对象肯定有物理地址,对象的物理地址跟这个hashcode地址不一样,hashcode代表对象的地址说的是对象在hash表中的位置,物理地址说的对象存放在内存中的地址,那么对象如何得到hashcode呢?通过对象的内部地址(也就是物理地址)转换成一个整数,然后该整数通过hash函数的算法就得到了hashcode,所以,hashcode是什么呢?就是在hash表中对应的位置。这里如果还不是很清楚的话,举个例子,hash表中有 hashcode为1、hashcode为2、(...)3、4、5、6、7、8这样八个位置,有一个对象A,A的物理地址转换为一个整数17(这是假如),就通过直接取余算法,17%8=1,那么A的hashcode就为1,且A就在hash表中1的位置。这里只是举个例子,知道什么是hashcode的意义。
简单的来说,每一个对象都会有一个hashcode,hashcode就是与内存地址对应的一个编号
3. hashcode有什么作用?
也许会问为什么hashcode不直接写物理地址呢,还要另外用一张hash表来代表对象的地址?
1、HashCode的存在主要是为了查找的快捷性,HashCode是用来在散列存储结构中确定对象的存储地址的(后半句说的用hashcode来代表对象就是在hash表中的位置)
为什么hashcode就查找的更快,比如:我们有一个能存放1000个数这样大的内存中,在其中要存放1000个不一样的数字,用最笨的方法,就是存一个数字,就遍历一遍,看有没有相同得数,当存了900个数字,开始存901个数字的时候,就需要跟900个数字进行对比,这样就很麻烦,很是消耗时间,用hashcode来记录对象的位置,来看一下。hash表中有1、2、3、4、5、6、7、8个位置,存第一个数,hashcode为1,该数就放在hash表中1的位置,存到100个数字,hash表中8个位置会有很多数字了,1中可能有20个数字,存101个数字时,他先查hashcode值对应的位置,假设为1,那么就有20个数字和他的hashcode相同,他只需要跟这20个数字相比较(equals),如果每一个相同,那么就放在1这个位置,这样比较的次数就少了很多,实际上hash表中有很多位置,这里只是举例只有8个,所以比较的次数会让你觉得也挺多的,实际上,如果hash表很大,那么比较的次数就很少很少了。
通过对原始方法和使用hashcode方法进行对比,我们就知道了hashcode的作用,并且为什么要使用hashcode了
4. equals方法和hashcode的关系
通过前面这个例子,大概可以知道,先通过hashcode来比较,如果hashcode相等,那么就用equals方法来比较两个对象是否相等,用个例子说明:上面说的hash表中的8个位置,就好比8个桶,每个桶里能装很多的对象,对象A通过hash函数算法得到将它放到1号桶中,当然肯定有别的对象也会放到1号桶中,如果对象B也通过算法分到了1号桶,那么它如何识别桶中其他对象是否和它一样呢,这时候就需要equals方法来进行筛选了。
1、如果两个对象equals相等,那么这两个对象的HashCode一定也相同
2、如果两个对象的HashCode相同,不代表两个对象就相同,只能说明这两个对象在散列存储结构中,存放于同一个位置
如果对象的equals方法被重写,那么建议对象的HashCode方法也尽量重写
Set去重原理
Set当中存的元素是无序,无重复的元素。
想要在Set当中自定义对象去重:覆盖equals和hashCode。如果两个自定义对象属性完全相同 ,那么就判定是同一个对象。
class Cat {
String name;
Cat(String name) {
this.name = name;
}
@Override
// 不覆盖hashCode,会帮你生成一个唯一的值(每次生成的值都不一样)
public int hashCode() {
// 如果属性相同,返回相同的hashCode; 属性不同,hashcode就不相同
System.out.println("执行了hashCode");
final int prime = 31;
int result = 1;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Cat other = (Cat) obj;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
@Override
public String toString() {
return "Cat [name=" + name + "]";
}
}
public class Test {
public static void main(String[] args) {
// hashCode每一个对象都 会一个hashCode
Cat c1 = new Cat("mm");
Cat c2 = new Cat("mm");
Set<Cat> s = new HashSet<>();
// 1.添加一个对象时,会调用对象的hashCode
s.add(c1);
// hashCode不相同,c2对象和集合当中的hashCode不相同,就不会调用equals
// 当hashCode相同的时候,会调用equals,如果equals返回为true,就不添加到集合当中
s.add(c2);
System.out.println(s);
}
}
LinkedHashSet
LinkedHashSet它是HashSet子类,所以能够保证元素的唯一。它底层是使用链表实现,是Set集合当中,唯一的一个保证元素的顺序,即按照将元素插入到 set 中的顺序(插入顺序)进行迭代。
HashSet<String> set1 = new HashSet<>();
set1.add("a");
set1.add("b");
set1.add("1");
set1.add("e");
