爬取思路:
url从网页上把代码搞下来
bytes decode ---> utf-8 网页内容就是我的待匹配的字符串
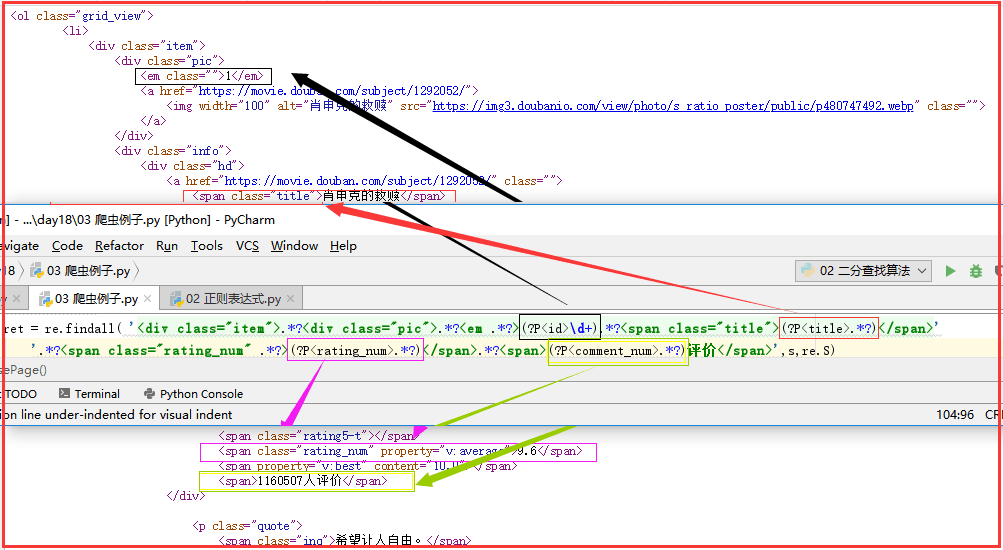
ret = re.findall(正则,待匹配的字符串), ret 是所有匹配到的内容组成的列表
import re import json from urllib.request import urlopen # (1)re.compile——爬取到文件中 def getPage(url): response = urlopen(url) return response.read().decode('utf-8') def parsePage(s): com = re.compile( '<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>d+).*?<span class="title">(?P<title>.*?)</span>' '.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>',re.S ) ret = com.finditer(s) for i in ret: yield { "id":i.group("id"), "title":i.group("title"), "rating_num":i.group("rating_num"), "comment_num":i.group("comment_num"), } def main(num): url = 'https://movie.douban.com/top250?start=%s&filter=' % num response_html = getPage(url) ret = parsePage(response_html) print(ret) f = open("movie_info","a",encoding="utf-8") for obj in ret: print(obj) data = str(obj) f.write(data + " ") f.close() count = 0 for i in range(10): # 10页 main(count) count += 25
import re
import json
from urllib.request import urlopen
# (2)re.findall——打印输出 import re import json from urllib.request import urlopen def getPage(url): response = urlopen(url) return response.read().decode('utf-8') def parsePage(s): ret = re.findall( '<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>d+).*?<span class="title">(?P<title>.*?)</span>' '.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>',s,re.S) return ret def main(num): url = 'https://movie.douban.com/top250?start=%s&filter=' % num response_html = getPage(url) ret = parsePage(response_html) print(ret) count = 0 for i in range(10): #10页 main(count) count += 25
正则表达式详解: