Python3网络爬虫:requests爬取动态网页内容
Python版本:python3.+
运行环境:OSX
IDE:pycharm
一、工具准备
抓包工具:在OSX下,我使用的是Charles4.0
- 下载链接以及安装教程:http://www.sdifen.com/charles4.html
- 安装完成后,要给Charles安装证书,Mac上使用Charles对https请求抓包–安装Root Certificate中前半部分讲的就是Charles安装证书的步骤,后半部分是设置抓取手机包的步骤,在这我们用不到
代理工具:chrome插件 SwitchOmega
- 由于Charles的工作原理是以自身作为代理,让比如chrome浏览器通过该代理来进行收发数据,以此达到抓包的目的。我们可以通过chrome设置来代理,但是chrome插件 SwitchOmega能够让我们方便地自由切换代理,以此达到高效,快捷的生活。(笑)
SwitchOmega使用方法
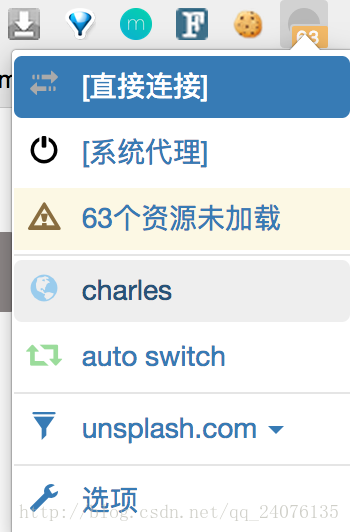
- 安装完插件,如图,点击选项
- 点击新建情景模式
- 自定义一个名字,选择代理服务器,点击创建
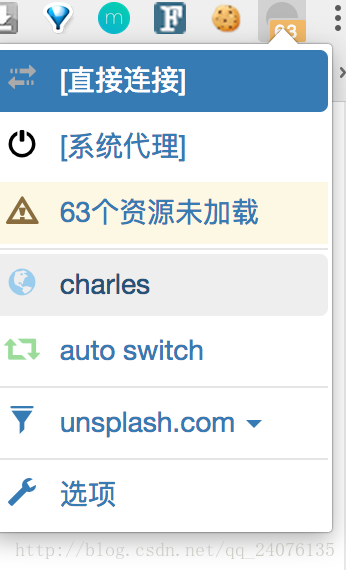
- 代理协议填
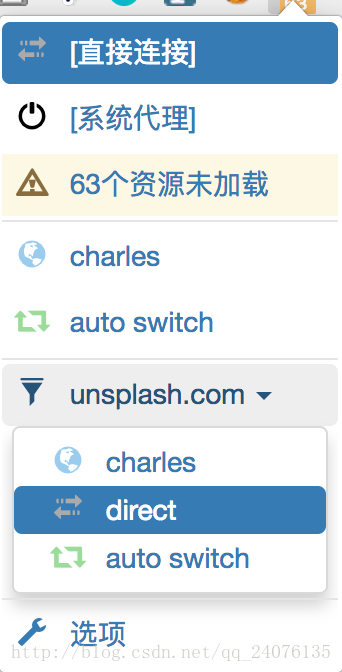
http,代理服务器填127.0.0.1,代理端口填8888,点击应用选项,会提示保存成功 - 退出到首页,在目标网页(https://unsplash.com/)下,如图,可以通过选择我们设置好的charles来设置全局代理(所有网站的数据请求都通过代理)
- 也可以通过仅为该网站设置代理
二、知识储备
requests.get():requests官方文档
在这里,request.get()中我是用到了 verify=False,stream=True这两个额外参数
verify = False能越过网站的SSL验证
stream=True保持流的开启,直到流的关闭。在下载图片过程中,能让图片在完全下载下来之前保持数据流不关闭,以保障图片下载的完全性。如果去掉该参数再下载图片,则会发现图片无法下载成功。
