序列化:转向一个字符串数据类型
序列 ———— 字符串
序列化和反序列化的概念:

序列化三种方法:json pickle shelve

json模块:json模块提供了四个方法dumps和loads、dump和load
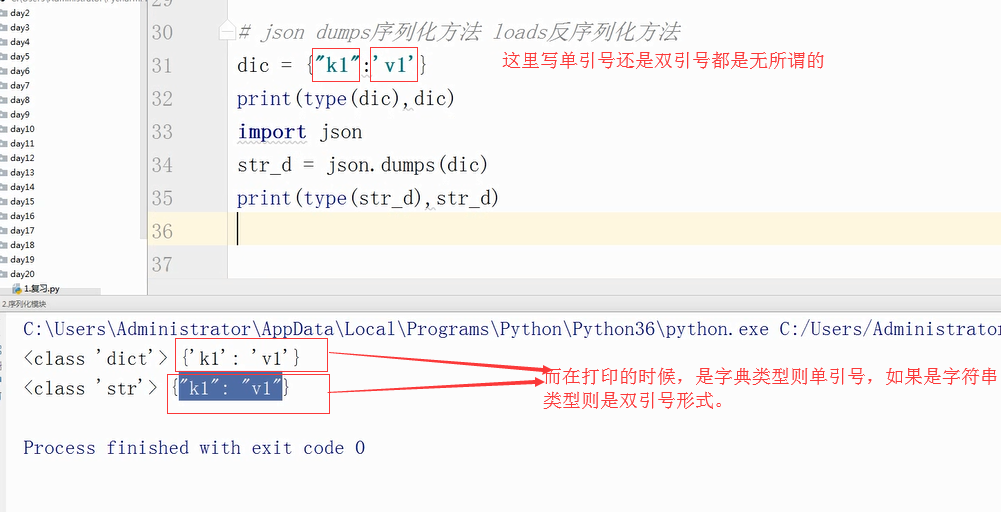
json dumps序列化方法(将其他数据类型转化成字符串类型) loads反序列化方法
dumps和loads直接操作内存中的数据类型
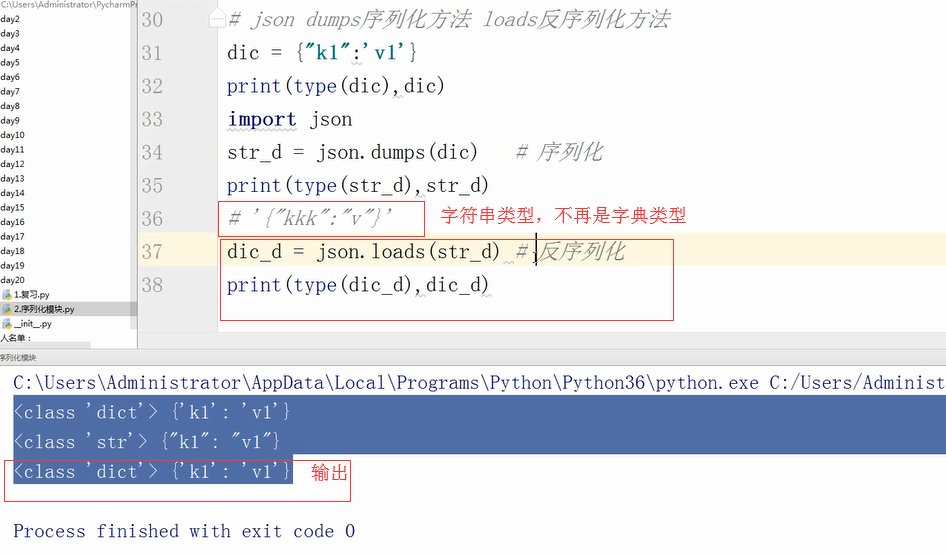
json loads反序列化方法(将字符串类型转回原来的类型)
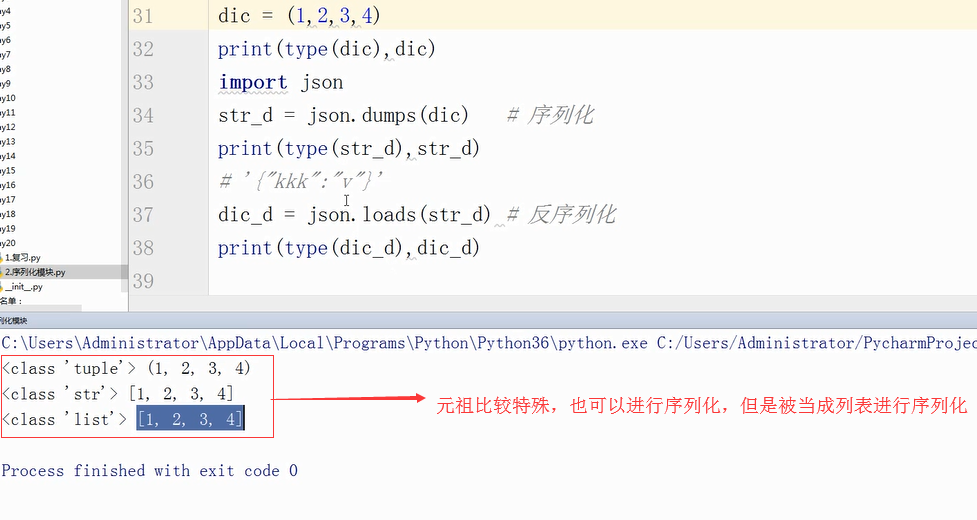
json可以进行序列化的数据类型有:数字、字符串、列表、字典、元组
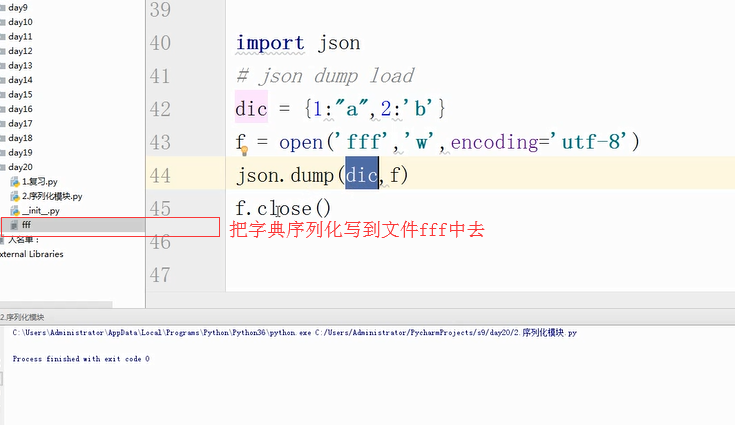
