Sqoop项目开始于2009年,最早是作为Hadoop的一个第三方模块存在,后来为了让使用者能够快速部署,也为了让开发人员能够更快速的迭代开发,Sqoop独立成为一个Apache项目。
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(MySQL 、 PostgreSQL...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle , PostgreSQL等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Sqoop这个工具是做数据迁移用的,是关系型数据库和Hive/Hadoop的数据迁移,方便大量数据的导入导出工作。Sqoop底层是通过MapReduce去实现的,但只有Map没有Reduce。
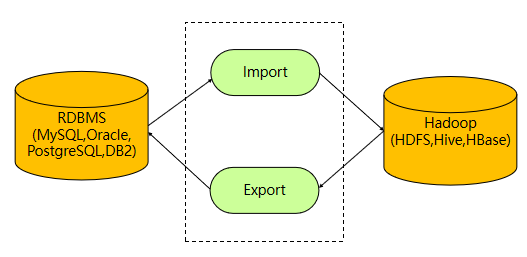
导入数据:MySQL,Oracle 导入数据到 Hadoop 的 HDFS、HIVE、HBASE 等数据存储系统
导出数据:从 Hadoop 的文件系统中导出数据到关系数据库 mysql 等 Sqoop 的本质还是一个命令行工具
1、Sqoop Import原理:
Sqoop在import时,需要指定split-by参数。Sqoop根据不同的split-by参数值来进行切分,然后将切分出来的区域分配到不同map中。 每个map中再处理数据库中获取的一行一行的值,写入到HDFS中。 同时split-by根据不同的参数类型有不同的切分方法,如比较简单的int型,Sqoop会取最大和最小split-by字段值,然后根据传入的num-mappers来确定划分几个区域。比如select max(split_by),min(split-by) from得到的max(split-by)和min(split-by)分别为1000和1,而num-mappers为2的话,则会分成两个区域(1,500)和(501-1000),同时也会分成2个sql给2个map去进行导入操作,分别为select XXX from table where split-by>=1 and split-by<500和select XXX from table where split-by>=501 and split-by<=1000。最后每个map各自获取各自SQL中的数据进行导入工作。
2、Sqoop export 原理:
获取导出表的schema、meta信息,和Hadoop中的字段match; 并行导入数据: 将Hadoop 上文件划分成若干个分片,每个分片由一个Map Task进行数据导入。