简介:
celery是一个分布式队列的管理工具,提供了快速管理和操作分布式任务队列的一些方法的框架
特点:
1、celery易于使用和维护,不需要进行很复杂的配置,简单的celery例子:
from celery import Celery app = Celery('hello', broker='redis://:password@ip:port/database') @app.task def hello(): return 'hello world'
2、高可靠性:程序和客户端具有失去连接进行重新尝试连接的特性,一些中间键有HA特性(hadoop主节点热备),常用的中间键有redis、 RabbitMQ 等
3、速度快:单一的一个celery进程可以在一分钟内执行数百万个任务
4、灵活性高:几乎所有的celery类都可以被继承,或者被调用;可使用框架包括: implementations, serializers, compression schemes, logging, schedulers, consumers, producers, broker transports等
支持的框架和数据库等:
1、信息传输:RabbitMQ, Redis, Amazon SQS
2、并发框架:Prefork, Eventlet, gevent, single threaded (solo)
3、结果存储:AMQP, Redis;memcached;SQLAlchemy, Django ORM;Apache Cassandra, IronCache, Elasticsearch
4、序列化格式:pickle, json, yaml, msgpack;zlib, bzip2 compression;Cryptographic message signing
支持的一些框架集合: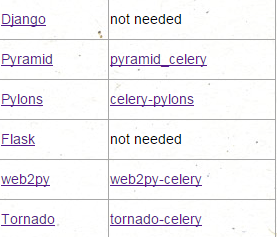
以上的这些框架并不是必须,但是这些框架能使开发更加的方便,并且有些框架提供了一些钩子用来连接和关闭数据库等
安装:
支持pip安装,一键搞定:pip install -U Celery
安装依赖:
当用pip安装celery报错的时候,可以试一下
$ pip install "celery[librabbitmq]"
$ pip install "celery[librabbitmq,redis,auth,msgpack]"
使用redis作为中间人:
安装:
使用Redis作为Broker时,再安装一个celery-with-redis
pip install -U "celery[redis]"
配置redis的地址:
参数的顺序是固定的
redis://:password@hostname:port/db_number
例如:
app.conf.broker_url ='redis://:password@ip:port/database'
设置超时时间:
两个响应之间的超时时间,单位s;redis默认的超时时间是3600s
例如:
app.conf.broker_transport_options = {'visibility_timeout': 3600} # 1 hour.
结果数据存储:
如果想把下载的数据同样存储在redis中,需要下面的配置:
app.conf.result_backend='redis://:password@ip:port/database'
账户设置:
播放的信息默认情况会被所有的虚拟主机接收,用下面得参数可以设置播放信息只会被运行中的用户接收
app.conf.broker_transport_options = {'fanout_prefix': True}
这样设置之后就能与没有进行该设置和老版本的worker进行通信了
启动:
celery -A server worker --loglevel=info
server出现如下错误
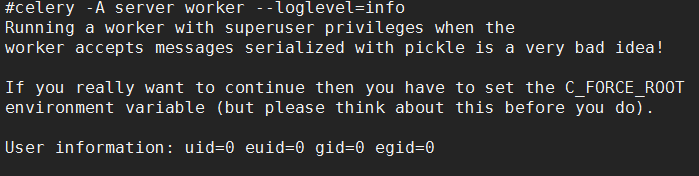
办法:设置如下属性
export C_FORCE_ROOT="true"
再次启动:
celery -A server worker --loglevel=info