和存储过程很相似,用户自定义函数也是一组有序的T-SQL语句,UDF被预先优化和编译并且作为一个单元进行调用。UDF和存储过程的主要区别在于返回结果的方式。
使用UDF时可传入参数,但不可传出参数。输出参数的概念被改为健壮的返回值取代了。和系统函数一样,可以返回标量值,这个值的好处是它并不像在存储过程中那样只限于整形数据类型,而是可以返回大多数SQL Server数据类型。
UDF有以下两种类型:
[1] 返回标量值的UDF。
[2] 返回表的UDF。
一、创建
创建语法:
CREATE FUNCTION [<schema name>.]<function name> ( [ <@parameter name> [AS] [<schema name>.]<data type> [= <default value> [READONLY]] [,...n] ] ) RETURNS { <scalar type> | TABLE [(<table definition>)] } [ WITH [ENCRYPTION] | [SCHEMABINDING] | [RETURNS NULL ON NULL INPUT | CALLED ON NULL INPUT ] | [EXECUTE AS {CALLER|SELF|OWNER|<'user name'>}] [AS] { EXTERNAL NAME <externam method> | BEGIN [<function statements>] {RETURN <type as defined in RETURNS clause | RETURN (<SELECT statement>)} END}[;]
二、返回标量值的UDF
这种类型的UDF和大多数SQL Server内置函数一样,会向调用脚本或存储过程返回标量值,像GETDATE()或USER()函数就会返回标量值。
UDF的返回值并不限于整数,而是可以返回除了BLOB、游标(cursor)和时间戳以外的任何有效的SQL Server数据类型(包括用户自定义类型)。即时同为返回整数,UDF也有以下两个吸引人的方面。
与存储过程不同,用户自定义函数返回值的目的是提供有意义的数据;而对于存储过程来说,返回值只能说明成功或失败,如果失败,则会提供一些关于失败性质的特定信息。
可在查询中内联执行函数(如作为SELECT语句的一部分),而使用存储过程则不行。
下面创建一个UDF如下:
CREATE FUNCTION DateOnly(@Date DateTime) RETURNS varchar(12) AS BEGIN RETURN CONVERT(varchar(12),@Date,101) END
然后试着,运用一下:
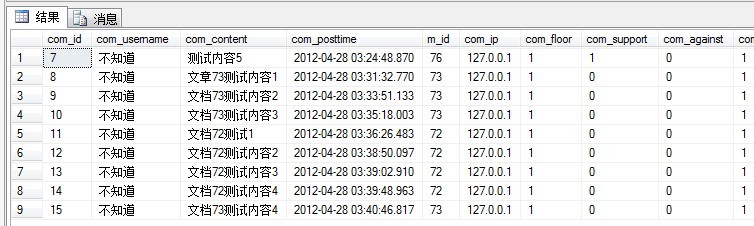
SELECT * FROM Nx_comment WHERE dbo.DateOnly(com_posttime) = '2012.04.28' --注意前面的dbo是必须的。
其实以上SQL语句相当于:
SELECT * FROM Nx_comment WHERE CONVERT(varchar(12),com_posttime,102) = '2012.04.28'
留意到是用了UDF的SQL语句可读性更加好。显示结果如下:
再来看一个简单的查询:
SELECT Name,Age,
(SELECT AVG(Age) FROM Person) AS AvgAge,
Age - (SELECT AVG(Age) FROM Person) AS Difference
FROM Person
以上SQL查询返回结果集如下:
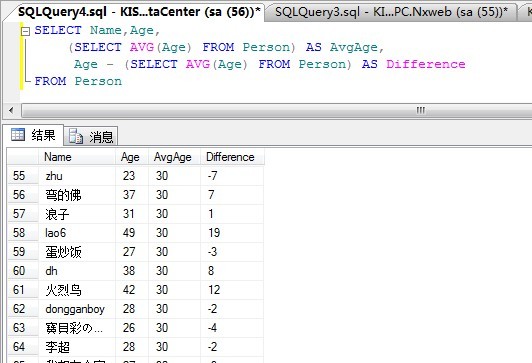
这里要说明一下,列的意思分别是,姓名,年龄,平均年龄以及与平均年龄的差值。
下面我们用UDF来实现,先定义两个UDF如下:
CREATE FUNCTION dbo.AvgAge() RETURNS int AS BEGIN RETURN (SELECT AVG(Age) FROM Person) END GO CREATE FUNCTION dbo.AgeDifference(@Age int) RETURNS int AS BEGIN RETURN @Age - dbo.AvgAge(); --在一个UDF内引用另外一个UDF END
然后执行查询:
SELECT Name,Age,dbo.AvgAge() AS AvgAge,dbo.AgeDifference(Age) as Difference
FROM Person
以上查询在返回结果集上与上面单独的SQL一样,但是为什么我感觉到速度好像慢了很多呢?知道的哥们回复下。
三、返回表的UDF
SQL Server中的用户自定义函数并不只限于返回标量值,也可以返回表。返回的表在很大程度上和其他表是一样的。可以对返回 表的UDF执行JOIN,甚至对结果应用WHERE条件。
改为用表作为返回值并不难,对于UDF来说,表就像任何其他SQL Server数据类型一样。
为了说明情况,我特地建了一张表如下:
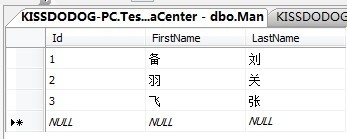
创建一个UDF如下:
CREATE FUNCTION dbo.fnContactName() RETURNS TABLE AS RETURN ( SELECT Id,LastName + ',' + FirstName AS Name FROM Man )
然后我们就可以像表一样地用UDF了。
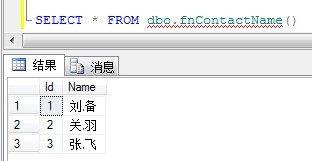
SELECT * FROM dbo.fnContactName()
输出结果如下:
现在再来看看一个简单的用法,定义UDF如下:
CREATE FUNCTION dbo.fnNameLike(@LName varchar(20)) RETURNS TABLE AS RETURN ( SELECT Id,LastName + ',' + FirstName AS Name FROM Man WHERE LastName Like @LName + '%' )
然后查询的时候可以这样用:
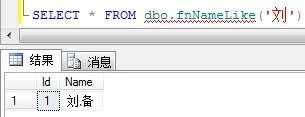
SELECT * FROM dbo.fnNameLike('刘')
显示结果如下:
没有WHERE子句,没有过滤SELECT列表,就可以反复使用该函数,而不需要进行"剪切和粘贴"。而且本例做得不好,其实完全可以先连接一次其他表,然后再查询,这是存储过程所做不到的。
四、理解确定性
用户自定义函数可以是确定性的也可以是非确定性的。确定性并不是根据任何参数类型定义的,而是根据函数的功能定义的。如果给定了一组特定的有效输入,每次函数就都能返回相同的结果,那么就说该函数是确定性的。SUM()就是一个确定性的内置函数。3、5、10的总合永远都是18,而GETDATE()的值就是非确定性的,因为每次调用它的时候GETDATE()都会改变。
为了达到确定性的要求,函数必须满足以下4个条件:
[1] 函数必须是模式绑定的。这意味着函数所依赖的任何对象会有一个依赖记录,并且在没有删除这个依赖的函数之前都不允许改变这些对象。
[2] 函数引用的所有其他函数,无论是用户定义的,还是系统定义的,都必须是确定性的。
[3] 不能引用在函数外部定义的表(可以使用表变量和临时表,只要它们是在函数作用域内定义就行)。
[4] 不能使用扩展存储过程。
确定性的重要性在于它显示了是否要在视图或计算列上建立索引。如果可以可靠地确定视图或计算列的结果,那么才允许在视图或计算列上建立索引。这意味着,如果视图或计算列引用非确定性函数,则在该视图或列上将不允许建立任何索引。
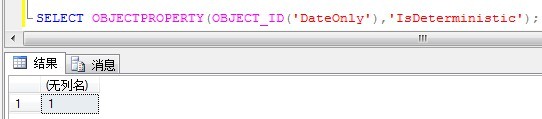
如果判定函数是否是确定性:除了上面描述的规则外,这些信息存储在对象的IsDeterministic属性中,可以利用OBJECTPROPERTY属性检查。
SELECT OBJECTPROPERTY(OBJECT_ID('DateOnly'),'IsDeterministic'); --只是刚才的那个自定义函数
输出结果如下:
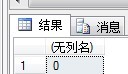
居然是非确定性的。原因在于之前在定义该函数的时候,并没有加上这个"WITH SCHEMABINDING"。
ALTER FUNCTION dbo.DateOnly(@Date date) RETURNS date WITH SCHEMABINDING --当加上这一句之后 AS BEGIN RETURN @Date END
在执行查询,该函数就是确定性的了。