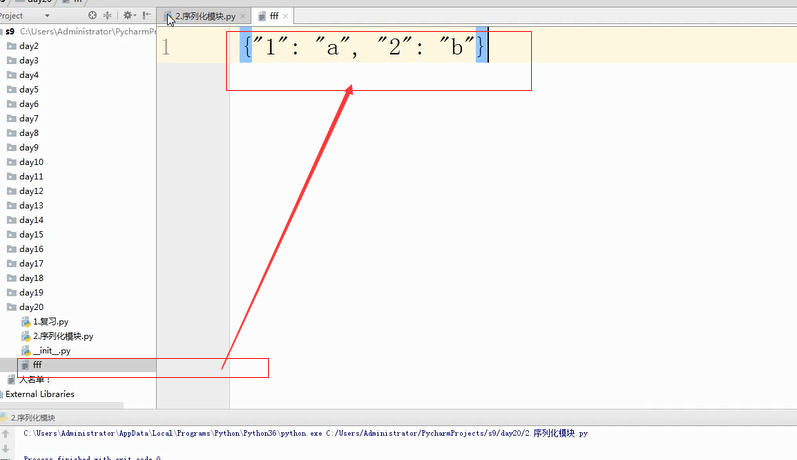
json dump序列化方法(对文件进行操作) load反序列化方法(对文件进行操作)
dump和load是往文件里面写和从文件中读,是一次性读完或一次性写完,如果文件中有多个字典就会报错
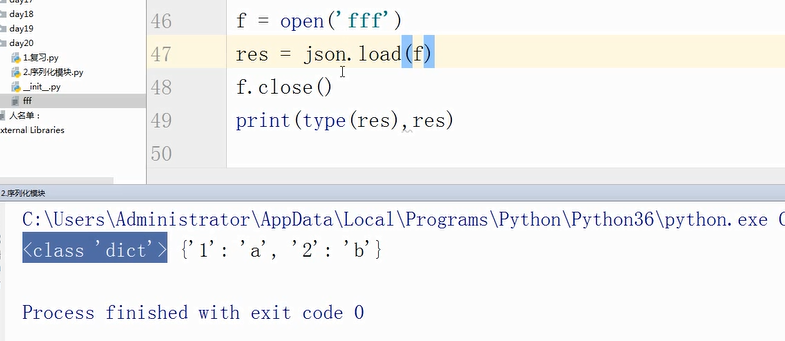
json load反序列化方法(对文件进行操作)
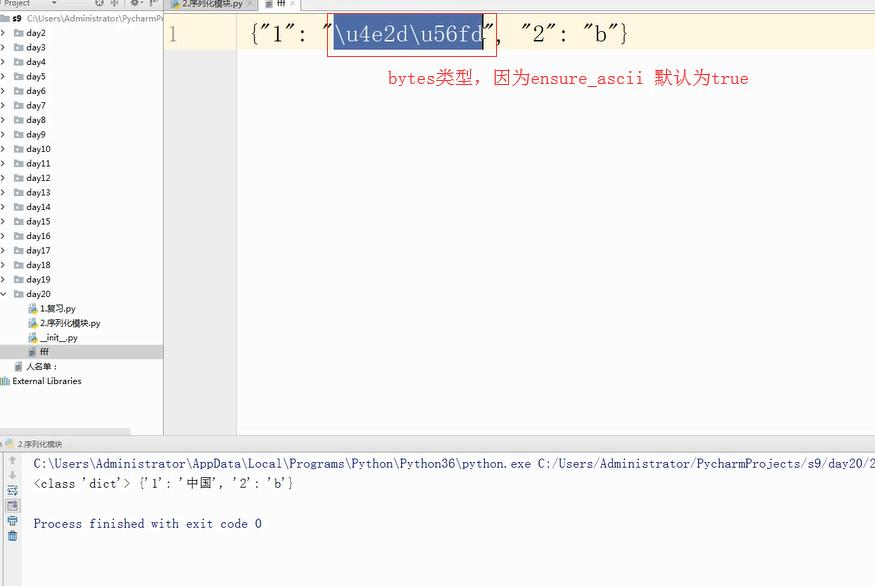
解决中文dump序列化时往文件中写的是bytes类型的问题:
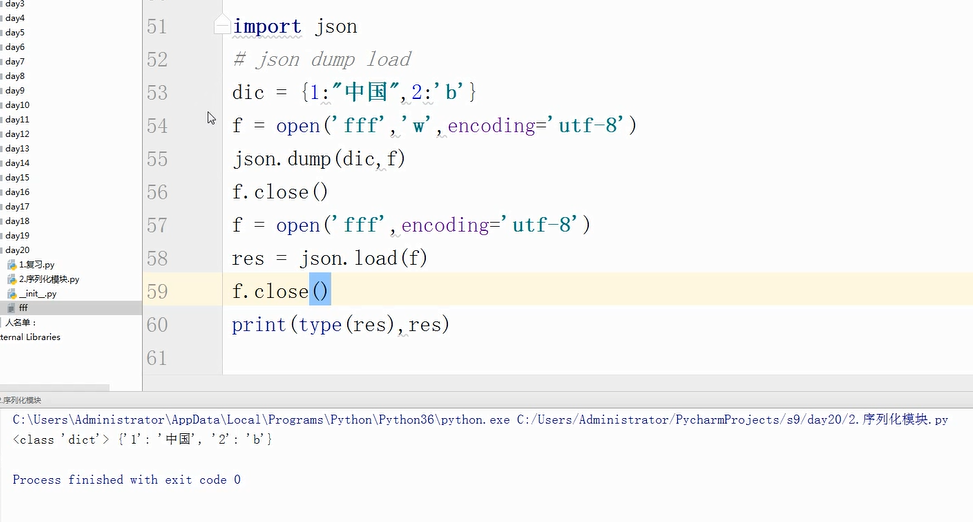
输出:
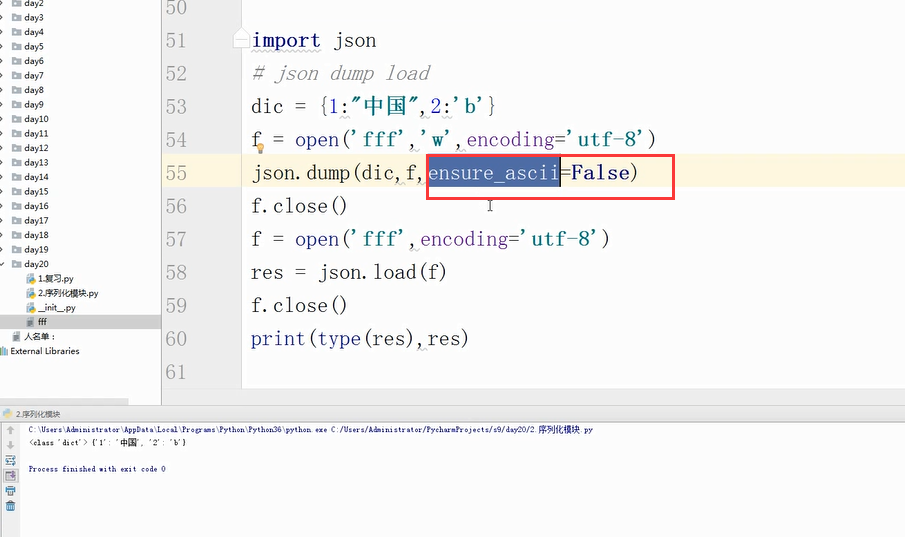
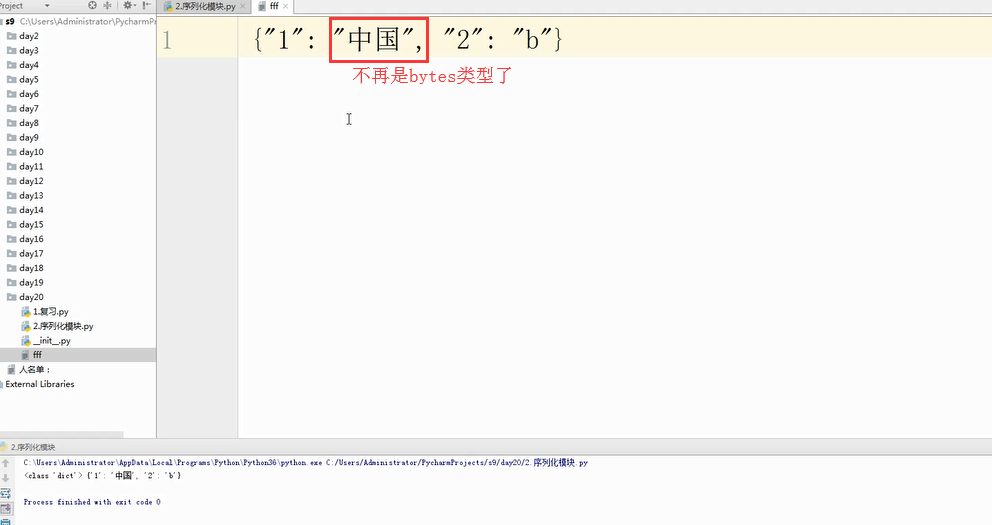
