进程池
为什么要有进程池?进程池的概念。
在程序实际处理问题过程中,忙时会有成千上万的任务需要被执行,闲时可能只有零星任务。那么在成千上万个任务需要被执行的时候,我们就需要去创建成千上万个进程么?首先,创建进程需要消耗时间,销毁进程也需要消耗时间。第二即便开启了成千上万的进程,操作系统也不能让他们同时执行,这样反而会影响程序的效率。因此我们不能无限制的根据任务开启或者结束进程。那么我们要怎么做呢?
在这里,要给大家介绍一个进程池的概念,定义一个池子,在里面放上固定数量的进程,有需求来了,就拿一个池中的进程来处理任务,等到处理完毕,进程并不关闭,而是将进程再放回进程池中继续等待任务。如果有很多任务需要执行,池中的进程数量不够,任务就要等待之前的进程执行任务完毕归来,拿到空闲进程才能继续执行。也就是说,池中进程的数量是固定的,那么同一时间最多有固定数量的进程在运行。这样不会增加操作系统的调度难度,还节省了开闭进程的时间,也一定程度上能够实现并发效果。
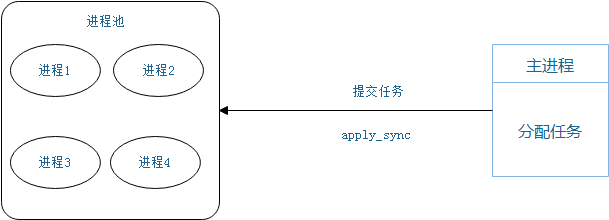
并不关心进程池是如何执行任务的。
因此,并不关心是哪一个进程执行的这个任务
并将任务分配到一个空闲的进程中去执行
multiprocess.Pool模块
主要方法
Pool([numprocess [,initializer [, initargs]]]):创建进程池
numprocess:要创建的进程数,如果省略,将默认为cpu_count()的值,可os.cpu_count()查看
initializer:是每个工作进程启动时要执行的可调用对象,默认为None
initargs:是要传给initializer的参数组
p.apply(func [, args [, kwargs]]):在一个池工作进程中执行func(*args,**kwargs),然后返回结果。 '''需要强调的是:此操作并不会在所有池工作进程中并执行func函数。如果要通过不同参数并发地执行func函数,必须从不同线程调用p.apply()函数或者使用p.apply_async()''' p.apply_async(func [, args [, kwargs]]):在一个池工作进程中执行func(*args,**kwargs),然后返回结果。 '''此方法的结果是AsyncResult类的实例,callback是可调用对象,接收输入参数。当func的结果变为可用时,将理解传递给callback。callback禁止执行任何阻塞操作,否则将接收其他异步操作中的结果。''' p.close():关闭进程池,防止进一步操作。如果所有操作持续挂起,它们将在工作进程终止前完成 P.jion():等待所有工作进程退出。此方法只能在close()或teminate()之后调用
例1:使用进程池
from multiprocessing import Pool import time import os def worker1(): print(" Run task worker1-%s" % (os.getpid())) # os.getpid()获取当前的进程的ID time.sleep(2) print("work1 complete") def worker2(*args, **kwargs): print(" Run task worker2-%s" % (os.getpid())) # os.getpid()获取当前的进程的ID time.sleep(2) print("work2 complete",args, kwargs) if __name__ == '__main__': pool = Pool(3) start = time.time() pool.apply_async(func = worker1) # 提交任务 pool.apply_async(func = worker2,args=(1,2), kwds={'a':1,'b':2} ) pool.apply_async(func = worker2,args=(1,2,3), kwds={'a':1,'b':2,'c':3} ) print("work submit") pool.close() # close()执行后不会有新的进程加入到pool pool.join() # join函数等待子进程结束 end = time.time() print('work complete execute {}s'.format(end - start))
》》》输出结果
work submit
Run task worker1-10912
Run task worker2-9068
Run task worker2-4340
work1 complete
work2 complete (1, 2) {'a': 1, 'b': 2}
work2 complete (1, 2, 3) {'a': 1, 'b': 2, 'c': 3}
work complete execute 2.162142038345337s
例2:使用进程池,并关注结果
from multiprocessing import Pool import time import os def fib(n): time.sleep(1/100) # print("Run task fib(%s)---pid=%s" % (n, os.getpid()),time.asctime(time.localtime(time.time()))) # os.getpid()获取当前的进程的ID if n == 0: return 0 elif n == 1 or n == 2: return 1 else: return fib(n-1) + fib(n-2) if __name__ == '__main__': p = Pool(3) li = [] for i in range(15): li.append(p.apply_async(func=fib, args=(i,))) start = time.time() print('note1:', time.asctime(time.localtime(time.time()))) p.close() p.join() for res in li: print(res.get(), end="::") # 阻塞,直到结果产生 print('note2:',time.asctime(time.localtime(time.time()))) 》》》 note1: Wed Mar 28 18:21:18 2018 0::1::1::2::3::5::8::13::21::34::55::89::144::233::377:: note2: Wed Mar 28 18:21:29 2018
