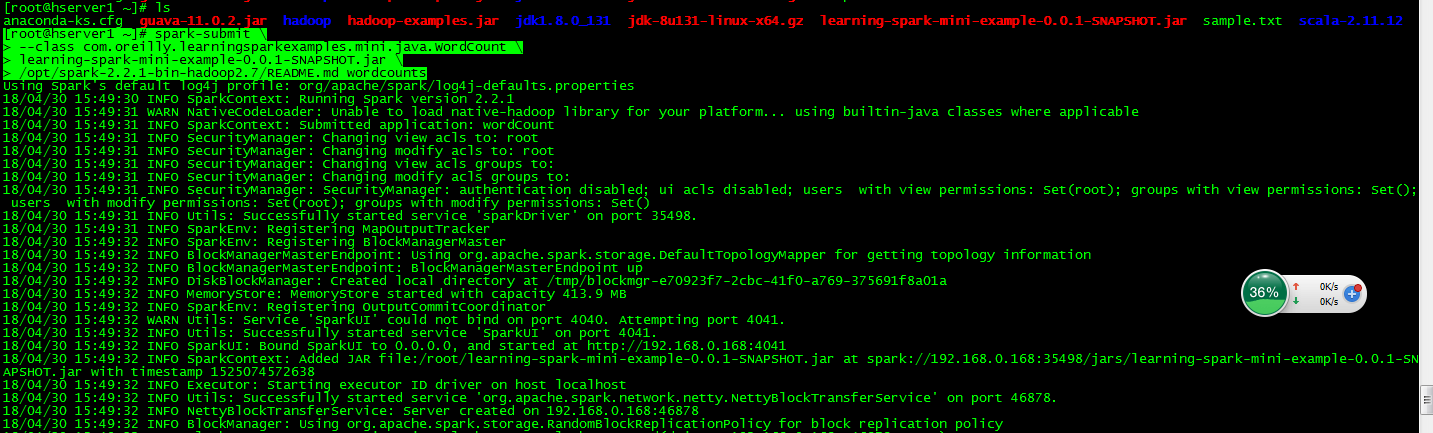
首先在eclipse Java EE中新建一个Maven project具体选项如下
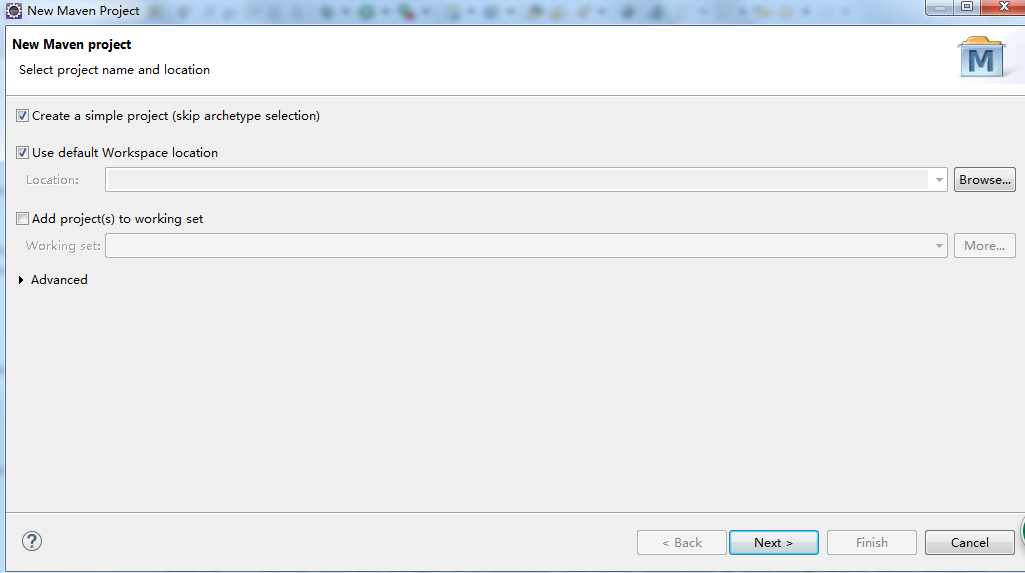

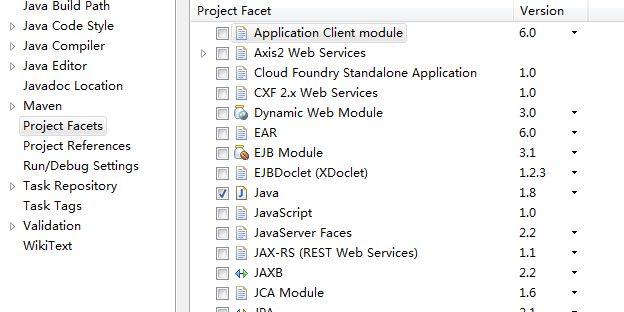
点击Finish创建成功,接下来把默认的jdk1.5改成jdk1.8


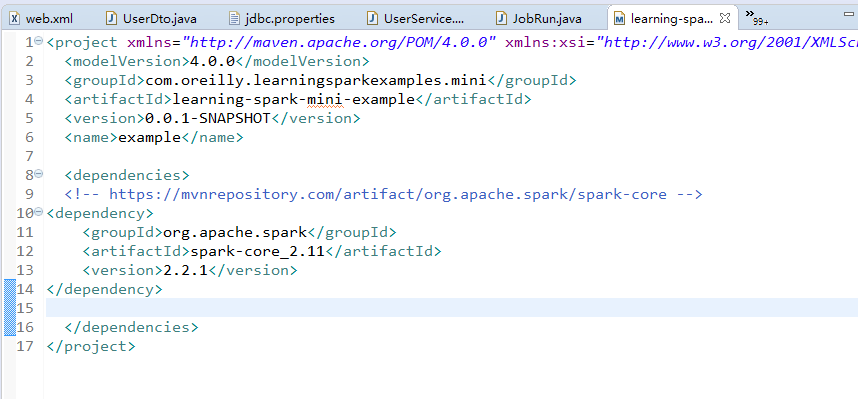
然后编辑pom.xml加入spark-core依赖
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.2.1</version>
</dependency>
然后拷贝书中的源码样例程序,由于书中spark版本为1.2我的环境spark是2.2.1所以需要修改代码适应新版本spark API
JavaRDD<String> words = input.flatMap(
new FlatMapFunction<String, String>() {
public Iterator<String> call(String x) {
return Arrays.asList(x.split(" ")).iterator();
}});
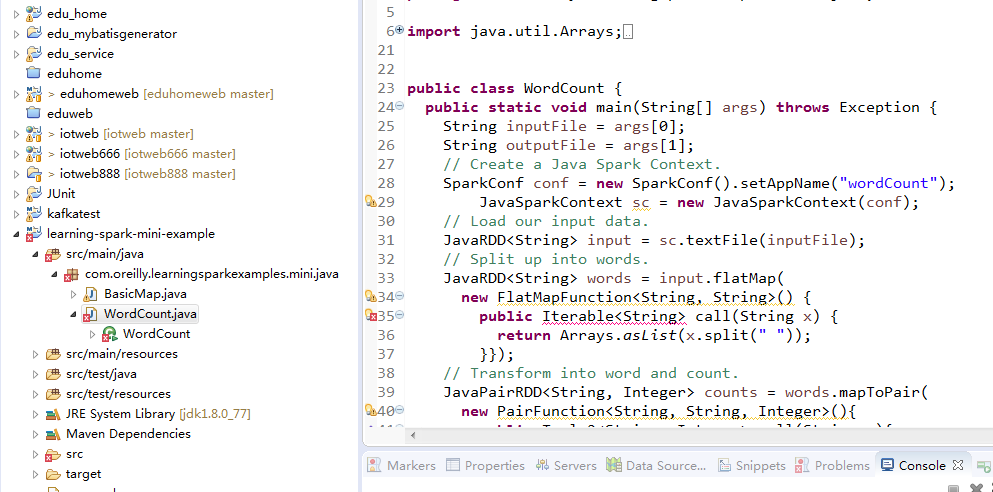

然后执行Maven install接下来可以进入目录E:developtoolseclipse-jee-neon-3-win32workspacelearning-spark-mini-example arget找到learning-spark-mini-example-0.0.1-SNAPSHOT.jar并上传到spark2.2.1环境的linux目录

然后在linux中执行如下命令,如下图
[root@hserver1 ~]# spark-submit
> --class com.oreilly.learningsparkexamples.mini.java.WordCount
> learning-spark-mini-example-0.0.1-SNAPSHOT.jar
> /opt/spark-2.2.1-bin-hadoop2.7/README.md wordcounts