System.out.println(set1); // [a, 1, b, e]
System.out.println("--------");
LinkedHashSet<String> set = new LinkedHashSet<>();
set.add("a");
set.add("b");
set.add("1");
set.add("e");
System.out.println(set); // [a, b, 1, e]
e.g. 字符串去重
public class Test {
public static void main(String[] args) {
// TODO Auto-generated method stub
Scanner sc = new Scanner(System.in);
System.out.println("请输入一行字符串");
String str = sc.nextLine();
fun2(str);
fun1(str);
System.exit(0);
}
private static void fun2(String str) {
char[] arr = str.toCharArray();
// 取出每一个元素,添加到一个可以去重的集合当中
LinkedHashSet<Character> hs = new LinkedHashSet<>();
for (char c : arr) {
hs.add(c);
}
String s = "";
for (Character ch : hs) {
s += ch;
}
System.out.println(s);
}
private static void fun1(String str) {
String s = ""; // 新建一个数组保存字符
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i); // 取出字符串中的字符数
if (s.indexOf(c) == -1) { // 判断新建数组中是否含有某个字符
s += c;
}
}
System.out.println(s);
}
}
TreeSet
TreeSet 可以保证元素唯一,无序(不是按照添加顺序展示),对添加的元素进行排序。
// 数字的大小
TreeSet<Integer> set = new TreeSet<Integer>();
set.add(10);
set.add(2);
set.add(2);
set.add(9);
set.add(6);
System.out.println(set);
// 按字母顺序
TreeSet<String> set2 = new TreeSet<String>();
set2.add("a");
set2.add("b");
set2.add("d");
set2.add("c");
set2.add("g");
System.out.println(set2);
// 汉字是按照unicode ->里面已经包含了Assic码
TreeSet<String> set3 = new TreeSet<String>();
set3.add("码");
set3.add("蚁");
set3.add("小");
set3.add("强");
System.out.println(set3);
System.out.println('码' + 0);
System.out.println('蚁' + 0);
System.out.println('小' + 0);
System.out.println('强' + 0);
// 按字母顺序
TreeSet<String> set4 = new TreeSet<String>();
set4.add("aa");
set4.add("ac");
set4.add("aba");
System.out.println(set4);
运行结果:
[2, 6, 9, 10]
[a, b, c, d, g]
[小, 强, 码, 蚁]
30721
34433
23567
24378
[aa, aba, ac]
TreeSet当中存放的类型必须得是同一类型,否则会报java.lang.ClassCastException异常
TreeSet set = new TreeSet();
set.add(10);
set.add("a");
TreeSet添加自定义对象
自定义的对象不能直接添加到TreeSet,想要添加到TreeSet当中必须要实现Comparable接口,覆盖当中的compareTo方法。
class Person implements Comparable<Person> {
String name;
int age;
Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
@Override
/*
* 如果返回0(和obj相等),所以只添加第一个元素
* 如果返回是一个正数(比obj大),都能添加到集合当中,顺序是插入的顺序
* 如果返回是一个负数(比obj小),都能添加到集合当中,顺序是插入的倒序
*/
public int compareTo(Person obj) {
return 1;
}
}
public class Test {
public static void main(String[] args) {
TreeSet<Person> set = new TreeSet<>();
set.add(new Person("张三", 20));
set.add(new Person("李四", 25));
set.add(new Person("王五", 22));
set.add(new Person("赵六", 21));
System.out.println(set);
System.exit(0);
}
}
TreeSet自定义对象按属性排序
