相似度算法
涉及到了ES的底层,首先讲一下ES的底层核心,相似度模型,ES的查询和传统的数据库查询最大的差别就在相似度查询(之前讲过,索引存储的最大差别就是讲非结构化数据转化为结构化),ES里面会给文档的相似度打分。那么这种打分的算法就是ES的查询的核心,默认的算法是TF/IDF,除了这个默认的算法之外还有很多其他的算法,罗列一下,当你发现现在的查询速度以及效率不满足需要的时候,可以考虑一下下面的算法:
Okapi BM25:适用场景是短文档;
Divergence from randomness (DFR):处理自然语言的相似度处理;
Information-based:同上;
LM Dirichlet:自己看吧:https://lucene.apache.org/core/4_9_0/core/org/apache/lucene/search/similarities/LMDirichletSimilarity.
LM Jelinek Mercer:https://lucene.apache.org/core/4_9_0/core/org/apache/lucene/search/similarities/LMJelinekMercerSimilarity.Note
ES的存储类型
下面是ES的存储方式:
Simple:尽是用于兼容,早期的基于bio的存储模式;
Niofs:基于NIO读写,默认;
Mmap:mapping映射,硬盘数据映射到到内存的虚拟地址;而且MMap只是是用于32bit机器,64bit机器不适用。
fs:是默认选项,会自动识别各个操作系统以及位数下应该采用哪种存储模式。早期版本名称是default_fs。
Mem(已经废弃):(es2.x之后已经移除)内存保存,如果数据存活时间不长,或者数据量不是特别的,采用内存放置,提高查询、检索效率;
事务日志和Searcher
介绍一下ES的索引查询的全流程:
创建索引就不讲了,前面都已经介绍了,包括路由策略等;
提交(Post)了一个文档,首先是提交到了事务日志,事务日志将会将此次提交持久化,主要是可追溯,一旦写入ES失败,可以通过事务日志来进行恢复,另外也避免过于频繁写入ES导致了ES所在主机的IO压力过大;然后事务日志将会定时把数据刷新到ES里面;
这个时候,还有一个对象出现就是searcher,这个货主要就是定时获取ES里面的元数据,通过searcher可以定位到查询文档的位置,我们通常使用/_search?pretty的方式进行查询就是通过访问searcher来进行查询的,因为search是定时刷新的(默认1s),所以searcher的数据是有延迟,可能不会瞬间将最新数据查到;不过还有一种方式就是直接通过指定文档ID的方式/index/docmentId?pretty,这种方式的查询不走searcher,而是综合了事务日志以及ES里面的数据;但是因为牵涉到了两部分的数据,所以如果对于实时性要求不高,但是希望快点可以使用search查询,反之则使用search。
发现是不是和HBase非常想,HBase也是client提交后先入WAL,然后刷到memstore中,最后才入HDFS,查询也是会从memstore以及HDFS中进行联合查询。
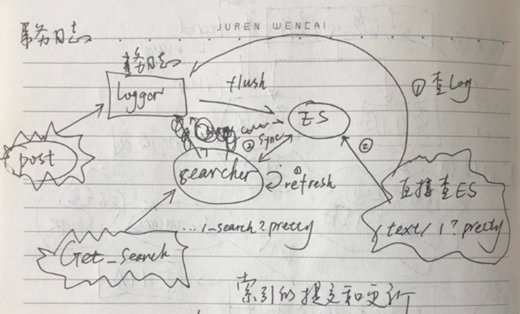
索引合并
索引合并(merge),好处就是加快检索,对于多个小文件的检索是比少量比较大的检索要慢的,所以索引是要合并的,同时还要保证不能合并的太大。当然代价就是I/O操作。合并调度,ES里面的调度分为两种顺序和并发,默认是采用并发,顺序这种模式,你就不用知道了。
IO控制
IO控制,ES是读写高频的应用,所以ES里面有对于IO限流一些配置,首先是指定限流配置应用范围,none(无限制),merge(只有索引合并限制),all(所有的操作都限制);之后ES里面可以针对最大吞吐量之类的属性进行限制。
ES缓存策略
接下来讲一下ES的缓存策略,ES高效海量数据查询一直是它的一个亮点,其中一个原因是因为ES的缓存机制很好。
过滤缓存,就是filtered的缓存,这个就不多说了,只要指定了filter,就可以对其进行缓存;过滤缓存也是有两个级别,索引级别的缓存以及节点级别缓存,一般推荐使用节点缓存;因为数据的落点不可知或者说不定(比如文档保存索引的分片和副本多是不可预知的);不过看了ES master 5.X的版本,已经不再提及索引级别的缓存,只提到了节点级别的缓存。
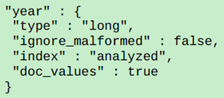
字段数据缓存(基本废弃),这类缓存只是针对非倒排索引的查询,比如聚合,脚本计算以及排序等,可以通过指定缓存字段来减少换存量,可以通过核定eager来对数据进行提前加载,即只要探测到有数据变化,就提前加载查询数据,保持数据新鲜度。但是要知道,docValue的处理效率已经和字段数据缓存很接近,而且不占用内存(仅需要少量的堆内存);另外到了ES5.0之后,你基本可以忽略字段数据缓存,因为ES会为每一个not_ analyzed字段(keyword type)指定docValues;如果想要对于非string的字段使用docValues,如下:
查询分片缓存,这个则是对于倒排索引数据进行缓存,前面两类都是基于非倒排索引,分片缓存则是基于倒排索引(需要对文档进行评分)的查询的缓存。
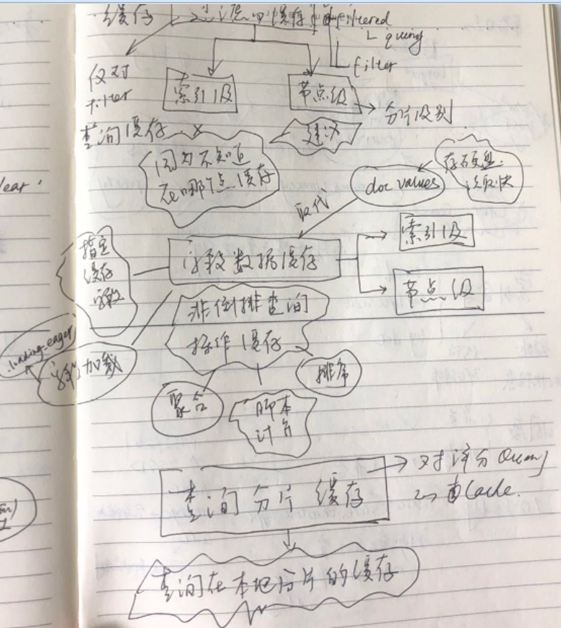
字段回路器,就是预判,如果某次查询使用内存量大于预设的阈值,将会拒绝此次此次查询,默认是达到70%的JVM堆内存。
缓存缓存最后一点就是清楚缓存,可以指定全部清空:
curl -XPOST 'localhost:9200/_cache/clear'
也可以指定索引进行清空:
curl -XPOST 'localhost:9200/mastering/_cache/clear'
curl -XPOST 'localhost:9200/mastering,books/_cache/clear'
还可以指定某类缓存清空:
curl -XPOST 'localhost:9200/mastering/_cache/clear?field_data=true&filter=false&query_cache=false'