官网: https://www.elastic.co/cn/
中文社区: https://elasticsearch.cn/ (可下载任意版本)
目前官网最新是7.5.0,我这里使用的次新版 7.4.2版本, Linux
默认它不允许使用 root用户,我们这里使用的是yangw这个用户.
安装elasticsearch之前,请确保已安装了JDK8

tar -zxvf elasticsearch-7.4.2-linux-x86_64.tar.gz #解压缩
mv elasticsearch-7.4.2 elasticsearch
cd elasticsearch/
mkdir data
cd config/
vim jvm.options 我的虚拟机内存只设置了1G,故改一下虚拟机大小参数,见图

vim elasticsearch.yml (path指定的路径若不存在则自行创建); 网络改成0.0.0.0表示任意IP都能连


cd ../bin
./elasticsearch
它的启动会比较慢,需要耐心等待...
启动报如下5个错.
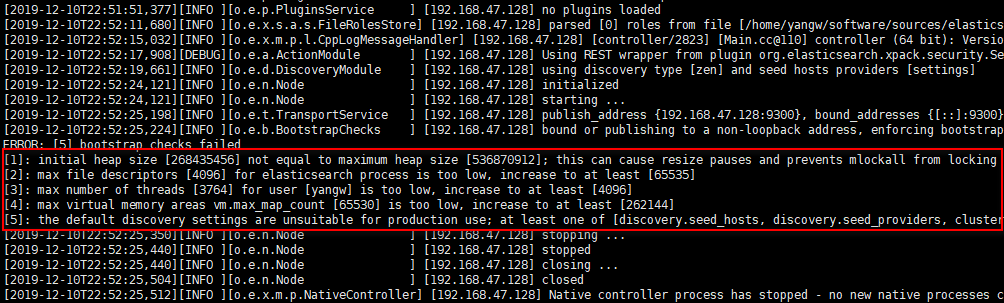
[1]: initial heap size [268435456] not equal to maximum heap size [536870912]; this can cause resize pauses and prevents mlockall from locking the entire heap
解决办法: 重新修改elasticsearch的 jvm.options, 将内存都改成512m即可解决;
[2]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
解决办法:
ulimit -Hn 查看硬限制 结果是4096
切换到root用户
vim /etc/security/limits.conf
在文件最后追加内容: (其中yangw表示对yangw这个用户做的修改. 也可以用 * 表示所有用户)
yangw soft nofile 65536
yangw hard nofile 65536
一般要使用 exit命令退出当前终端,再重新登录启动即可生效;
[3]: max number of threads [3764] for user [yangw] is too low, increase to at least [4096]
解决办法:
切换到root用户
vim /etc/security/limits.conf
在文件最后追加内容
yangw soft nproc 4096
yangw hard nproc 4096
一般要使用 exit命令退出当前终端,再重新登录启动即可生效;
[4]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
解决办法:
切换到root用户,编辑文件 vim /etc/sysctl.conf 在末尾追加内容:
vm.max_map_count=262144
并执行命令 sysctl -p
[5]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
解决办法:

后台运行
若要在关闭终端的时候,让Elasticsearch继续保持运行。最简单的方法就是使用 nohup。 先按Ctrl + C,停止当前运行的Elasticsearch,改用下面的命令运行Elasticsearch
nohup ./bin/elasticsearch&
成功启动后的日志截图:
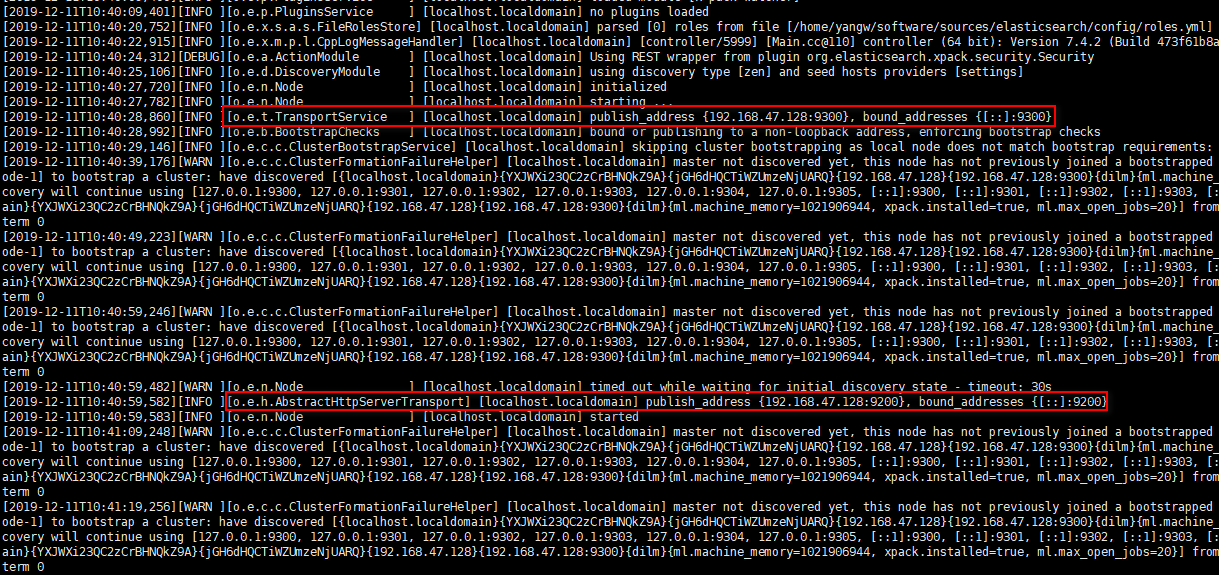
9300端口: ES节点之间通讯使用
9200端口: ES节点 和 外部 通讯使用
9300是TCP协议端口号,ES集群之间通讯端口号
9200端口号,暴露ES RESTful接口端口号
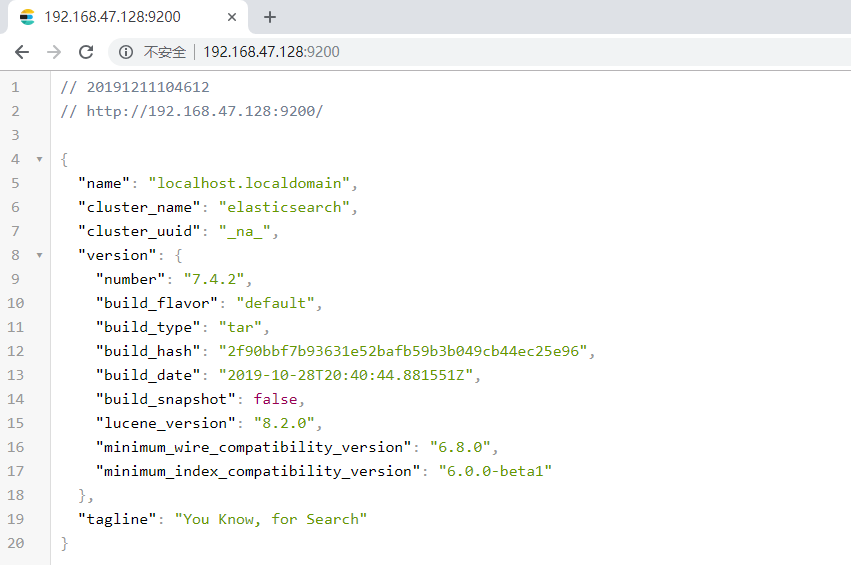
浏览器访问:
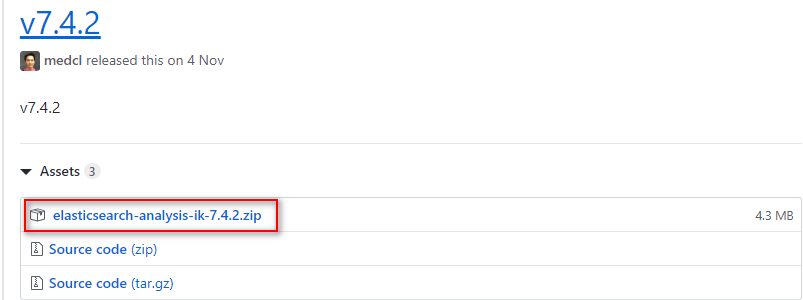
IK分词器 可以到github上下载:(选择与elasticsearch一样的版本 7.4.2 )
https://github.com/medcl/elasticsearch-analysis-ik/tree/master
https://github.com/medcl/elasticsearch-analysis-ik/releases (选择任意版本)
Analyzer: ik_smart , ik_max_word , Tokenizer: ik_smart , ik_max_word
安装步骤:
将elasticsearch-analysis-ik-7.4.2.zip上传到elasticsearch安装目录的plugins目录
unzip elasticsearch-analysis-ik-7.4.2.zip -d analysis-ik
rm -rf elasticsearch-analysis-ik-7.4.2.zip
重新启动 elasticsearch