class Person implements Comparable<Person> {
String name;
int age;
Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
@Override
/*
* 如果返回0,只添加第一个元素(非 Javadoc)
* 如果是一个正数,都能添加到集合当中,顺序是插入的顺序
* 如果是一个负数,都能添加到集合当中,顺序是插入的倒序
*/
public int compareTo(Person obj) {
int num = this.age - obj.age;
return num == 0 ? this.name.compareTo(obj.name) : num;
}
}
public class Test {
public static void main(String[] args) {
TreeSet<Person> set = new TreeSet<>();
set.add(new Person("张三", 20));
set.add(new Person("李四", 25));
set.add(new Person("王五", 22));
set.add(new Person("赵六", 21));
System.out.println(set);
System.exit(0);
}
}
TreeSet比较器
默认情况下,比较时会调用对象的compareTo进行比较,如果你传入比较器,就不会调用compareTo,就会使用你传入的比较器进行比较。
// 默认是使用字母的顺序进行比较
TreeSet<String> set = new TreeSet<String>();
set.add("aaaaaaaaaa");
set.add("z");
set.add("wc");
set.add("myxq");
set.add("cba");
System.out.println(set);
System.out.println("----------");
// 使用比较器进行比较
TreeSet<String> set2 = new TreeSet<String>(new Comparator<String>() {
// o1 代表当前对象
// o2 代表目标对象
@Override
public int compare(String o1, String o2) {
int lenght = o1.length() - o2.length(); // 主要是比长度
return lenght == 0 ? o1.compareTo(o2) : lenght; // 如果长度相等,再去比内容
}
});
set2.add("aaaaaaaaaa");
set2.add("z");
set2.add("wc");
set2.add("myxq");
set2.add("cba");
System.out.println(set2);
常用方法
// 返回此 set 中大于等于给定元素的最小元素;如果不存在这样的元素,则返回 null。
E ceiling(E e)
// 返回此 set 中严格大于给定元素的最小元素;如果不存在这样的元素,则返回 null。
E higher(E e)
// 返回此 set 中小于等于给定元素的最大元素;如果不存在这样的元素,则返回 null。
E floor(E e)
// 返回此 set 中严格小于给定元素的最大元素;如果不存在这样的元素,则返回 null。
E lower(E e)
// 返回此 set 中当前第一个(最低)元素。
E first()
// 返回此 set 中当前最后一个(最高)元素。
E last()
// 获取并移除第一个(最低)元素;如果此 set 为空,则返回 null。
E pollFirst()
// 获取并移除最后一个(最高)元素;如果此 set 为空,则返回 null。
E pollLast()
// 返回对此 set 中的元素进行排序的比较器;如果此 set 使用其元素的自然顺序,则返回 null。
Comparator<? super E> comparator()
// 返回在此 set 元素上按降序进行迭代的迭代器。
Iterator<E> descendingIterator()
// 返回此 set 中所包含元素的逆序视图。
NavigableSet<E> descendingSet()
// 返回此 set 的部分视图,其元素严格小于 toElement。
SortedSet<E> headSet(E toElement)
// 返回此 set 的部分视图,其元素小于(或等于,如果 inclusive 为 true)toElement。
NavigableSet<E> headSet(E toElement, boolean inclusive)
// 返回此 set 的部分视图,其元素大于等于 fromElement。
SortedSet<E> tailSet(E fromElement)
// 返回此 set 的部分视图,其元素大于(或等于,如果 inclusive 为 true)fromElement。
NavigableSet<E> tailSet(E fromElement, boolean inclusive)
// 返回此 set 的部分视图,其元素从 fromElement(包括)到 toElement(不包括)。
SortedSet<E> subSet(E fromElement, E toElement)
// 返回此 set 的部分视图,其元素范围从 fromElement 到 toElement。 boolean设置是否允许相等
NavigableSet<E> subSet(E fromElement, boolean fromInclusive, E toElement, boolean toInclusive)