解决方法:
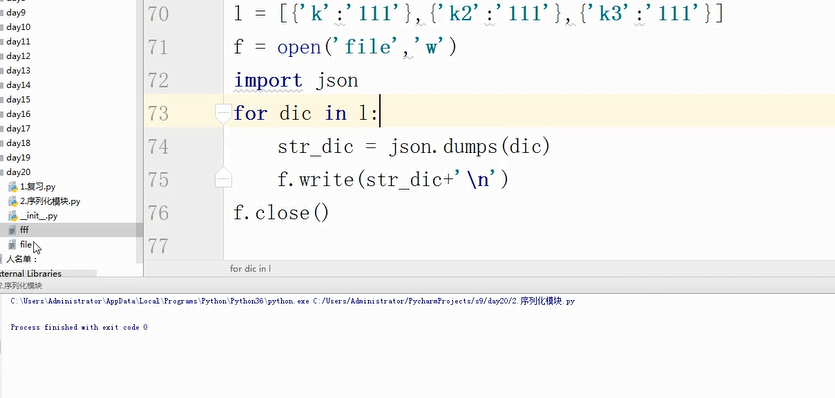
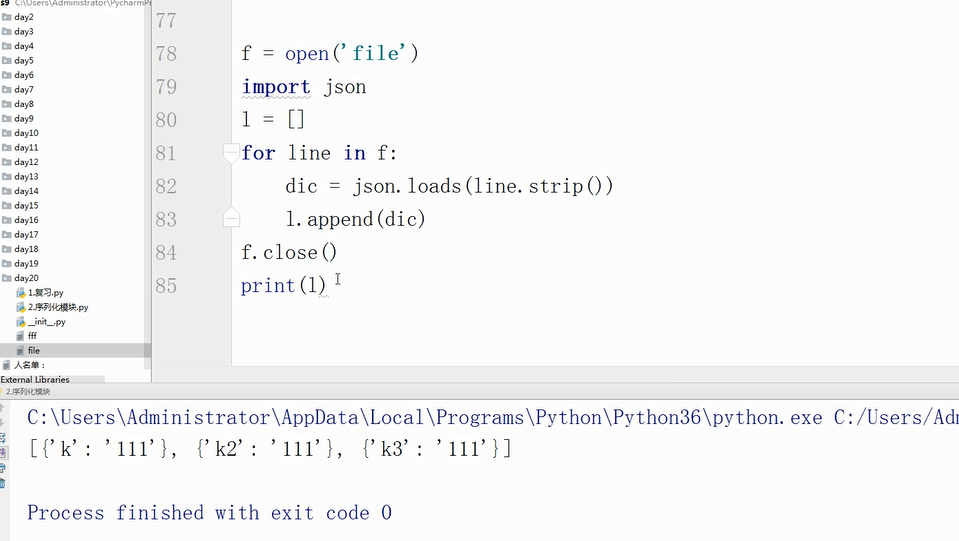
文件中多个字典的数据的读和写:
写:
读:
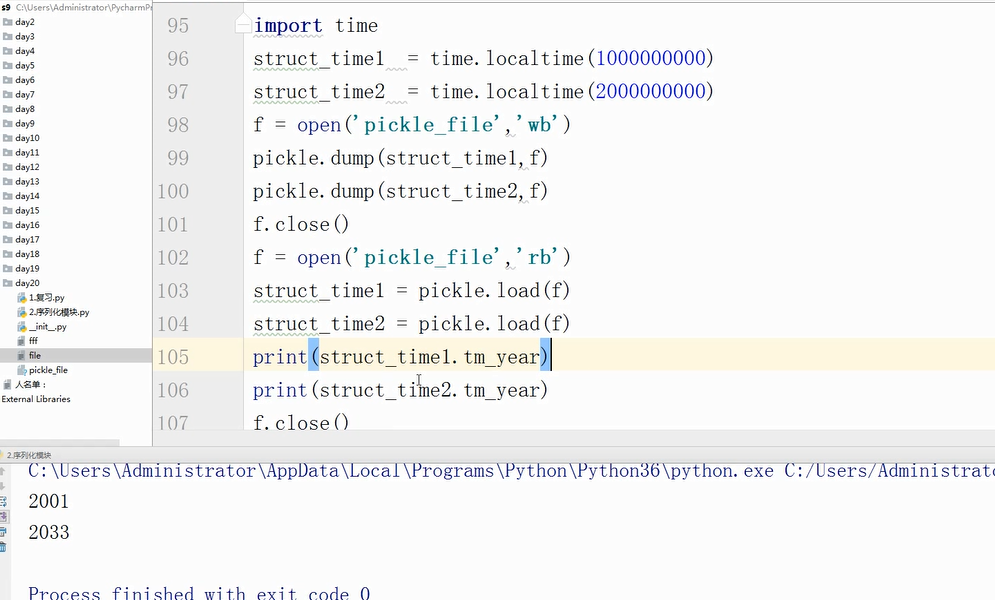
pickle模块:(只有Python可以使用)和json模块一样提供了四个方法dumps和loads、dump和load