官方提供大量的Rest风格API: https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html

官方提供各语言的客户端API:https://www.elastic.co/guide/en/elasticsearch/client/index.html
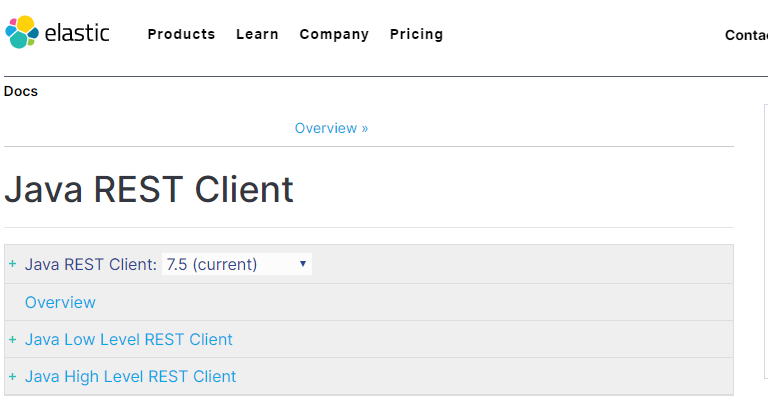
Java Low Level REST Client 是低级别的封装,提供一些基础功能,但更灵活;
Java High Level REST Client是高级别的封装,功能更丰富和完善,而且API会变得简单;
客户端这块,我们主要是学习 Spring Data Elasticsearch 客户端API
而且还提供了操作Elasticsearch索引数据的控制台,并且提供了一定的API提示。
一句话,它就是可视化窗口工具.
它是基于Nodejs的,故要现在Linux服务器上安装Nodejs环境
nodejs安装步骤:
上传 node-v10.16.3-linux-x64.tar.gz 包到服务器,
tar -zxvf node-v10.16.3-linux-x64.tar.gz
mv node-v10.16.3-linux-x64 node_10.16.3
cd ~
vim .bashrc
添加环境变量内容:

source .bashrc
查看版本node -v 出现版本号就表示OK.
kibana安装步骤
tar -zxvf kibana-7.4.2-linux-x86_64.tar.gz
cd kibana-7.4.2-linux-x86_64
cd config
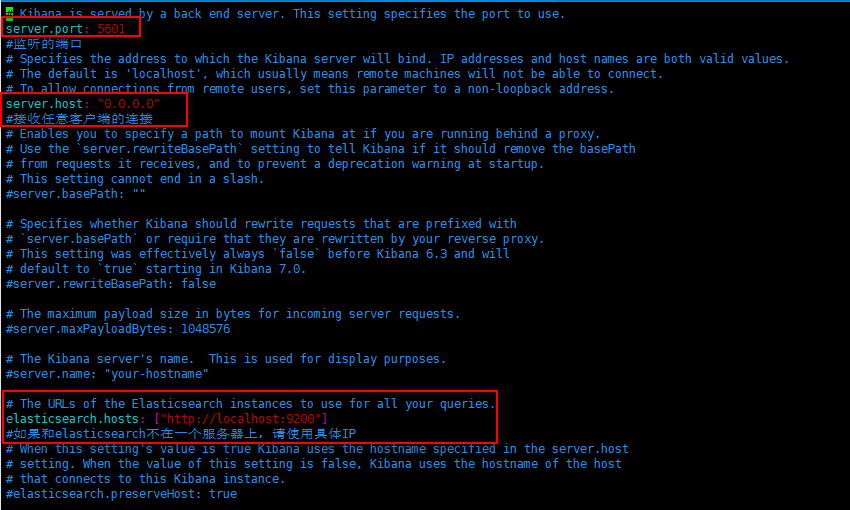
vim kibana.yml
修改如下内容:
cd ../bin
./kibana
启动时间稍微长一点,请耐心等待.
若启动报如下类型的错误
Status changed from yellow to red - [data] Elasticsearch cluster did not respond with license information.
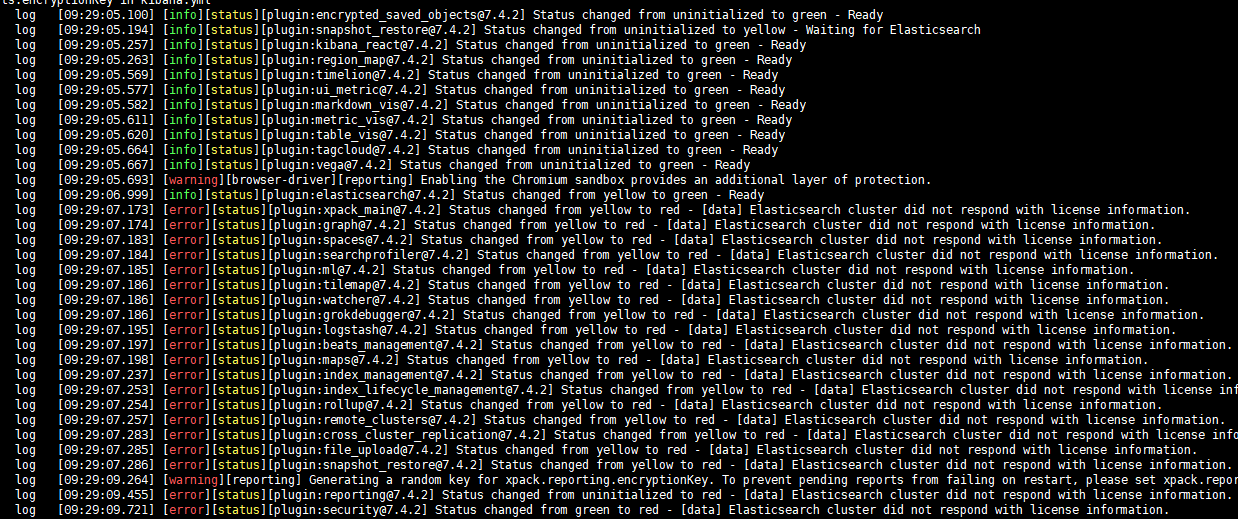
请修改elasticsearch的配置文件,vim elasticsearch.yml
再次启动,就正常了,正常日志如下:

浏览器访问:
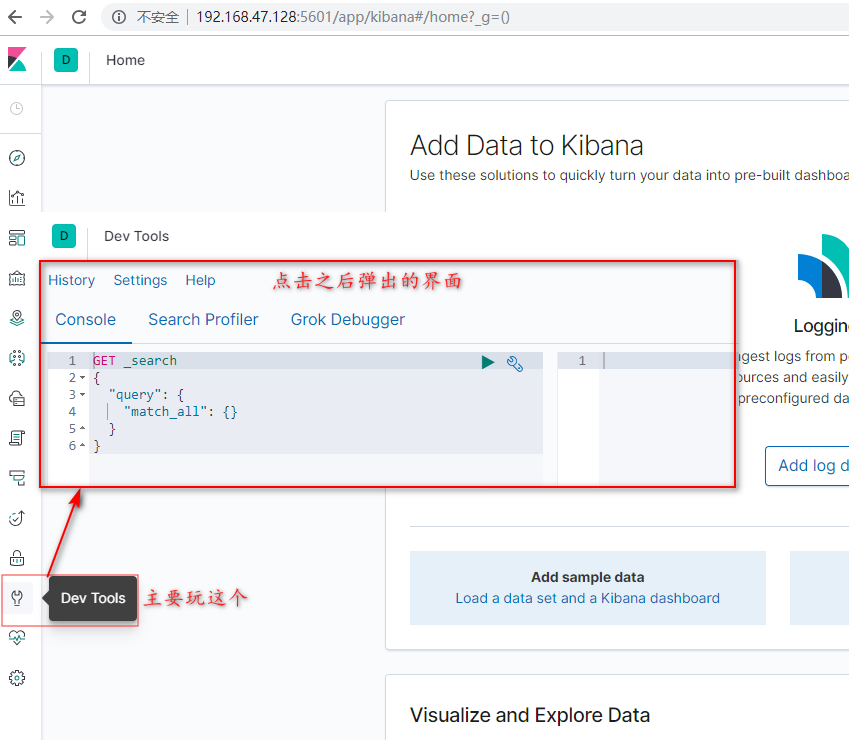
kibana的控制台,可以对http请求进行简化.
-
请求方式:PUT
-
请求路径:/索引库名
-
请求参数:json格式:
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}-
settings:索引库的设置
-
number_of_shards:分片数量
-
number_of_replicas:副本数量
-
-
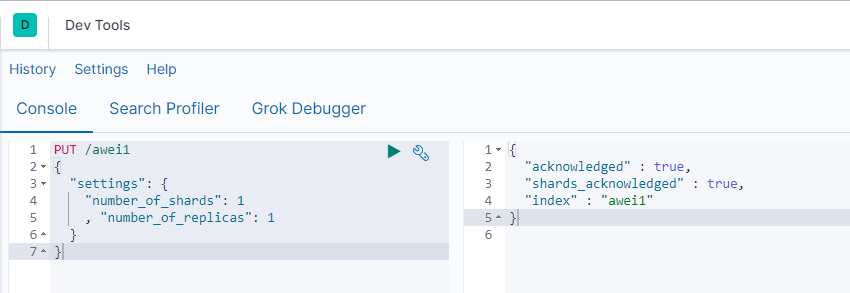
查看索引 GET /索引库名
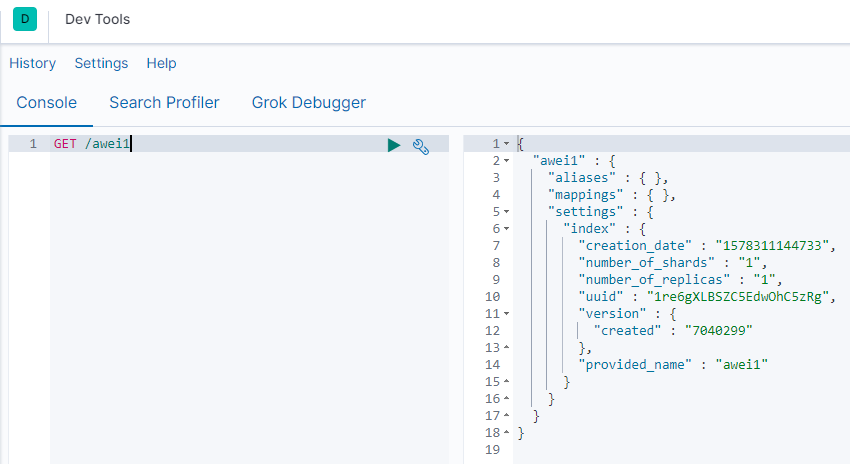
删除索引 DELETE /索引库名
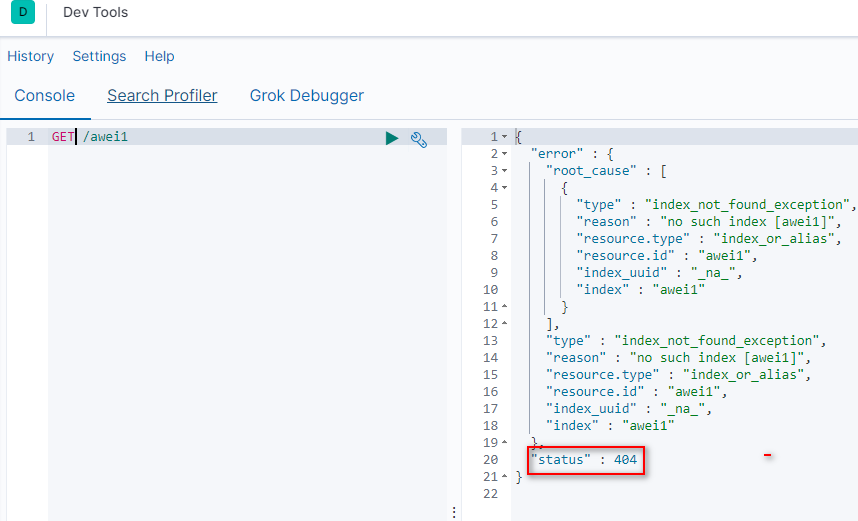
当然,我们也可以用HEAD请求,查看索引是否存在
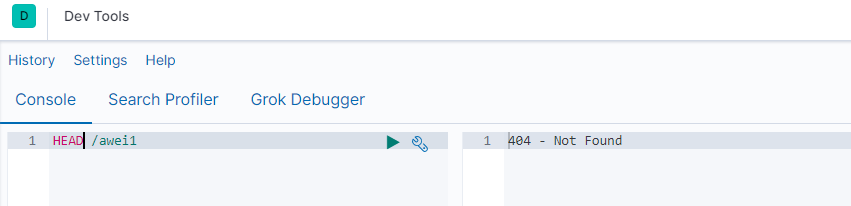
属性字段的一些设置
-
type:类型,可以是text、long、short、date、integer、object等
-
index:是否索引,默认为true
-
store:是否存储,默认为false
-
analyzer:分词器,这里的
ik_max_word即使用ik分词器
数据类型: https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-types.html
-
String类型,又分两种:
-
text:可分词,不可参与聚合
-
keyword:不可分词,数据会作为完整字段进行匹配,可以参与聚合
-
-
Numerical:数值类型,分两类
-
基本数据类型:long、interger、short、byte、double、float、half_float
-
浮点数的高精度类型:scaled_float
-
需要指定一个精度因子,比如10或100。elasticsearch会把真实值乘以这个因子后存储,取出时再还原。
-
-
-
Date:日期类型
elasticsearch可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间。
index影响字段的索引情况。
-
true:字段会被索引,则可以用来进行搜索。默认值就是true
-
false:字段不会被索引,不能用来搜索
index的默认值就是true,也就是说你不进行任何配置,所有字段都会被索引。
但是有些字段是我们不希望被索引的,比如商品的图片信息,就需要手动设置index为false。
2.5.3.3.store
是否将数据进行额外存储。
在学习lucene和solr时,我们知道如果一个字段的store设置为false,那么在文档列表中就不会有这个字段的值,用户的搜索结果中不会显示出来。
但是在Elasticsearch中,即便store设置为false,也可以搜索到结果。
原因是Elasticsearch在创建文档索引时,会将文档中的原始数据备份,保存到一个叫做_source的属性中。而且我们可以通过过滤_source来选择哪些要显示,哪些不显示。
而如果设置store为true,就会在_source以外额外存储一份数据,多余,因此一般我们都会将store设置为false,事实上,store的默认值就是false。
创建映射 PUT /索引库名/_mapping (这个是elastic7.x的语法)
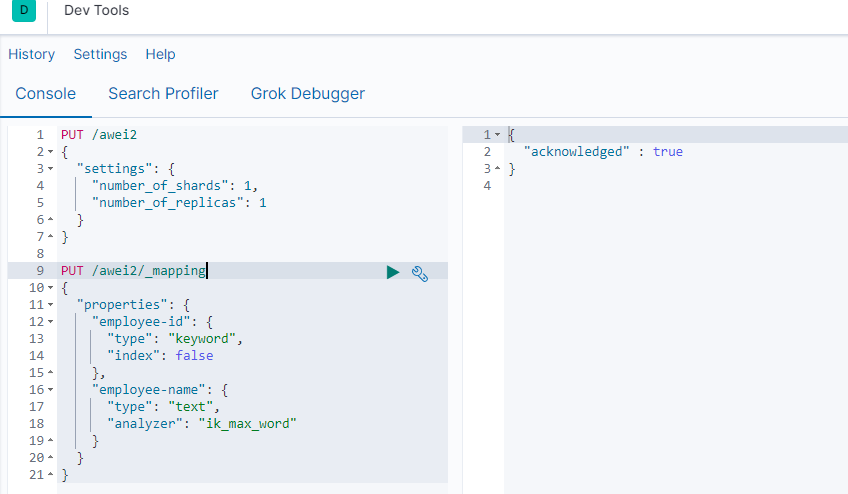
查看映射 GET /索引库名/_mapping
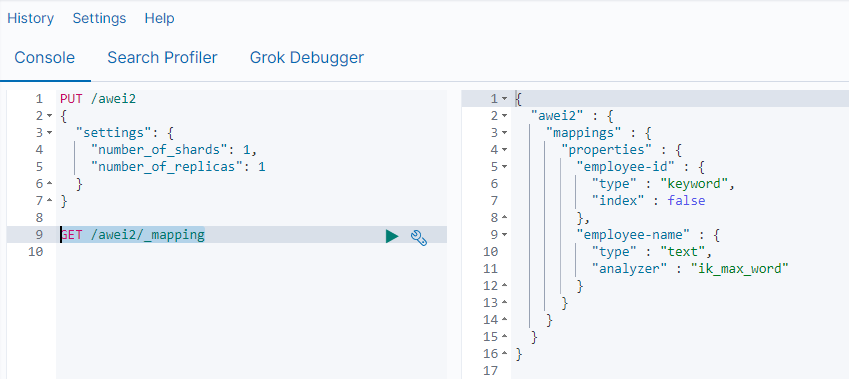
查看映射(某个具体的字段) GET /索引库名/_mapping/field/字段名
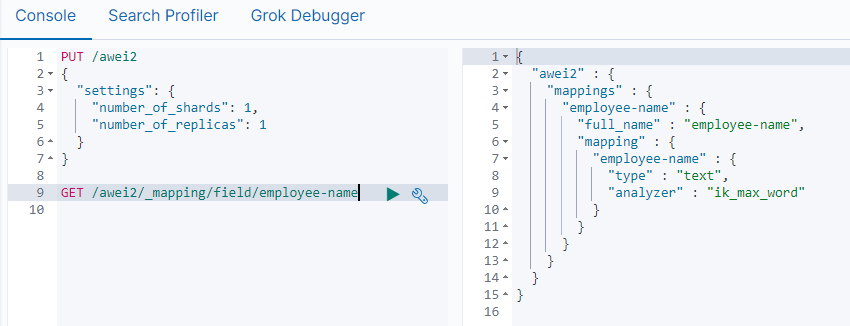
Elasticsearch 7.x
- 不建议在请求中指定类型。新索引API使用
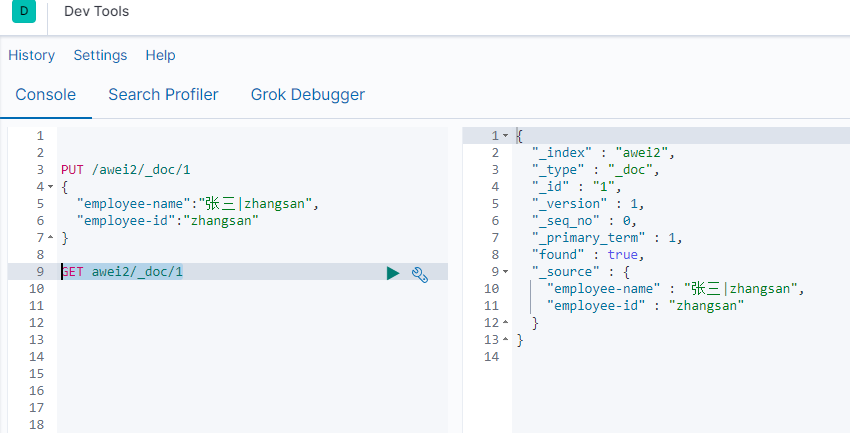
PUT {index}/_doc/{id}于显式ID 和POST {index}/_doc自动生成的ID。请注意,在7.0中,它_doc是路径的永久部分,代表端点名称而不是文档类型。
事实上Elasticsearch非常智能,你不需要给索引库设置任何mapping映射,它也可以根据你输入的数据来判断类型,动态添加数据映射。
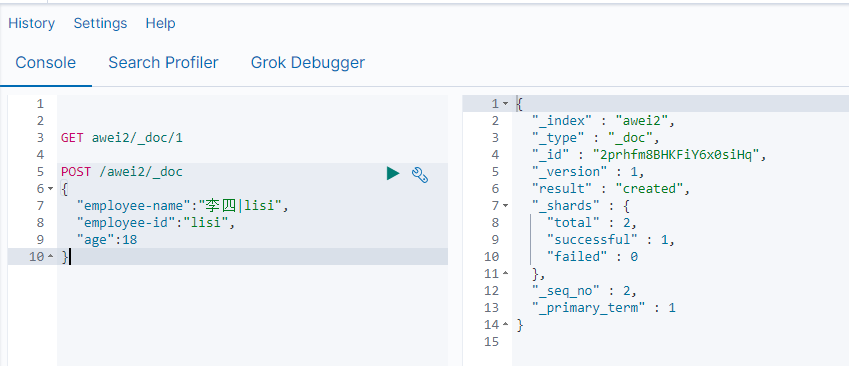
更新数据 POST /索引库名/_update/{id}
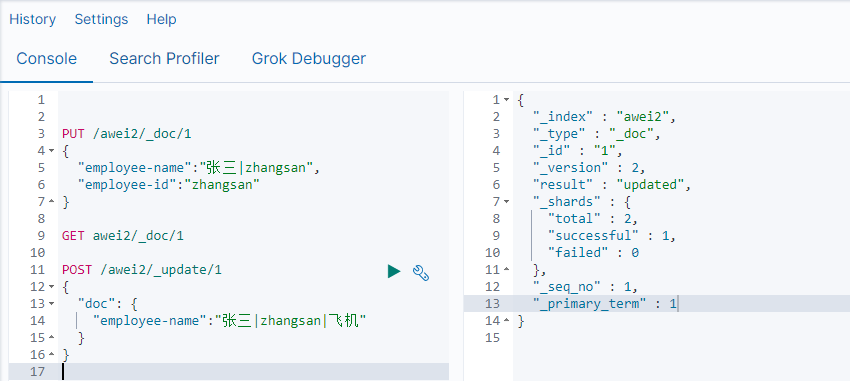
删除数据 DELETE /索引库名/_doc/{id}

https://www.elastic.co/guide/en/elasticsearch/reference/7.4/query-dsl-match-query.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.4/full-text-queries.html
查询数据语法:
GET /索引库名/_search
{
"query":{
"查询类型":{
"查询条件":"查询条件值"
}
}
}
这里的query代表一个查询对象,里面可以有不同的查询属性
-
查询类型:
-
例如:
match_all,match,term,range等等
-
-
查询条件:查询条件会根据类型的不同,写法也有差异。

-
took:查询花费时间,单位是毫秒
-
time_out:是否超时
-
_shards:分片信息
-
hits:搜索结果总览对象
-
total:搜索到的总条数
-
max_score:所有结果中文档得分的最高分
-
hits:搜索结果的文档对象数组,每个元素是一条搜索到的文档信息
-
_index:索引库
-
_type:文档类型
-
_id:文档id
-
_score:文档得分
-
_source:文档的源数据
-
-
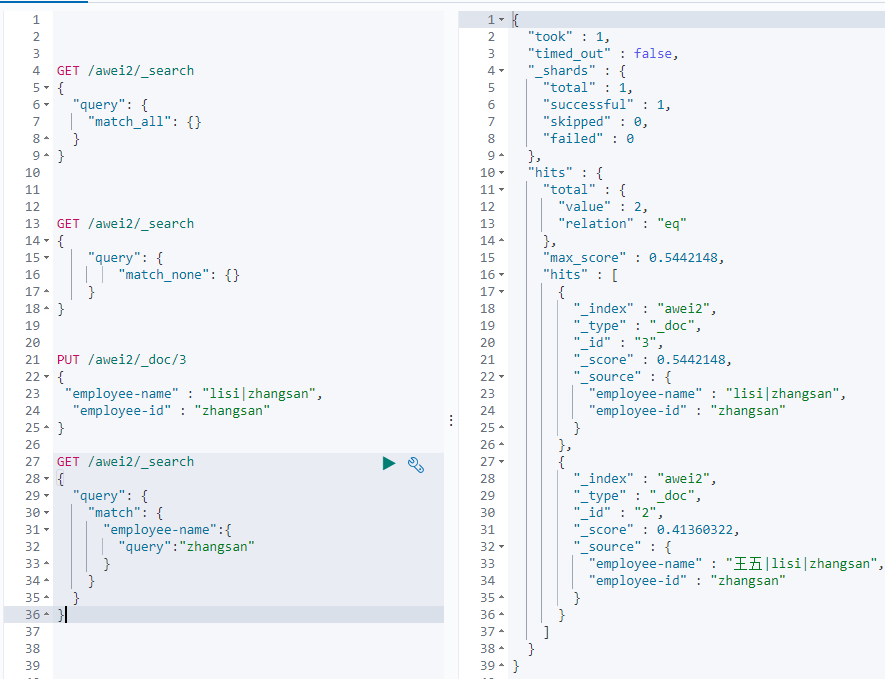
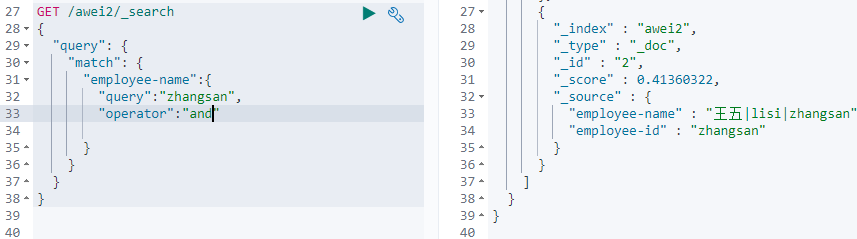
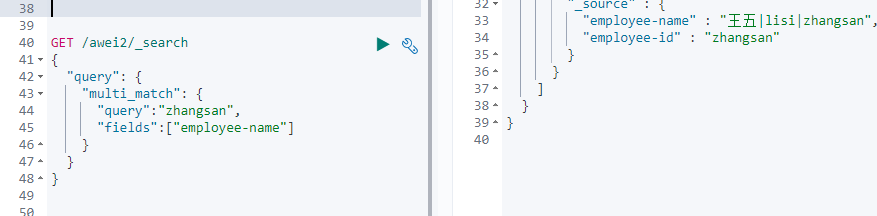
匹配查询(match)
默认是or的关系,如果要再精确匹配的话,可以使用 "operator":"and"
词条匹配(term)
https://www.elastic.co/guide/en/elasticsearch/reference/7.4/query-dsl-term-query.html
term 查询被用于精确值 匹配,这些精确值可能是数字、时间、布尔或者那些未分词的字符串

https://www.elastic.co/guide/en/elasticsearch/reference/7.4/query-dsl-terms-query.html

默认情况下,elasticsearch在搜索的结果中,会把文档中保存在 _source 的所有字段都返回。
1. 如果我们只想获取其中的部分字段,我们可以添加_source的过滤;
2. 也可以在_source中使用includes excutes来设置包含和排除那些字段;
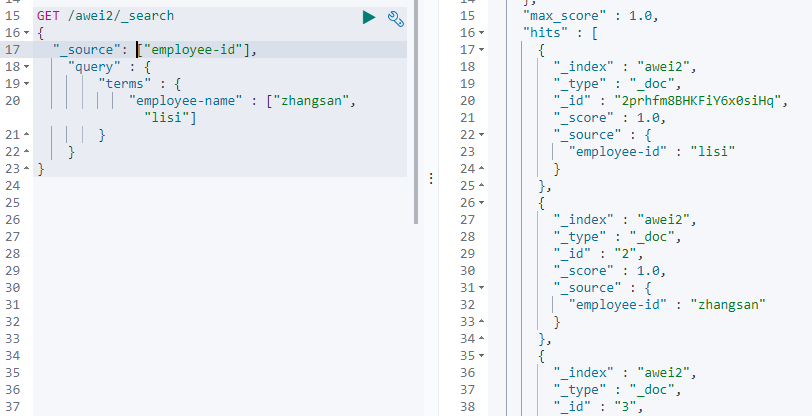

布尔组合(bool)
bool把各种其它查询通过must(与)、must_not(非)、should(或)的方式进行组合
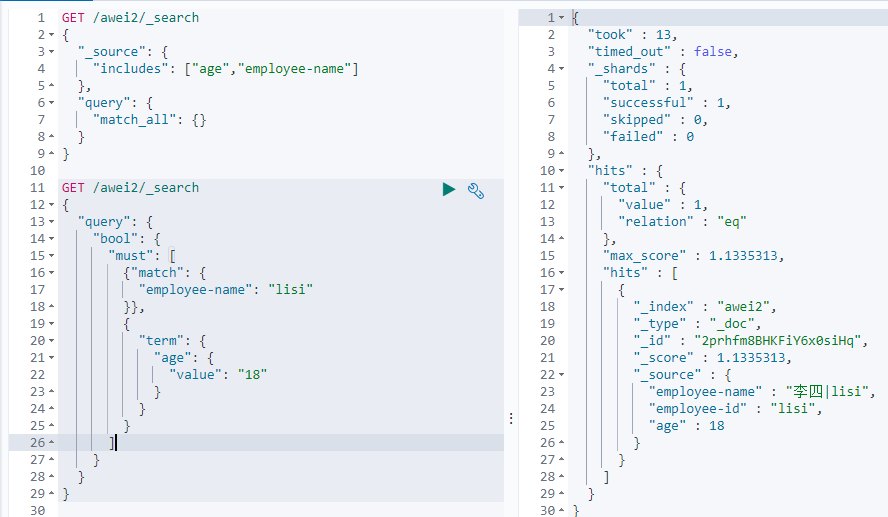
range 查询找出那些落在指定区间内的数字或者时间
gt 大于 gte 大于等于 lt小于 lte 小于等于

模糊查询(fuzzy)
fuzzy 查询是 term 查询的模糊等价。它允许用户搜索词条与实际词条的拼写出现偏差,但是偏差的编辑距离不得超过2:

条件查询中进行过滤
filter方式;
一般都是在bool查询中使用filter
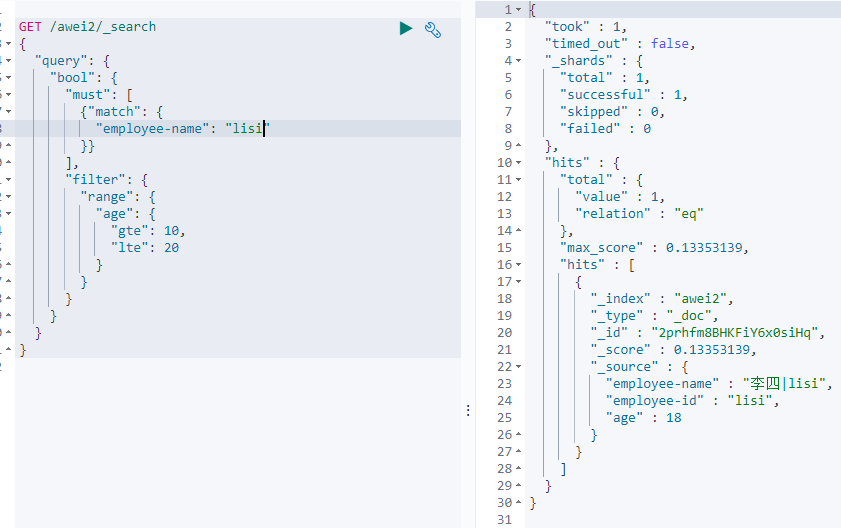
无查询条件,直接过滤
如果一次查询只有过滤,没有查询条件,不希望进行评分,我们可以使用constant_score取代只有 filter 语句的 bool 查询。在性能上是完全相同的,但对于提高查询简洁性和清晰度有很大帮助。
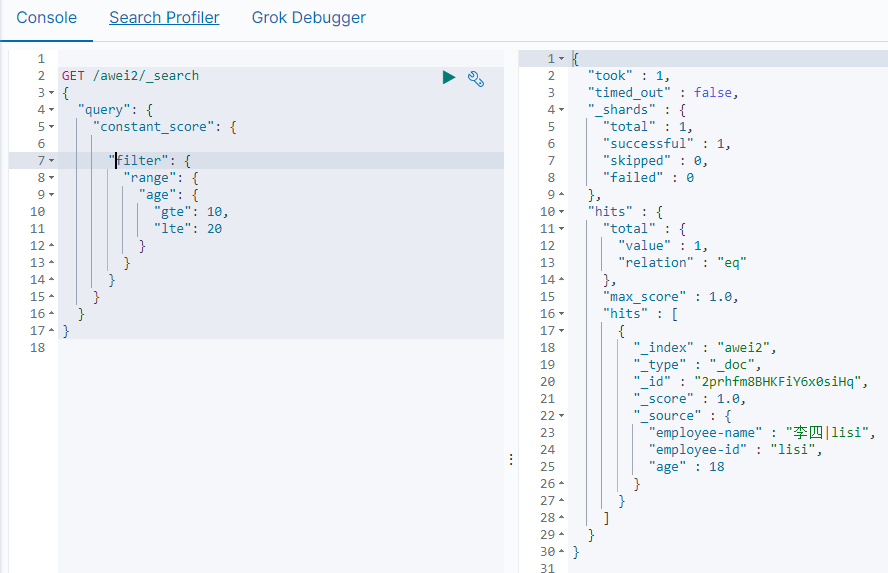
排序
单字段排序
sort 可以让我们按照不同的字段进行排序,并且通过order指定排序的方式
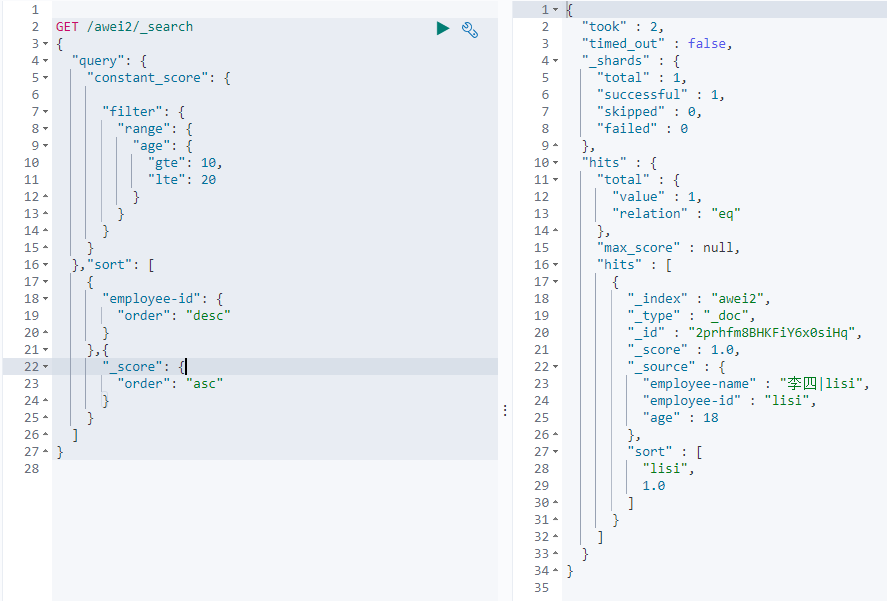
聚合aggregations
-
什么品牌的手机最受欢迎?
-
这些手机的平均价格、最高价格、最低价格?
-
这些手机每月的销售情况如何?
实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现实时搜索效果。
Elasticsearch中的聚合,包含多种类型,最常用的两种,一个叫桶,一个叫度量:
桶的作用,是按照某种方式对数据进行分组,每一组数据在ES中称为一个
Elasticsearch中提供的划分桶的方式有很多:
-
Date Histogram Aggregation:根据日期阶梯分组,例如给定阶梯为周,会自动每周分为一组
-
Histogram Aggregation:根据数值阶梯分组,与日期类似
-
Terms Aggregation:根据词条内容分组,词条内容完全匹配的为一组
-
Range Aggregation:数值和日期的范围分组,指定开始和结束,然后按段分组
-
……
bucket aggregations 只负责对数据进行分组,并不进行计算,因此往往bucket中往往会嵌套另一种聚合:metrics aggregations即度量
度量(metrics)
分组完成以后,我们一般会对组中的数据进行聚合运算,例如求平均值、最大、最小、求和等,这些在ES中称为度量
比较常用的一些度量聚合方式:
-
Avg Aggregation:求平均值
-
Max Aggregation:求最大值
-
Min Aggregation:求最小值
-
Percentiles Aggregation:求百分比
-
Stats Aggregation:同时返回avg、max、min、sum、count等
-
Sum Aggregation:求和
-
Top hits Aggregation:求前几
-
Value Count Aggregation:求总数
-
……
注意:在ES中,需要进行聚合、排序、过滤的字段其处理方式比较特殊,因此不能被分词。这里我们将color和make这两个文字类型的字段设置为keyword类型,这个类型不会被分词,将来就可以参与聚合
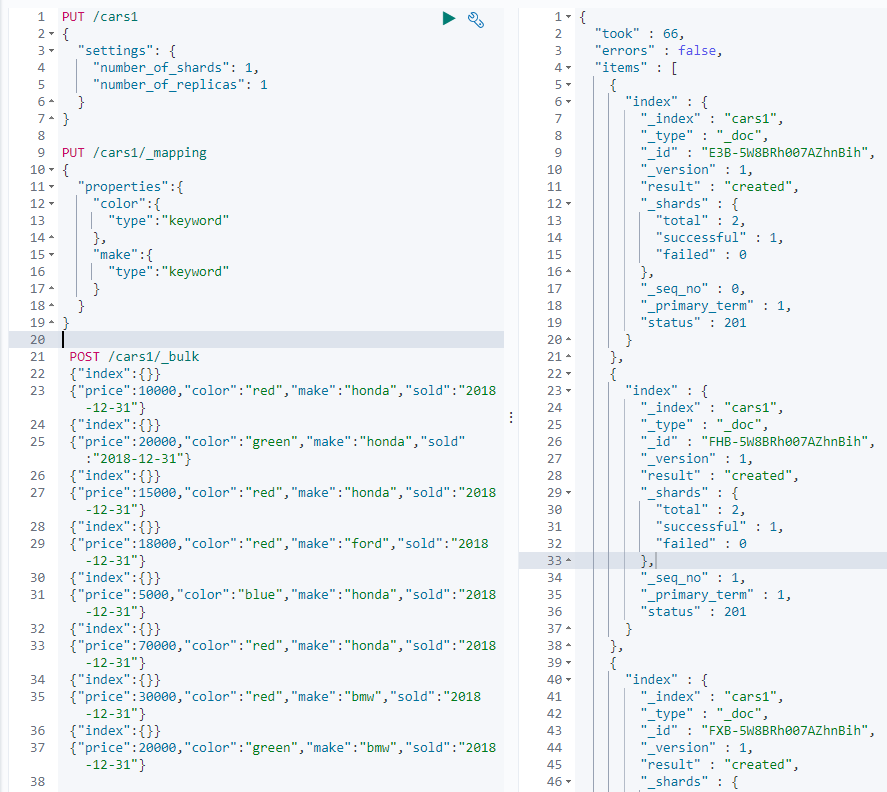
例子: 常见索引库,定义字段,批量插入数据
批量插入用 _bulk
-
size: 查询条数,这里设置为0,因为我们不关心搜索到的数据,只关心聚合结果,提高效率
-
aggs:声明这是一个聚合查询,是aggregations的缩写
-
popular_colors:给这次聚合起一个名字,任意。
-
terms:划分桶的方式,这里是根据词条划分
-
field:划分桶的字段
-
-
-

