这是一个简单的node.js爬虫项目,麻雀虽小五脏俱全。
本项目主要包含一下技术:
发送http抓取页面(http)、分析页面(cheerio)、中文乱码处理(bufferhelper)、异步并发流程控制(thenjs)
1、为什么选择http模块来发送Http请求下载页面
社区有很多封装好的Http请求模块,例如:request、needle、node-rest-client等,http有这些模块比拟不了的优势,可以监听抓取的字节流,我们知道要抓取的页面一般会含有汉字,一个汉字是3个字节(也有说4个字节),笔者在node中测试的是3个字节,一个英文字母是1个字节(见下图),node对中文的支持是不友好的,所以就需要借助bufferhelper来解决字节流问题,再使用 iconv-lite模块把buffer转化成utf8格式。

2、使用cheerio分析Html,让你感觉就像是在使用JQuery
3、虽说如今node上已经有异步控制的标准 async/await,但是thenjs,真的很好用,并且效率也不错,本项目主要用了它的异步并行控制 Then.each,了解更多thenjs介绍
4、本项目主要是抓取菜鸟教程的 HTML/CSS 下的8个页面,本项目先抓取 http://www.runoob.com 分析其Html,找到这8个页面的Url,再分别抓取这些页面的Html,写入到本地文件
代码 chong.js :
var http = require('http'); var Then = require('thenjs'); var BufferHelper = require('bufferhelper'); var fs = require('fs'); var cheerio = require('cheerio'); // Html分析模块 var iconv = require('iconv-lite'); // 字符转码模块 var pageUrl = []; //Url集合 var pagesHtml = []; //所有Url获取的Html的集合 var baseUrl = 'http://www.runoob.com'; main(); function main() { console.log('Start'); Then(cont => { grabPageAsync(baseUrl, cont) }).then((cont, html) => { var $ = cheerio.load(html); var $html = $('.codelist.codelist-desktop.cate1'); var $aArr = $html.find('a'); $aArr.each((i, u) => { pageUrl.push('http:' + $(u).attr('href')); }) everyPage(cont); }).fin((cont, error, result) => { console.log(error ? error : JSON.stringify(result)); console.log('End'); }) } //爬去每个Url function everyPage(callback) { Then.each(pageUrl, (cont, item) => { grabPageAsync(item, cont); }).then((cont, args) => { pagesHtml = args; createHtml(cont); }).fin((cont, error, result) => { callback(error, result); }) } //创建Html文件 function createHtml(callback) { Then.each(pagesHtml, (cont, item, index) => { var name = pageUrl[index].substr(pageUrl[index].lastIndexOf('/') + 1); fs.writeFile(__dirname + '/grapHtml/' + name, item, function(err) { err ? console.error(err) : console.log('写入成功:' + name); cont(err, index); }); }).fin((cont, error, result) => { callback(error, result); }) } // 异步爬取页面HTML function grabPageAsync(url, callback) { http.get(url, function(res) { var bufferHelper = new BufferHelper(); res.on('data', function(chunk) { bufferHelper.concat(chunk); }); res.on('end', function() { console.log('爬取 ' + url + ' 成功'); var fullBuffer = bufferHelper.toBuffer(); var utf8Buffer = iconv.decode(fullBuffer, 'UTF-8'); var html = utf8Buffer.toString() callback(null, html); }); }).on('error', function(e) { // 爬取成功 callback(e, null); console.log('爬取 ' + url + ' 失败'); }); }
运行:
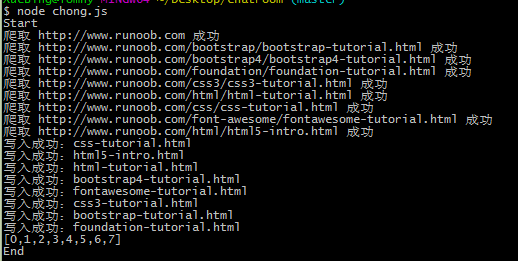
抓取的页面结果:

欢迎拍砖 :)
本文原创转载请注明出处!