

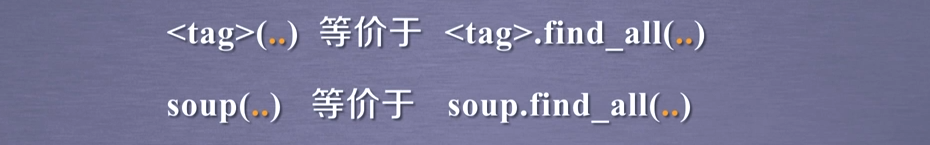

import requests
import re
from bs4 import BeautifulSoup
url = "http://python123.io/ws/demo.html"
r = requests.get(url)
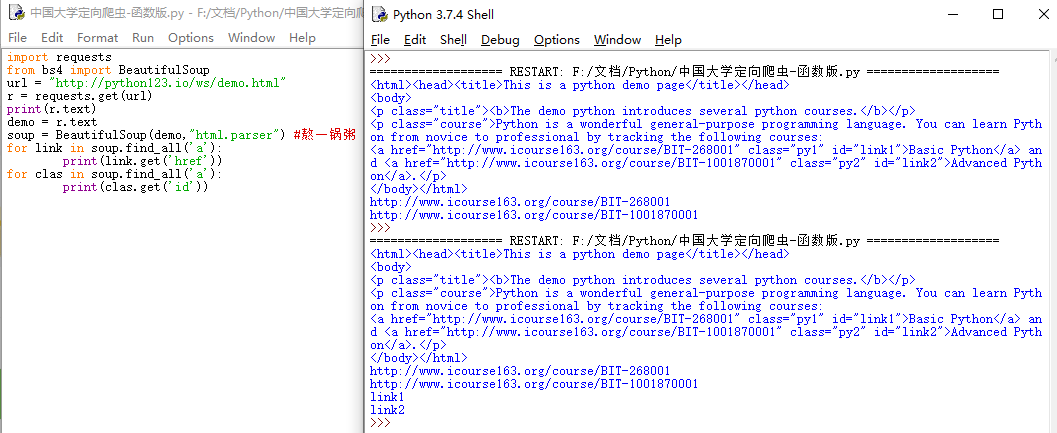
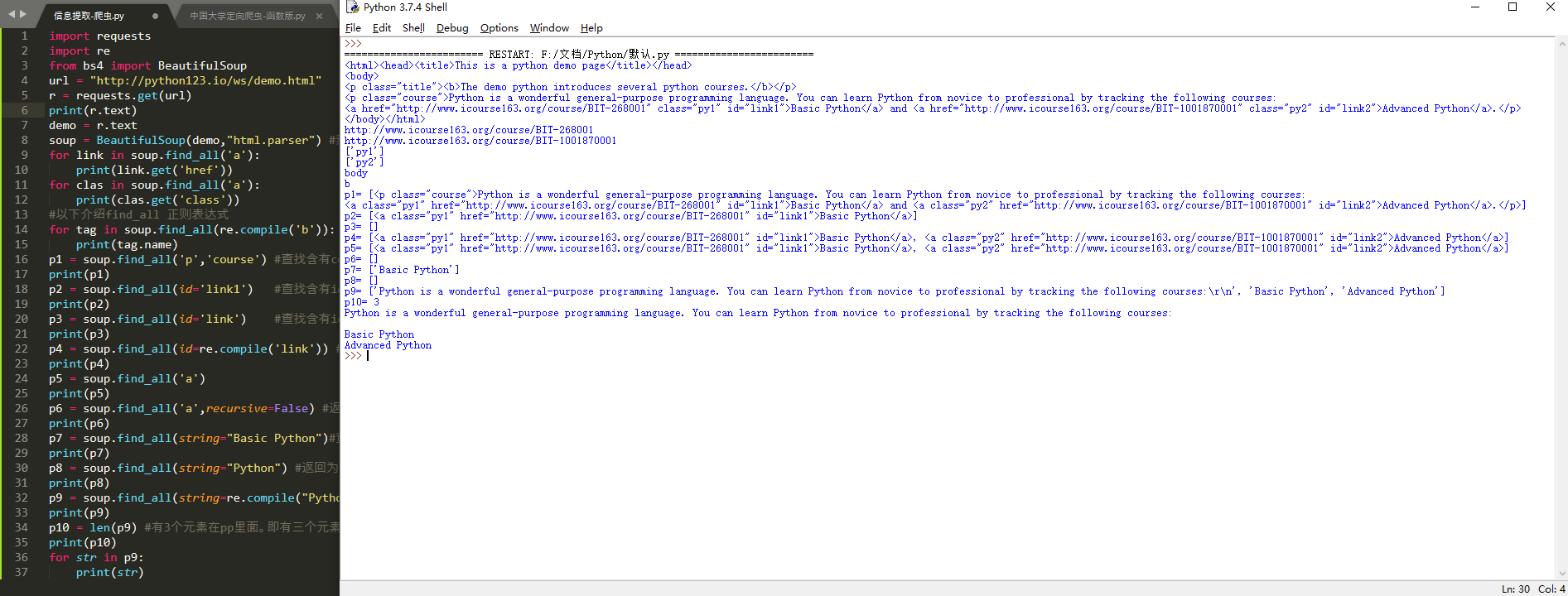
print(r.text)
'''
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>
</body></html>
'''
demo = r.text
soup = BeautifulSoup(demo,"html.parser") #熬一锅粥
#------- 以下四句通常可获取到下载链接 -----------
for link in soup.find_all('a'): #一个link就是一个<a>...</a>
print('link:::',link) # 输出内容为:<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>
print(link.get('href')) #获取当前link(a)的href对于的内容 输出内容为:http://www.icourse163.org/course/BIT-268001
for clas in soup.find_all('a'):
print(clas.get('class'))
#以下介绍find_all 正则表达式
for tag in soup.find_all(re.compile('b')): #查找所有以b开头的标签,第一个属性
print(tag.name)
p1 = soup.find_all('p','course') #查找含有course的p标签内容
print('p1:::',p1)
p2 = soup.find_all(id='link1') #查找含有id='link1'属性的标签内容,注意:属性不等于文本
print('p2:::',p2)
p3 = soup.find_all(id='link') #查找含有id='link'属性的标签内容,没有,所以返回未空,即[]
print('p3:::',p3)
p4 = soup.find_all(id=re.compile('link')) #使用正则表达式查找id属性含有link的内容
print('p4:::',p4)
p5 = soup.find_all('a') #返回不为空,说明soup的子孙节点含有a标签(查子节点以及孙结点及其以下结点)
print('p5:::',p5)
p6 = soup.find_all('a',recursive=False) #返回为空,说明soup的子节点无a标签 (不深度搜索,只查子节点,不查孙结点)
print('p6:::',p6)
p7 = soup.find_all(string="Basic Python") #查找正文为且仅为Basic Python的元素
print('p7:::',p7)
p8 = soup.find_all(string="Python") #返回为空,只匹配字符串有且仅有python的string
print('p8:::',p8)
p9 = soup.find_all(string=re.compile("Python")) #正则表达式查找含有Python的元素,返回列表类型
print('p9:::',p9)
p10 = len(p9) #有3个元素在pp里面。即有三个元素含Python
print('p10:::',p10)
for str in p9:
print('str',str)