前面的例子告诉我们每个桶里面的文档数量,这很有用。 但通常,我们的应用需要提供更复杂的文档度量。 例如,每种颜色汽车的平均价格是多少?
因此,我们需要告诉Elasticsearch使用哪个字段,使用何种度量方式进行运算,这些信息要嵌套在桶内,度量的运算会基于桶内的文档进行
现在,我们为刚刚的聚合结果添加 求价格平均值的度量:

-
aggs:我们在上一个aggs(popular_colors)中添加新的aggs。可见
度量也是一个聚合 -
avg_price:聚合的名称
-
avg:度量的类型,这里是求平均值
-
field:度量运算的字段
桶内嵌套桶
比如:我们想统计每种颜色的汽车中,分别属于哪个制造商,按照make字段再进行分桶

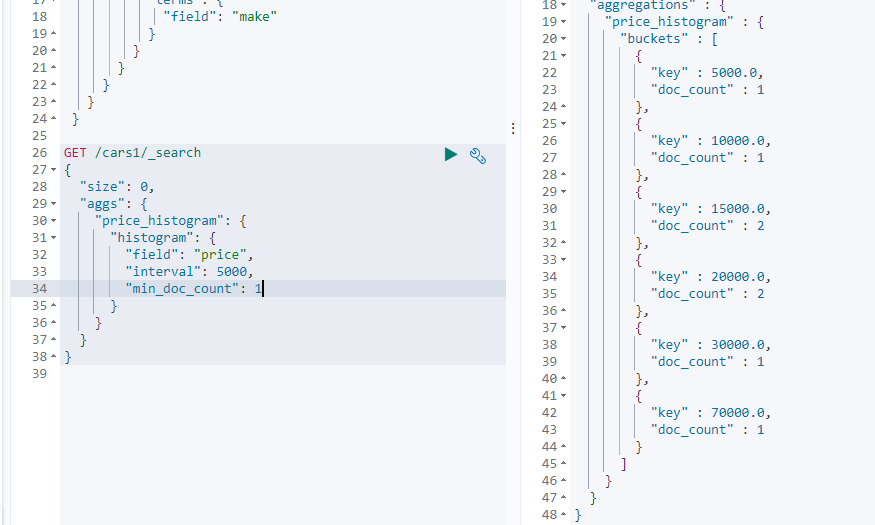
阶梯分桶Histogram
histogram是把数值类型的字段,按照一定的阶梯大小进行分组。你需要指定一个阶梯值(interval)来划分阶梯大小
摘自别的地方:
bootstrap.memory_lock: true导致Elasticsearch启动失败问题
elasticsearch官网建议生产环境需要设置bootstrap.memory_lock: true
解决办法如下:
需要修改
/etc/security/limits.conf
baoshan soft memlock unlimited
baoshan hard memlock unlimited
修改:
/etc/sysctl.conf
vm.swappiness=0
之后重启机器