例3:使用进程池,实现并发服务器
服务端:
from multiprocessing import Pool import socket server = socket.socket() server.bind(('127.0.0.1', 9988)) server.listen(6) def worker(conn): while True: recv_data = conn.recv(1024) if recv_data: print('接收的数据是:%s' % recv_data.decode()) conn.send(recv_data) else: conn.close() break if __name__ == '__main__': pool = Pool(5) while True: conn, addr = server.accept() print('Connected by2', addr) # 输出客户端的IP地址 pool.apply_async(worker, args=(conn,))
客户端:
from socket import * client=socket(AF_INET,SOCK_STREAM) client.connect(('127.0.0.1',9988)) while True: msg=input('>>: ').strip() if not msg:continue client.send(msg.encode('utf-8')) msg=client.recv(1024) print(msg.decode('utf-8'))
例4:使用进程池,爬取多个网站信息
from multiprocessing import Pool import requests import os def get_page(url): """ 得到网页内容 :param url: :return: """ print('<%os> get [%s]' %(os.getpid(), url)) response = requests.get(url) # 得到地址 response响应 return {'url': url, 'text': response.text} if __name__ == '__main__': p = Pool(4) urls = [ 'https://www.baidu.com', 'https://www.python.org', 'https://help.github.com/', 'http://www.sina.com.cn/' ] obj_l= [] for url in urls: obj = p.apply_async(get_page,args=(url,)) obj_l.append(obj) p.close() p.join() print([obj.get() for obj in obj_l])
例5: 自定义线程池
import threading import queue import time class MyThread(threading.Thread): def __init__(self, queue): super().__init__() # 对父类进行初始化 self.queue = queue self.daemon = True # 子线程跟着主线程一起退出 self.start() def run(self): """ 1、让他始终去运行, 2、去获取queue里面的任务, 3、然后给任务分配函数去执行(获取任务在执行) :return: """ while True: func, args, kwargs = self.queue.get() # 从队列中获取任务 func(*args, **kwargs) self.queue.task_done() # 计数器 执行完这个任务后 (队列-1操作) # # def join(self): # self.queue.join() class MyPool(object): """ 在任务来到之前,提前创建好线程,等待任务 """ def __init__(self, num): # 线程数量 self.num = num self.queue = queue.Queue() for i in range(self.num): MyThread(self.queue) def apply_async(self,func,args=(),kwargs={}): self.queue.put((func, args, kwargs)) def join(self): self.queue.join() # 等待队列里面的任务处理完毕 def func1(): print(threading.current_thread().getName()) time.sleep(2) if __name__ == '__main__': start = time.time() pool = MyPool(3) # 实例化一个线程池 for i in range(4): pool.apply_async(func1) pool.join() print('运行的时间{}秒'.format(time.time()- start))
>>>结果
Thread-1
Thread-2
Thread-3
Thread-1
运行的时间4.011605739593506秒