contextlib.closing():contextlib库下的closing方法,功能是将对象变成上下文对象,以此来支持with。
使用过 with open() 就知道 with的好处是能帮我们自动关闭资源对象,以此来简化代码。而实际上,任何对象,只要正确实现了上下文管理,就可以用于with语句。这里还有一篇关于with语句与上下文管理器
三、思路整理
这次抓取的动态网页是个壁纸网站,上面有精美的壁纸,我们的目的就是通过爬虫,把该网站上的壁纸原图下载到本地
网站url:https://unsplash.com/
已知该网站是动态网站,那就需要通过抓取网站的js包来分析,它是如何获得数据的。
- 通过Charles来获取打开网站时的请求
- 从中查找到有用的json
- 从json中的数据,比较下载链接的url,发现,下载链接变化部分就是图片的id
- 从json中爬出图片id,在下载链接上填充id部分,执行下载操作
四、具体步骤
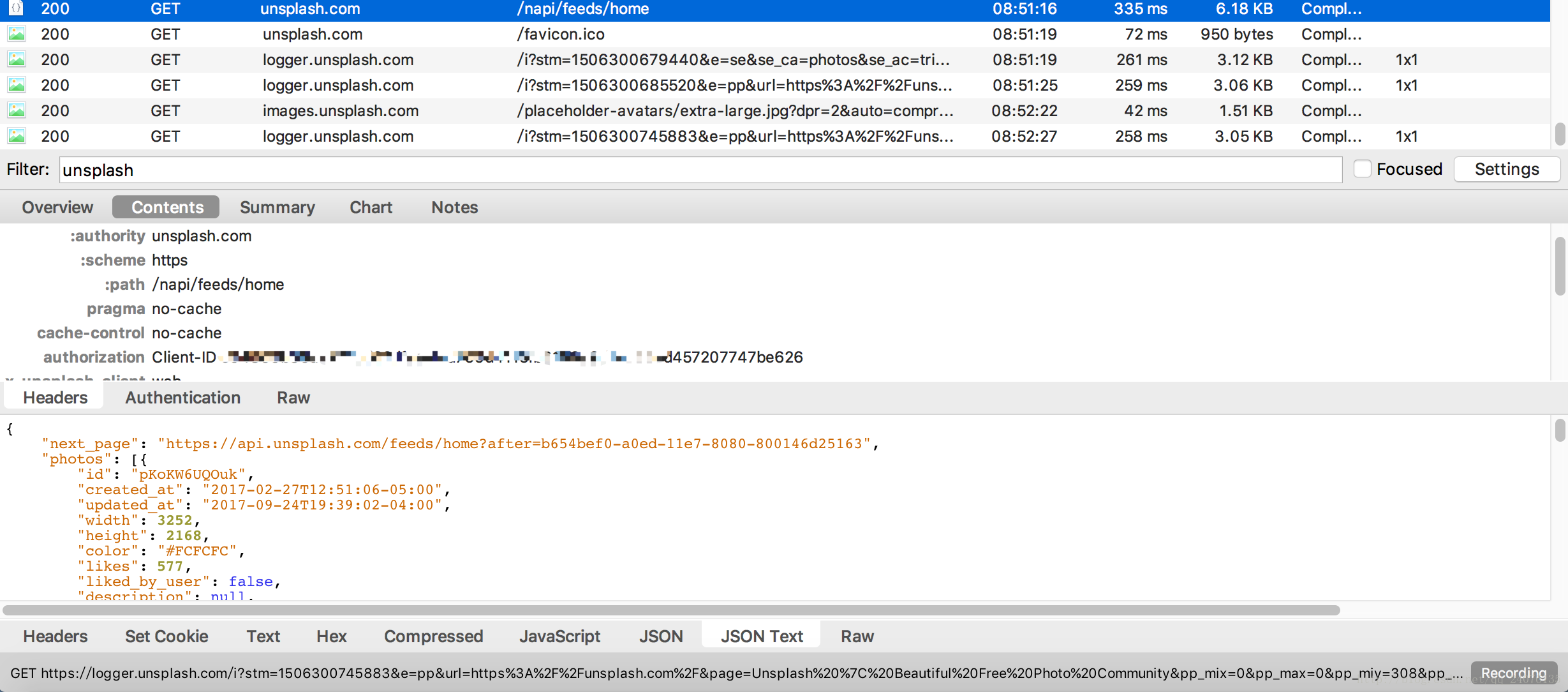
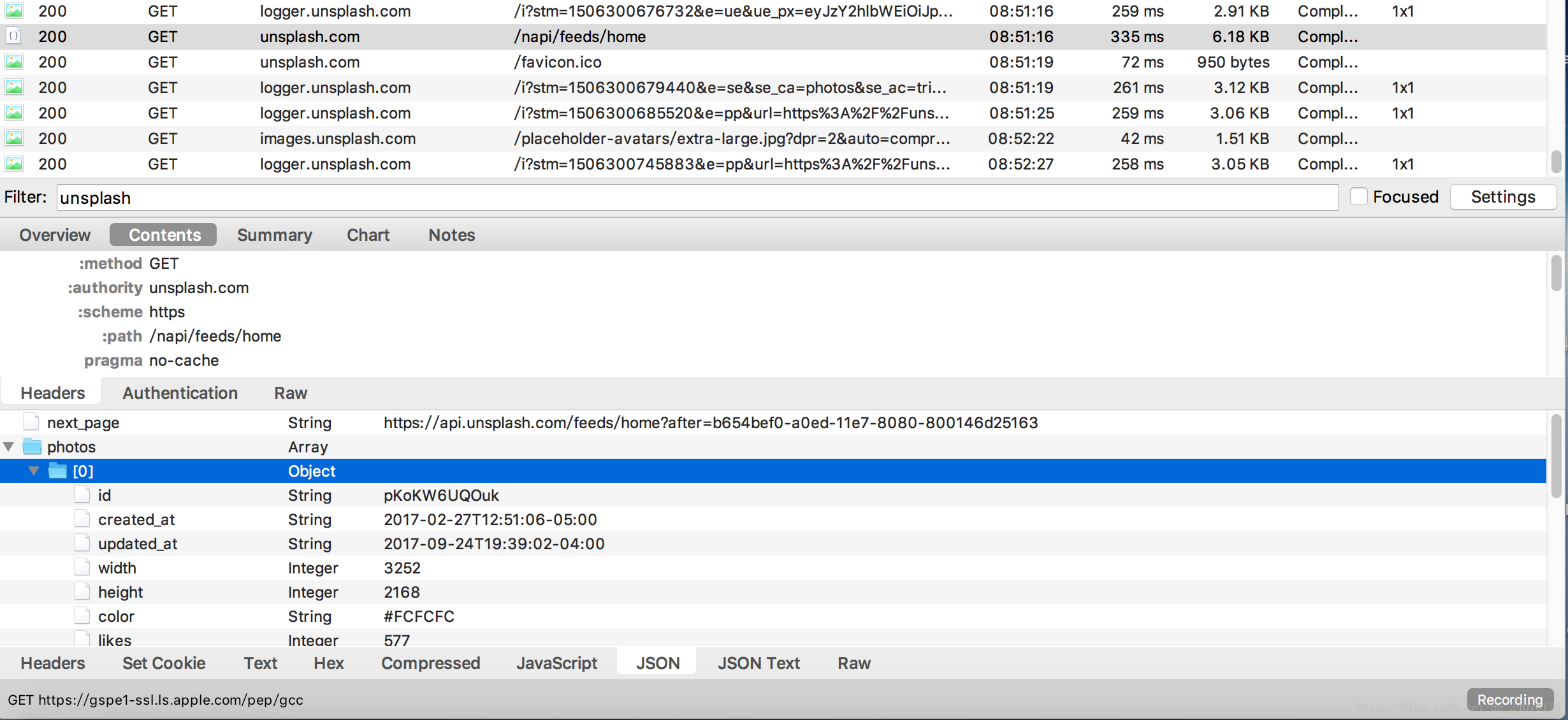
- 通过Charles来获取打开网站时的请求,如图
从图中不难发现在headers中有一个authorization Client-ID的参数,这需要记下来,加在我们自己的请求头中。(由于是学习笔记的原因,该参数已知为反爬虫所需要的参数,具体检测反爬的操作,估计可以自己添加参数一个一个尝试) - 从中查找到有用的json
在
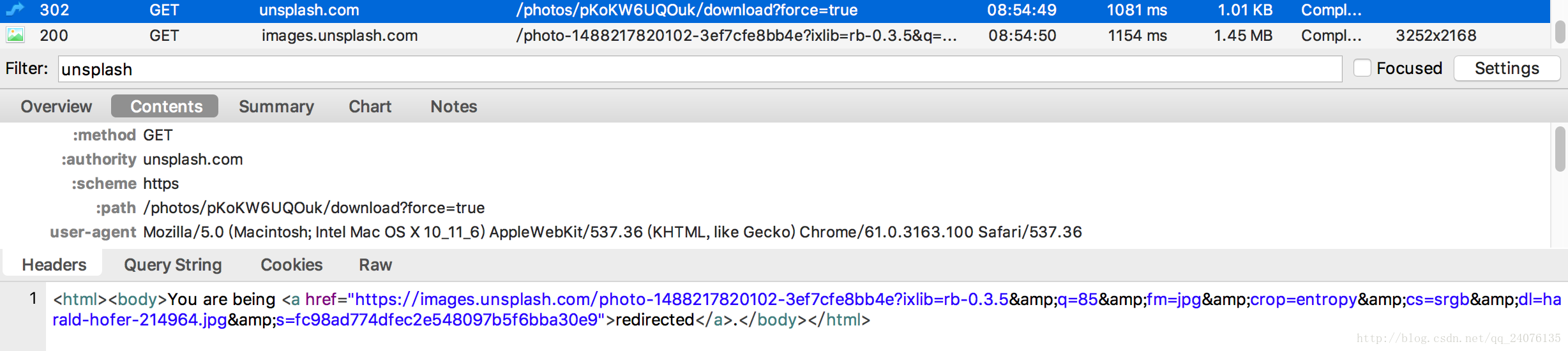
在这里我们就发现了存有图片ID - 在网页上点击下载图片,,从抓包中抓取下载链接,发现下载链接变化部分就是图片的id
这样,就能确定爬取图片的具体步骤了。 - 从json中爬出图片id,在下载链接上填充id部分,执行下载操作
- 分析完之后,总结一下代码步骤
- 爬取包中的图片id,保存到list中
- 依次按照图片id,进行图片的下载
五、代码整理
代码步骤
1. 爬取图片id,保存到list中去
# -*- coding:utf-8 -*-
import requests,json
def get_ids():
