elasticsearch环境搭建及单节点搭建可参考我的上一篇:http://www.cnblogs.com/xuwenjin/p/8745624.html
本文以Elaticsearch 6.2.2 版本为基础,讲解Elasticsearch三个节点的分布式部署、核心配置的含义以及分布式部署遇到的坑
楼主是在一台机器上配置的,所有下面的network.host全部配置同一IP
1、配置节点
1.1配置主节点:
#集群名称 cluster.name: xwj #节点名称 node.name: master
#是否参与master选举 node.master: true #绑定的ip network.host: 127.0.0.1 #默认端口 http.port: 9200 #解决跨域-这样head插件就可以访问 http.cors.enabled: true http.cors.allow-origin: "*"
1.2 将elasticsearch的压缩包解压两次,分别解压到两个文件夹中。然后分别修改配置文件
随从节点slave1的配置:
#集群名称 cluster.name: xwj #节点名称 node.name: slave1 #绑定的ip network.host: 127.0.0.1 #默认端口已使用,这里用新的端口 http.port: 9201 #发现主节点(通过主节点的ip) discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
随从节点slave2跟节点slave1配置很像,就端口号和节点名称不一样。如下图:
#集群名称 cluster.name: xwj #节点名称 node.name: slave2 #绑定的ip network.host: 127.0.0.1 #默认端口已使用,这里用新的端口 http.port: 9202 #发现主节点(通过主节点的ip) discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
2、启动服务
2.1 启动主节点,会发现节点名称为master为主节点
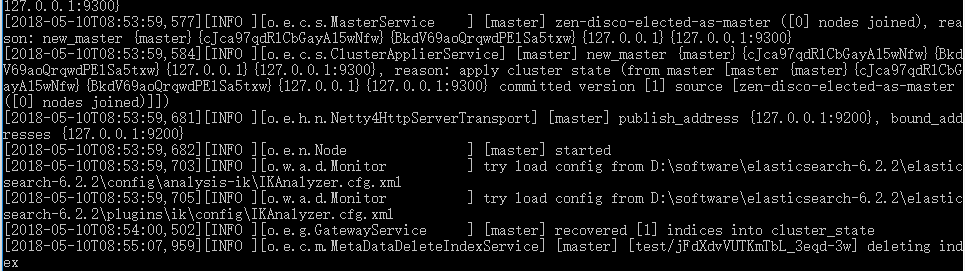
2.2 分别启动slave1和slave2

在slave启动的过程中,通过上面打印信息,可以看到slave1发现了主节点master及另一个随从节点slave2(先启动)。此时主节点也会发现另两个节点加入进来
2.3 部署成功示例:
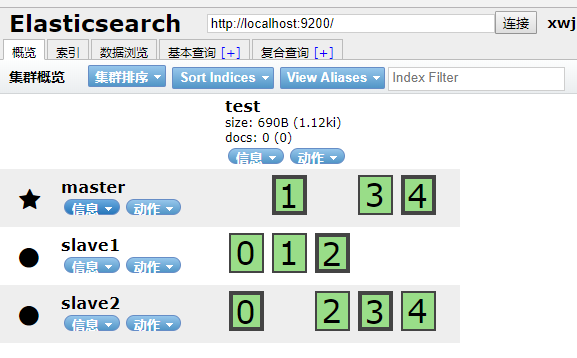
五角星的为主节点,圆点的为随从节点。
默认5个分片,一个备份(粗线框框为分片,细线的为备份分片)。可以看到,三个节点平均分配所有分片及备份
3、部署节点原理
多机集群中的节点可以分为master nodes和data nodes,在配置文件中使用Zen发现(Zen discovery)机制来管理不同节点。Zen发现是ES自带的默认发现机制,使用
多播发现其它节点。只要启动一个新的ES节点并设置和集群相同的名称这个节点就会被加入到集群中。(所以,同集群的集群名称一致,才能便于自动发现)
Elasticsearch集群中有的节点一般有三种角色:master node、data node和client node。
1)master node——master节点点主要用于元数据(metadata)的处理,比如索引的新增、删除、分片分配等。
2)data node——data 节点上保存了数据分片。它负责数据相关操作,比如分片的 CRUD,以及搜索和整合操作。这些操作都比较消耗 CPU、内存和 I/O 资源;
2)client node——client 节点起到路由请求的作用,实际上可以看做负载均衡器。
4、其它参数含义
#分片数和副本数
index.number_of_shards: 5
index.number_of_replicas: 1
#master选举最少的节点数,这个一定要设置为N/2+1,其中N是:具有master资格的节点的数量,而不是整个集群节点个数
discovery.zen.mininum_master_nodes: 2
#discovery ping的超时时间,拥塞网络,网络状态不佳的情况下设置高一点
discovery.zen.ping.timeout: 3s
#关闭自动发现节点
discovery.zen.ping.multicast.enabled: false
#定义发现的节点
discovery.zen.ping.unicast.hosts: ["192.168.1.1:9201", "192.168.1.1:9202"]注意:分布式系统整个集群节点个数N要为奇数个!!
5、踩过的坑:
1、增加节点时,直接将启动成功的elasticsearch文件夹拷贝,然后修改配置文件。这样在启动的时候,会报已有一个相同节点id却不同实例,导致无法进入到集
群中
原因:成功启动后,会在data文件目录下,生成该节点的信息
正确做法:解压elasticsearch的压缩包,然后再改配置文件。或者复制后,删除data文件目录下的数据