Map 接口
Map : 映射关系(A->B),也可以说是双列集合。
有两个集合A集合和B集合(ArrayList、LinkedList、Vector、HashSet、LinkedHashSet、TreeSet)
A集合当中的每一元素,都可以在B集合当中找到一个唯一的一个值与之对应
A集合当中的元素不能重复(Set),A集合当中的每一个元素称它是一个key(键)
B集合当中的元素可以重复(List),B集合当中的每一个元素称它是一个Value(值)
Map可以当作是一个字典(dictionary),Map中的元素是entry对象(也叫键值对)
常用方法
// 返回此映射中的键-值映射关系数。
int size()
/*
* 将指定的值与此映射中的指定键关联(添加键值对、替换键的值)
* 如果此映射以前未包含一个该键的映射关系,则添加此映射关系,并返回null。
* 如果此映射以前包含一个该键的映射关系,则用指定值替换旧值,并返回旧值。
*/
V put(K key, V value)
// 从指定映射中将所有映射关系复制到此映射中
void putAll(Map<? extends K,? extends V> m)
// 只有当指定的key存在,才能替换指定键的值。返回旧值,如果没有键的映射,返回null。
default V replace(K key, V value)
/* 只有当指定的key存在,并且当前key映射到的值和指定的oldValue相同时,才能替换指定键的值。
* 如果该值被替换 ,返回true
*/
default boolean replace(K key, V oldValue, V newValue)
// 返回指定键所映射的值,如果此映射不包含该键的映射关系,则返回 null。
V get(Object key)
// 返回指定键所映射的值,如果此映射不包含该键的映射关系,则返回指定的默认值 defaultValue。
default V getOrDefault(Object key, V defaultValue)
// 如果此映射包含指定键的映射,则返回true。
boolean containsKey(Object key)
// 如果此映射有一个或多个键映射到指定的值,则返回true。
boolean containsValue(Object value)
// 返回此映射中entry对象的Set视图。
Set<Map.Entry<K,V>> entrySet()
// 返回此映射中包含的键的 Set 视图。
Set<K> keySet()
// 返回此映射中包含的值的 Collection 视图。
Collection<V> values()
// 如果此映射未包含键-值映射关系,则返回 true。
boolean isEmpty()
// 从该映射中删除所有的entry对象
void clear()
// 如果存在一个键的映射关系,则将其从此映射中移除,返回以前与 key 关联的值;如果没有 key 的映射关系,则返回 null。
V remove(Object key)
// 仅当指定的key存在,并且当前key映射到的值和指定的value相同时,删除该映射关系。
default boolean remove(Object key, Object value)
Map的遍历
Map当中没有迭代器,就不能使用快速遍历(foreach)
(1)通过keySet遍历
Map<String, Object> map = new HashMap<>();
map.put("key1", "value1");
map.put("key2", "value2");
map.put("key3", "value3");
map.put("key4", "value4");
map.put("key5", "value5");
// 取出所有的key
Set<String> keySet = map.keySet();
// Set集合是有迭代器的,可以是用快速遍历(foreach)
System.out.println("-----1. 迭代器遍历-----");
Iterator<String> it = keySet.iterator();
while (it.hasNext()) {
// 取出每一个key值
String key = it.next();
// 获取对应的value值
Object val = map.get(key);
System.out.println(key + " = " + val);
}
System.out.println("-----2. 快速遍历-----");
for (String key : keySet) {
System.out.println(key + " = " + map.get(key));
}
(2)通过entry遍历
Map<String, Object> map = new HashMap<>();
map.put("key1", "value1");
map.put("key2", "value2");
map.put("key3", "value3");
map.put("key4", "value4");
map.put("key5", "value5");
// 获取所有的entry对象(key-value对象)
// Entry是定义在map内部当中的一个接口
Set<Map.Entry<String, Object>> entrySet = map.entrySet();
System.out.println("-----1. 迭代器遍历-----");
Iterator<Entry<String, Object>> it = entrySet.iterator();
while (it.hasNext()) {
// 取出每一个entry对象
Entry<String, Object> en = it.next();
// 取出entry对象的key
String key = en.getKey();
// 取出entry对象的值
Object value = en.getValue();
System.out.println(key + " = " + value);
}
System.out.println("-----2. 快速遍历-----");
for (Entry<String, Object> entry : entrySet) {
System.out.println(entry.getKey() + " = " + entry.getValue());
}
HashMap 和 LinkedHashMap 和 TreeMap
(1)使用HashMap,它的key就是使用HashSet,是没有顺序的
(2)使用LinkedHashMap,它的key就是使用LinkedHashSet,是有顺序的(插入的顺序)
(3)使用TreeMap,它的key就是使用TreeSet,会对key进行排序。
HashMap<String, Integer> hm = new HashMap<>();
hm.put("b张三", 21);
hm.put("a李四", 22);
hm.put("c王五", 23);
System.out.println(hm); // {a李四=22, c王五=23, b张三=21}
LinkedHashMap<String, Integer> lhm = new LinkedHashMap<>();
lhm.put("b张三", 21);
lhm.put("a李四", 22);
lhm.put("c王五", 23);
System.out.println(lhm); // {b张三=21, a李四=22, c王五=23}
TreeMap<String, Integer> thm = new TreeMap<>();
thm.put("b张三", 21);
thm.put("a李四", 22);
thm.put("c王五", 23);
System.out.println(thm); // {a李四=22, b张三=21, c王五=23}
e.g. 统计字符串中每个字符出现的次数
这里给出三种解法
public static void main(String[] args) {
String str = "aaabbacccAAoooppp";
System.out.println(str);
countByMap(str);
countByString(str);
countByList(str);
}
private static void countByList(String str) {
List<Character> list = new ArrayList<>();
char[] chars = str.toCharArray(); // 将字符串转化成字符数组
for (char c : chars) {
list.add(c); // 将字符数组元素添加到集合中
}
String res = "[";
for (Character ch : list) { // 遍历集合取出每个字符
int count = 0; // 定义计数器
if (ch == null)
continue;
for (int i = 0; i < chars.length; i++) { // 遍历数组取出每个字符和集合中的元素比较
char c = chars[i];
if (ch.equals(c)) { // 如果集合中的元素有等于数组中的字符, 计数器加1
count++;
list.set(i, null);
}
}
res += ch + "=" + count + ", ";
}
res = res.substring(0, res.length() - 2) + "]";
System.out.println(res);
}
public static void countByMap(String str) {
LinkedHashMap<Character, Integer> hm = new LinkedHashMap<>();
char[] arr = str.toCharArray(); // 把字符串转成一个数组
for (char c : arr) { // 从数组当取出每一个字符出来
if (!hm.containsKey(c)) { // 判断一下,该元素是否在map当中存储key
hm.put(c, 1); // 如果没有,把当前的字符当作key存起,value 1
} else {
hm.put(c, hm.get(c) + 1); // 如果已经有了 就去修改对应的value 在原来value上加1
}
}
System.out.println(hm);
}
public static void countByString(String str) {
int count = 0; // 统计单个字符出现的次数
String res = "[";
while (str.length() > 0) {
int len = str.length();
char c = str.charAt(0);
String newStr = str.replaceAll(c + "", ""); // 每次统计完会将统计过的字符替换掉
int newLen = newStr.length();
count = len - newLen; // 旧的长度减去新的长度就是字符出现的次数
str = newStr;// 将替换并统计过次数的字符串赋给原来的字符串,便于下一次遍历
res += c + "=" + count + ", ";
}
res = res.substring(0, res.length() - 2) + "]";
System.out.println(res);
}