通常Apache kafka应用在两类程序:
(1)建立实时的数据管道,以可靠地在系统或应用程序之间获取数据
(2)构建实时流应用程序,以转换或响应数据流
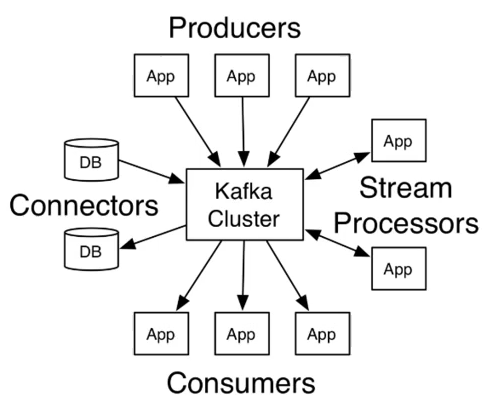
如图,可以看到:
(1)producers:可以有很多的应用程序,将消息数据放到kafka的集群中。
(2)Consumers:可以有很多的应用程序,将消息数据从kafka集群中拉取出来。
(3)Connectors:kafka的连接器可以将数据库中数据导入到kafka,也可以从kafka中导出数据到数据库中。
(4)Stream processors:流处理器可以从kafka中拉取数据,也可以将数据写入到kafka中。