消息队列:
kafka只有一种模式:topic主题模式
kafka已经成为大数据业界主流

storm简介
storm是一个分布式的实时数据分析系统,底层基于zeroMQ做数据传输。使用clojure语言开发核心模块
storm速度非常快,能达到亚秒级(200sm)
同类产品:
sparkStreaming:也是做实时分析的,速度是秒级:1s-5s。
问题:
flume连接kafka?
kafka连接storm?
storm组件:
Nimbus:老大,storm的发号施令者。(相当于hadoop中的namenode)
Supervisor(管理人,检查员):小弟,具体业务执行者。(相当于hadoop中的datanode)
zookeeper:集群资源管理者,监听整个集群的健康状态。
核心四大要素
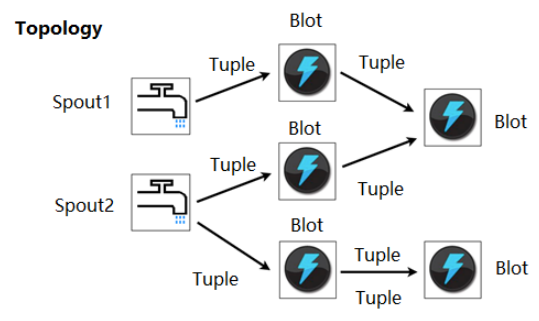
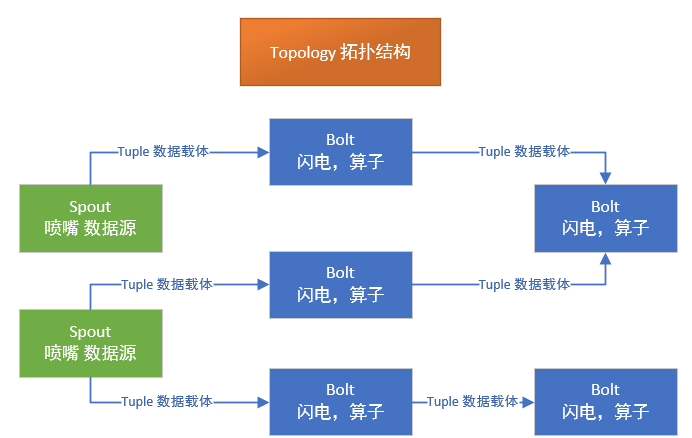
topology:拓扑,代表整修同整个数据处理过程
spout:喷嘴,就是数据源
tuple:数据载体,内部类似map(key,value),value类型一旦定义,不能存放其他类型的数据。Tuple不太一样,key一般是string类型,value类型不定,数据结构不定。
Tuple的切割时间不是任意确定的。需要经过多次的尝试。没有最好的时间,只有最合适的时间。
bolt:(闪电)算子,内部需要我们自己定义一些处理逻辑,而且一个topology中可以有多个bolt。并且一个bolt可以接受多个数据来源,并且有多个出处。

jvm?java虚拟机,随着技术的发展,java有很多衍生语言。scala、clojure。同样编译成.class,通过jvm来执行。
1、安装storm
解压即可
cd /usr/local/src/storm/apache-storm-0.9.3/conf vi storm.yaml
storm.zookeeper.servers: - "hadoop01" - "hadoop02" - "hadoop03" # nimbus.host: "hadoop01" storm.local.dir: "/usr/local/src/storm/apache-storm-0.9.3/tmp"
参数说明:
strom.zookeeper.servers 配置zk集群
nimbus.host 配置numbus所在服务器
storm.local.dir 配置临时文件所在路径
启动storm
1、启动主服务器,Nimbus
cd /usr/local/src/storm/apache-storm-0.9.3/bin
./storm ui >/dev/null 2>&1 & #启动UI Web界面,访问端口8080
./storm nimbus >/dev/null 2>&1 & #启动nimbus服务
附:配置从机(supervisor)
1、复制storm到从机
cd /usr/local/src
scp -r storm root@hadoop02:/usr/local/src/
scp -r storm root@hadoop03:/usr/local/src/
2、复制配置文件到从机
scp /etc/profile root@hadoop02:/etc/profile
scp /etc/profile root@hadoop03:/etc/profile
3、启动supervisor
./storm supervisor >/dev/null 2>&1 &
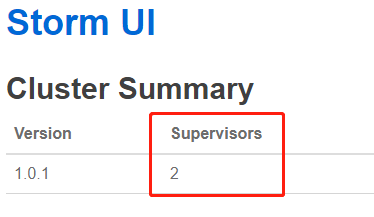
查看状态:
http://hadoop01:8080/index.html

kafka的安装
1、下载kafka
下载地址:https://www.apache.org/dyn/closer.cgi?path=/kafka/1.0.0/kafka_2.11-1.0.0.tgz
2、注:kafka需要zookeeper监控,所以需要先行安装zookeeper
解压kafka
cd /usr/local/src/kafka/kafka_2.10-0.10.0.1/config
vi server.properties
broker.id=0 #当前server编号 log.dirs=/usr/local/src/kafka/kafka_2.10-0.10.0.1/tmp/kafka-logs #日志存储目录 zookeeper.connect=hadoop01:2181,hadoop02:2181,hadoop03:2181 #配置zookeeper集群 advertised.host.name=hadoop01 #配置当前host advertised.port=9092