# target_url = 'http://unsplash.com/napi/feeds/home'
id_url = 'http://unsplash.com/napi/feeds/home'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '*************'#此部分参数通过抓包获取
}
id_lists = []
# SSLerror 通过添加 verify=False来解决
try:
response = requests.get(id_url, headers=header, verify=False, timeout=30)
response.encoding = 'utf-8'
print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic['next_page']))
for each in dic['photos']:
# print("图片ID:{}".format(each['id']))
id_lists.append(each['id'])
print("图片id读取完成")
return id_lists
except:
print("图片id读取发生异常")
return False
if __name__=='__main__':
id_lists = get_ids()
if not id_lists is False:
for id in id_lists:
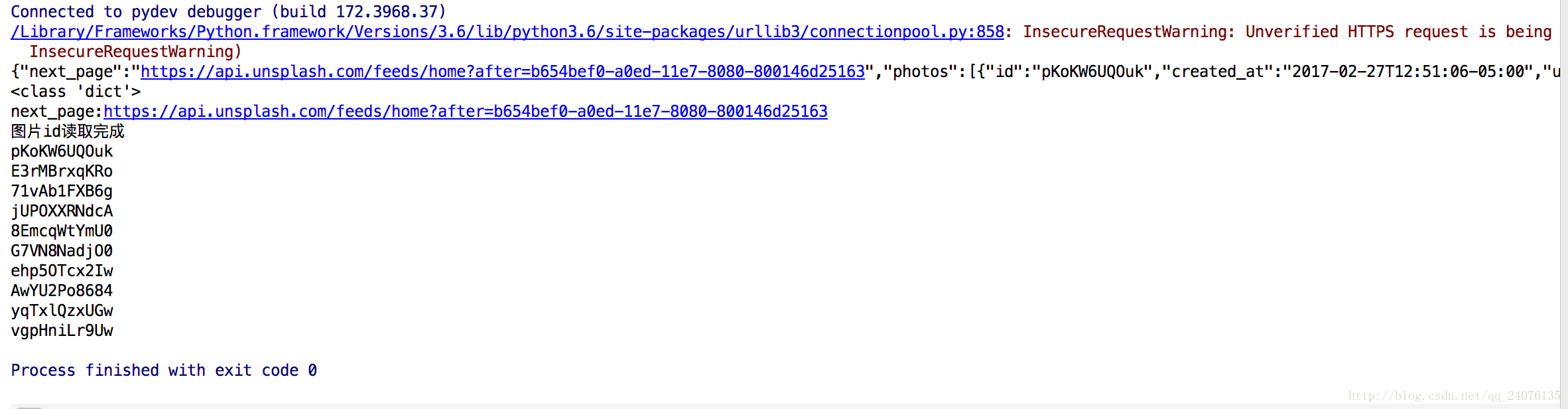
print(id)结果如图所示,图片ID已经成功打印出来了
- 依据图片id,进行图片的下载
import os
from contextlib import closing
import requests
from datetime import datetime
def download(img_id):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '***********'#此参数需从包中获取
}
file_path = 'images'
download_url = 'https://unsplash.com/photos/{}/download?force=true'
download_url = download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs('images')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename='images/'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size = 1024
with closing(requests.get(download_url, headers=header, verify=False, stream=True)) as response:
file = '{}/{}.jpg'.format(file_path, img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file, 'ab+') as f:
for chunk in response.iter_content(chunk_size=chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id, sec))
except:
if os.path.exists(file):
os.remove(file)
print("下载图片{}失败".format(img_id))
if __name__=='__main__':
img_id = 'vgpHniLr9Uw'
download(img_id)
- 1
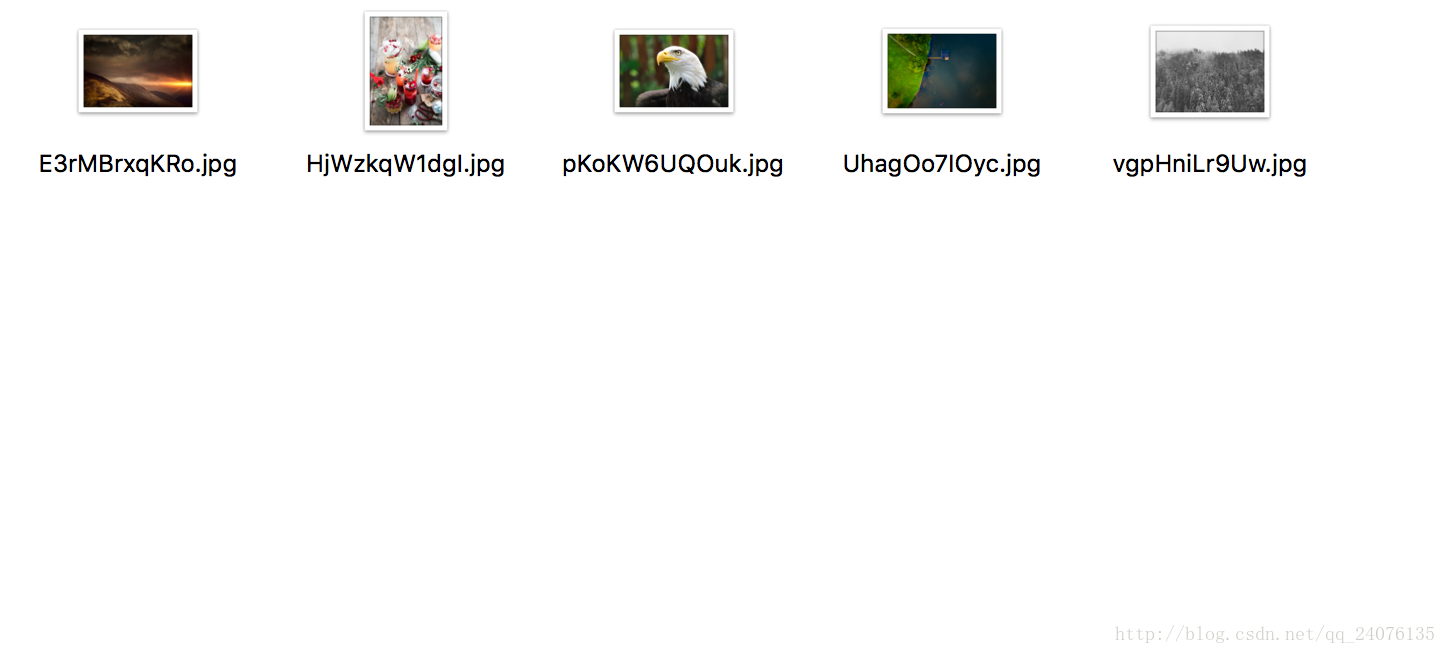
- 运行结果:
下载前
下载后

合并代码,进行批量下载
# -*- coding:utf-8 -*-
import requests,json
from urllib.request import urlretrieve
import os
from datetime import datetime
from contextlib import closing
import time
class UnsplashSpider:
def __init__(self):
