正在看《大型网站技术架构:核心原理与案例分析》,以前有大佬推荐过,但是一直没读,这次一口气读了前两篇,觉得这本书写的很好,是对大型网站架构理论性知识普及。
我觉得,对分布式开发或者架构设计很有启发和参考的价值。
但是由于书中大多都是理论的抛砖引玉,看一遍不够,只看也不够,所以觉得最好的方式是,记笔记,自己亲自画书中的架构图。
第一篇 概述
1 大型网站架构演化
1.1 大型网站软件系统的特点
高并发,大流量
高可用
海量数据
用户分步广泛,网络情况复杂
安全环境恶劣:黑客攻击,密码泄露
需求快速变更,发布频繁
渐进式发展
1.2 大型网站架构演化历程
1.2.1 初始阶段的网站架构

应用程序、文件服务、数据库都部署在一台服务器上
1.2.2 应用服务和数据服务分离
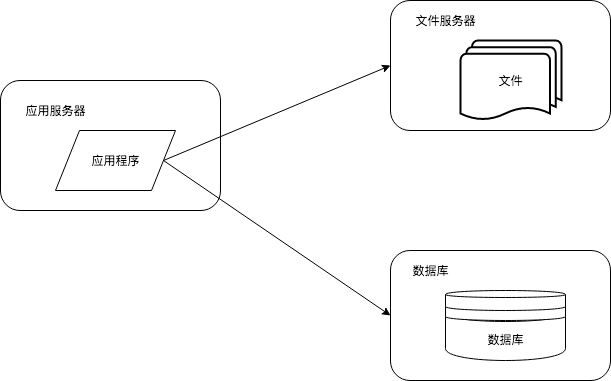
应用服务器、数据库、文件服务器分别部署在不同的机器,不同特性的服务器承担不同的角色
1.2.3 使用缓存改善网站架构
由于部分的业务访问集中在一小部分数据上,那么可以将这一小部分数据缓存起来。
网站使用的缓存分为两种:
(1) 缓存在应用服务器本地的本地缓存,访问速度更快,受限于应用服务器内存,争用内存
(2) 缓存在专门的分布式缓存服务器上的远程缓存,集群方式使用,理论上可以做到不受内存限制的缓存服务