picke的dumps和loads方法
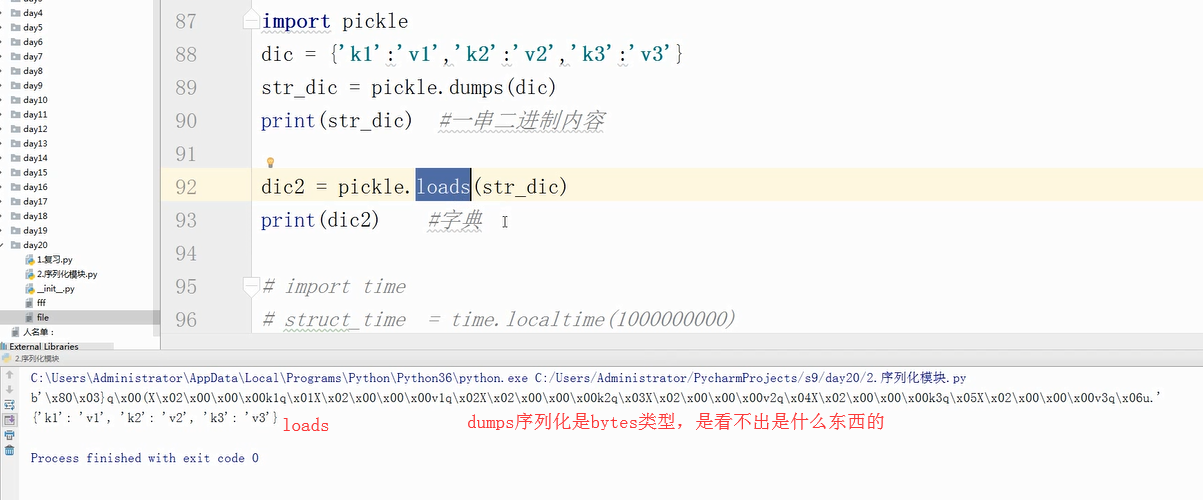
picke的dump和load方法
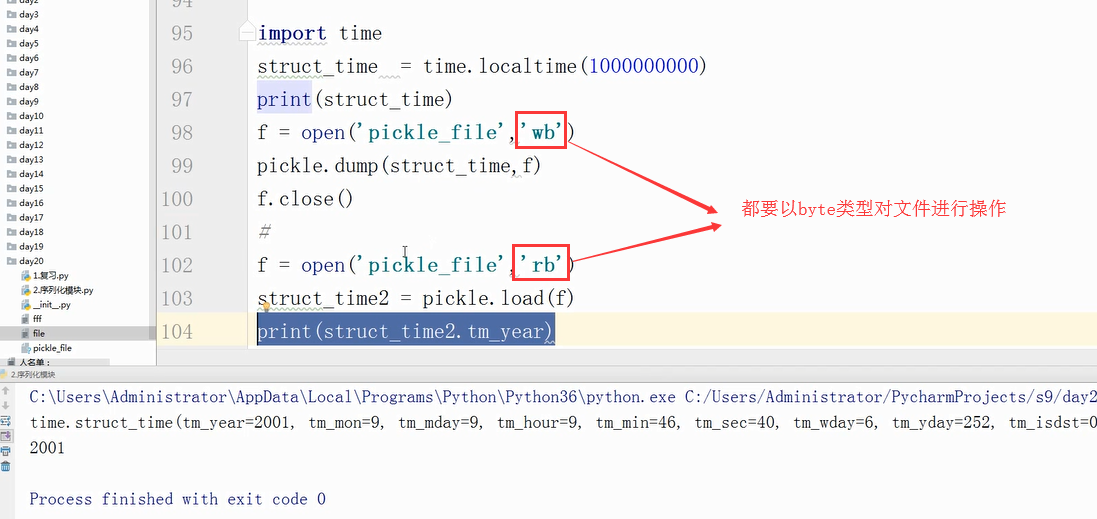
对于pickle可以分步地dump和load,而对于json就不行了,json不直接支持
shelve模块:写时直接对文件句柄进行操作,取出数据时也只需要直接用key获取即可(自己从文件中也看不出来写了什么) (和json、pickle都不一样)
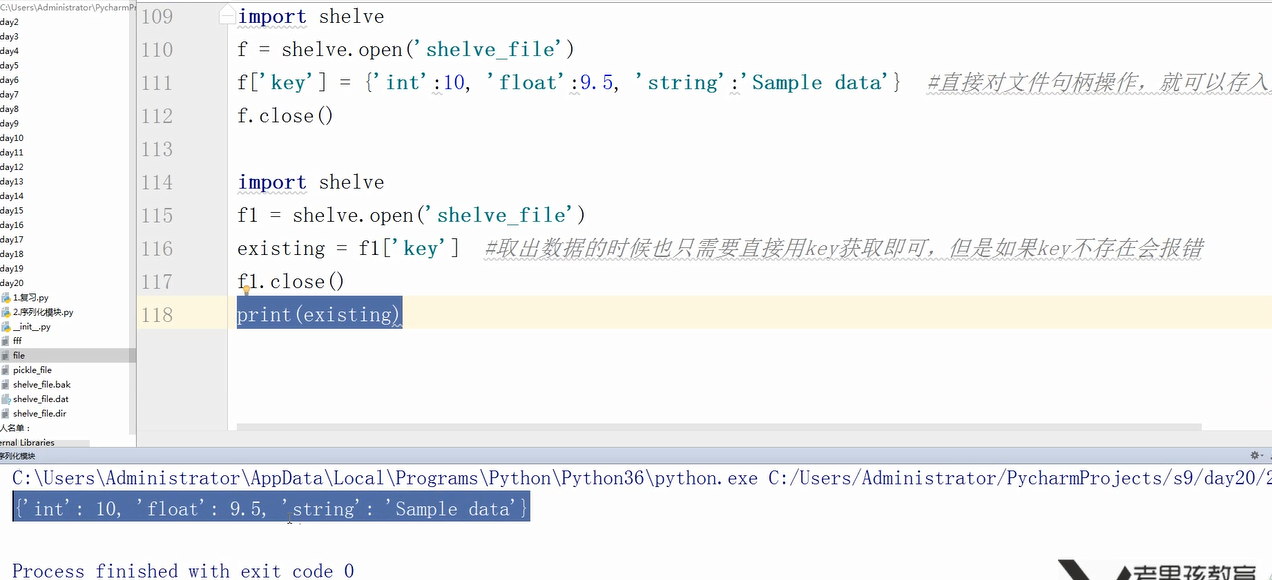
总结:只有json在文件中的数据对我们来说是透明的,pickle和shelve在文件中的数据对我们来说是看不懂的
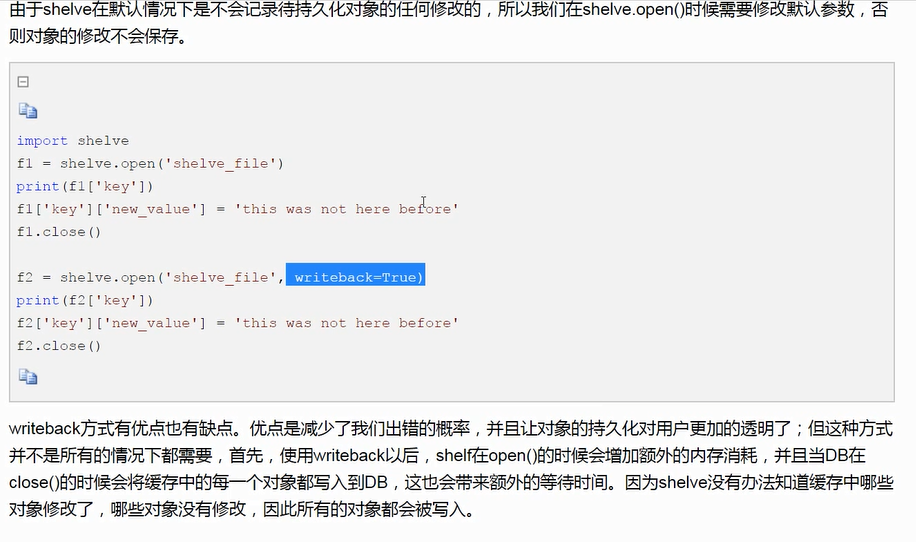
wirteback: