1、cookie不属于http协议范围,由于http协议无法保持状态,但实际情况,我们却又需要“保持状态”,因此cookie就是在这样一个场景下诞生。
cookie的工作原理是:由服务器产生内容,浏览器收到请求后保存在本地;当浏览器再次访问时,浏览器会自动带上cookie,这样服务器就能通过cookie的内容来判断这个是“谁”了。
2、cookie虽然在一定程度上解决了“保持状态”的需求,但是由于cookie本身最大支持4096字节,以及cookie本身保存在客户端,可能被拦截或窃取,因此就需要有一种新的东西,它能支持更多的字节,并且他保存在服务器,有较高的安全性。这就是session。
问题来了,基于http协议的无状态特征,服务器根本就不知道访问者是“谁”。那么上述的cookie就起到桥接的作用。
我们可以给每个客户端的cookie分配一个唯一的id,这样用户在访问时,通过cookie,服务器就知道来的人是“谁”。然后我们再根据不同的cookie的id,在服务器上保存一段时间的私密资料,如“账号密码”等等。
3、总结而言:cookie弥补了http无状态的不足,让服务器知道来的人是“谁”;但是cookie以文本的形式保存在本地,自身安全性较差;所以我们就通过cookie识别不同的用户,对应的在session里保存私密的信息以及超过4096字节的文本。
4、另外,上述所说的cookie和session其实是共通性的东西,不限于语言和框架
前几节的介绍中我们已经有能力制作一个登陆页面,在验证了用户名和密码的正确性后跳转到后台的页面。但是测试后也发现,如果绕过登陆页面。直接输入后台的url地址也可以直接访问的。这个显然是不合理的。其实我们缺失的就是cookie和session配合的验证。有了这个验证过程,我们就可以实现和其他网站一样必须登录才能进入后台页面了。
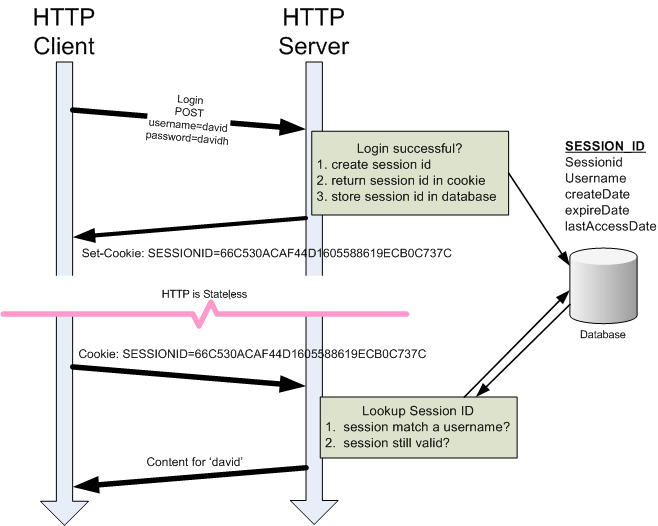
先说一下这种认证的机制。每当我们使用一款浏览器访问一个登陆页面的时候,一旦我们通过了认证。服务器端就会发送一组随机唯一的字符串(假设是123abc)到浏览器端,这个被存储在浏览端的东西就叫cookie。而服务器端也会自己存储一下用户当前的状态,比如login=true,username=hahaha之类的用户信息。但是这种存储是以字典形式存储的,字典的唯一key就是刚才发给用户的唯一的cookie值。那么如果在服务器端查看session信息的话,理论上就会看到如下样子的字典
{'123abc':{'login':true,'username:hahaha'}}
因为每个cookie都是唯一的,所以我们在电脑上换个浏览器再登陆同一个网站也需要再次验证。那么为什么说我们只是理论上看到这样子的字典呢?因为处于安全性的考虑,其实对于上面那个大字典不光key值123abc是被加密的,value值{'login':true,'username:hahaha'}在服务器端也是一样被加密的。所以我们服务器上就算打开session信息看到的也是类似与以下样子的东西
{'123abc':dasdasdasd1231231da1231231}
借用一张别的大神画的图,可以更直观的看出来cookie和session的关系