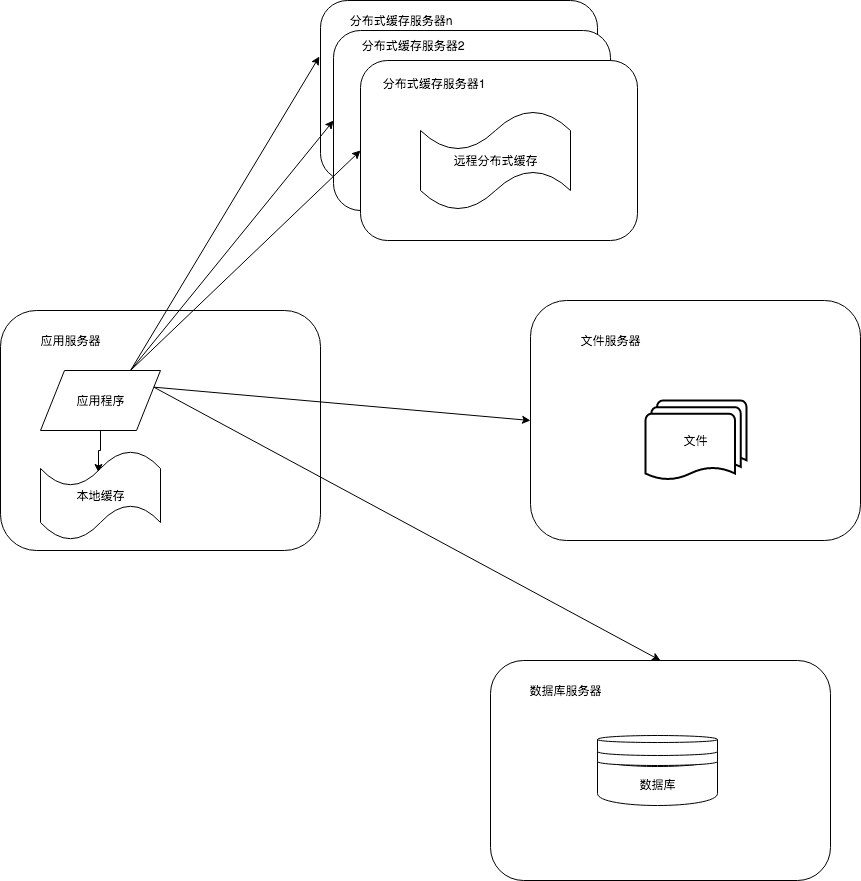
使用缓存后,数据访问压力得到有效缓解,但是单一应用服务器能够处理的请求连接有限,网站访问高峰期,应用服务器称为整个网站的瓶颈。
1.2.4 使用应用服务器集群改善网站的并发处理能力
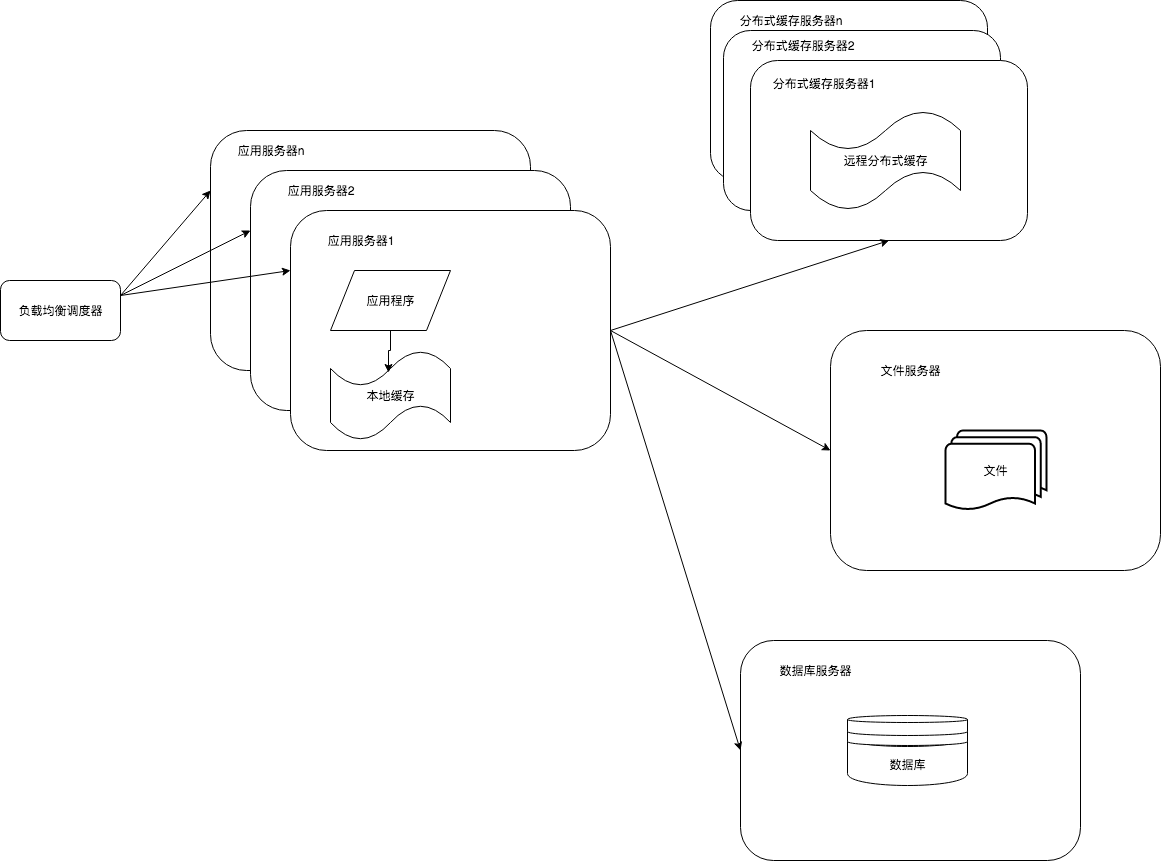
通过应用服务器集群部署,可以通过加入更多的集群服务器使应用服务器可以承载更多的压力,应用服务器的负载压力不再成为整个网站的瓶颈。
1.2.5 数据库读写分离
使用缓存后,大部分读操作可以不通过数据库,而是直接访问到缓存。但是仍有一部分读操作(缓存访问不命中、缓存过期)和全部的写操作需要访问数据库在网站用户达到一定规模后,数据库因为负载压力过高而成为网站的瓶颈。
主流数据库都提供主从热备功能,通过配置两台数据库主从关系,可以将一台数据库服务器的数据更新到另一台数据库服务器上。

应用服务器在写数据的时候,访问主库,主库通过主从复制机制将数据更新同步到从库,这样当应用服务器读数据的时候,就可以通过从库获得数据。
为了便于应用程序访问读写分离后的数据库,通常在应用服务器端使用专门的数据访问模块,使数据库读写分离对应用透明。
思考:同步数据由于网络原因会导致同步的延迟,那么我可能更新了数据后,再去查,短时间查不到我刚更新的内容,发生了读写不一致。这个时候怎么办?