self.id_url = 'http://unsplash.com/napi/feeds/home'
self.header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/61.0.3163.79 Safari/537.36',
'authorization': '***********'#此部分需要自行添加
}
self.id_lists = []
self.download_url='https://unsplash.com/photos/{}/download?force=true'
print("init")
def get_ids(self):
# target_url = 'http://unsplash.com/napi/feeds/home'
# target_url = 'https://unsplash.com/'
#SSLerror 通过添加 verify=False来解决
try:
response = requests.get(self.id_url,headers=self.header,verify=False, timeout=30)
response.encoding = 'utf-8'
# print(response.text)
dic = json.loads(response.text)
# print(dic)
print(type(dic))
print("next_page:{}".format(dic['next_page']))
for each in dic['photos']:
# print("图片ID:{}".format(each['id']))
self.id_lists.append(each['id'])
print("图片id读取完成")
return self.id_lists
except:
print("图片id读取发生异常")
return False
def download(self,img_id):
file_path = 'images'
download_url = self.download_url.format(img_id)
if file_path not in os.listdir():
os.makedirs('images')
# 2种下载方法
# 方法1
# urlretrieve(download_url,filename='images/'+img_id)
# 方法2 requests文档推荐方法
# response = requests.get(download_url, headers=self.header,verify=False, stream=True)
# response.encoding=response.apparent_encoding
chunk_size=1024
with closing(requests.get(download_url, headers=self.header,verify=False, stream=True)) as response:
file = '{}/{}.jpg'.format(file_path,img_id)
if os.path.exists(file):
print("图片{}.jpg已存在,跳过本次下载".format(img_id))
else:
try:
start_time = datetime.now()
with open(file,'ab+') as f:
for chunk in response.iter_content(chunk_size = chunk_size):
f.write(chunk)
f.flush()
end_time = datetime.now()
sec = (end_time - start_time).seconds
print("下载图片{}完成,耗时:{}s".format(img_id,sec))
except:
print("下载图片{}失败".format(img_id))
if __name__=='__main__':
us = UnsplashSpider()
id_lists = us.get_ids()
if not id_lists is False:
for id in id_lists:
us.download(id)
#合理的延时,以尊敬网站
time.sleep(1)六、结语
因为本文是学习笔记,中间省略了一些细节。
结合其他资料一起学习,发现爬取动态网站的关键点是抓包分析。只要能从包中分析出关键的数据,剩下写爬虫的步骤