前言
上一篇文章https://www.cnblogs.com/wzzgeorge/p/12952208.html 较系统的介绍了系统调用的基本原理,本文将结合系统调用中断上下文切换和进程上下文切换分析Linux内核的一般执行过程。并以fork和execve系统调用为例分析中断上下文的切换,分析execve系统调用中断上下文的特殊之处,分析fork子进程启动执行时进程上下文的特殊之处。
一、fork的中断上下文切换
fork 和 execve 也是系统调用,但相对于其他系统调用又有些特殊的地方,fork 用于创建一个子进程。
对于普通系统调用,当通过指令int $0x80 或者 syscall 触发系统调用时,系统会在当前进程的内核堆栈上保存⼀些寄存器的值,包括当前执⾏程序的用户堆栈栈顶地址(SS:ESP)、当时的状态字(EFlags)、当时的 CS:EIP的值。同时会将当前进程内核堆栈的栈顶地址、内核的状态字等放⼊CPU 对应的寄存器,并且 CS:EIP 寄存器的值会指向中断处理程序的⼊⼝,对于系统调⽤来讲是指向系统调⽤处理 的⼊⼝。最后中断处理完毕之后执行 iret 指令,就会把之前保存的关键上下文和现场恢复到 CPU 中。
对于fork系统调用,用户程序调用fork函数实际上会最终调用__do_fork函数,这个函数主要通过调用copy_process()来复制父进程的进程描述符、进程状态设置为TASK_RUNNING、采⽤写时复制技术逐⼀复制所有其他进程资源、调⽤copy_thread_tls初始化⼦进程内核栈、设置⼦进程pid等,然后调用wake_up_new_task将子进程加入就绪队列等待调度,最后系统调用返回。copy_thread_tls非常关键,因为这个函数不仅分配了子进程的内核堆栈而且对内核堆栈和thread等进程关键上下文进行了初始化,所以当子进程被调用运行时会直接从fork系统调用的下一条语句开始执行。而对于父进程来说,其关键上下文切换过程像普通系统调用一样如上文所述。
总的来说,fork和其他系统调⽤不同之处是它在陷⼊内核态之后有两次返回,第⼀次返回到原来的⽗进程的位 置继续向下执⾏,这和其他的系统调⽤是⼀样的。在⼦进程中fork也返回了⼀次,会返回到⼀个特定的点——ret_from_fork,通过内核构造的堆栈环境,它可以正常系统调⽤返回到⽤户态。

二、execve的中断上下文切换
execve系统调用用于执行一个可执行程序,我们在shell中输入ls、vim 、cat等命令时,shell会调⽤execve系统调⽤接⼝函数将命令⾏参数和环境变量传递给 可执⾏程序的main函数。execve系统调⽤接⼝函数的函数原型为:int execve(const char *filename, char *const argv[],char *const envp[])。其中 filename为可执⾏⽂件的名字,argv是以NULL结尾的命令⾏参数数组,envp同样是以NULL结尾的环境变量数组。
execve也一个⽐较特殊的系统调用。当前的可执⾏程序执⾏到execve系统调⽤时陷⼊内核态,在内核⾥⾯⽤do_execve加载可执⾏⽂件,把当前进程的可执⾏程序给覆盖掉。当execve系统调⽤返回时,返回的已经不是原来的那个可执⾏程序了,⽽是新的可执⾏程序。execve返回的是新的可执⾏ 程序执⾏的起点,静态链接的可执⾏⽂件也就是main函数的⼤致位置,动态链接的可执⾏⽂件还需要ld链接好动态链接库再从main函数开始执⾏。整体的调⽤关系为sys_execve()或__x64_sys_execve -> do_execve() –> do_execveat_common() -> __do_execve_file -> exec_binprm()-> search_binary_handler() -> load_elf_binary() -> start_thread()。
内核把当前进程的可执⾏程序覆盖掉,实际上就是重新布局用户态堆栈,如下图所示,分别将环境变量和命令行参数压入栈中,栈顶就是main函数调⽤堆栈框架,这就是程序的main函数起点的执⾏环境。
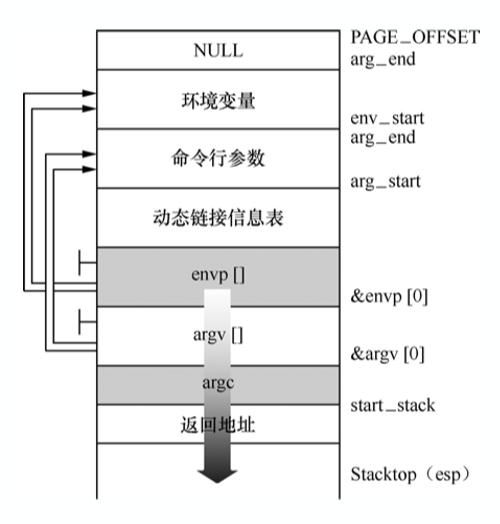
三、fork子进程启动执行时的进程上下文切换
首先要理解什么是进程上下文切换:为了控制进程的执⾏,内核必须有能⼒挂起正在CPU上运⾏的进程,并恢复执⾏以前挂起的某个进程,这种⾏为被称为进程上下文切换。进程上下文包括⽤户地址空间(程序代码、数据、⽤户堆栈等)、控制信息(进程描述符、内核堆栈等)、进程的CPU上下⽂及相关寄存器的值(这些值保存在进程描述符中)。
进程切换过程可以分为两步,一是切换⻚全局⽬录(CR3)以安装⼀个新的地址空间;二是切换内核态堆栈和进程的CPU上下⽂,因为进程的CPU上下⽂提供了内核执⾏新进程所需要的所有信息,包含所有CPU寄存器状态。需要注意的是进程描述符保存在内核堆栈的低地址处。
前面说到fork系统调用处理函数中会调用copy_thread_tls函数,分配了子进程的内核堆栈而且对内核堆栈和thread等进程关键上下文进行了初始化。那么当该子进程获得CPU开始执行时,执行上述切换操作,然后开始运行。
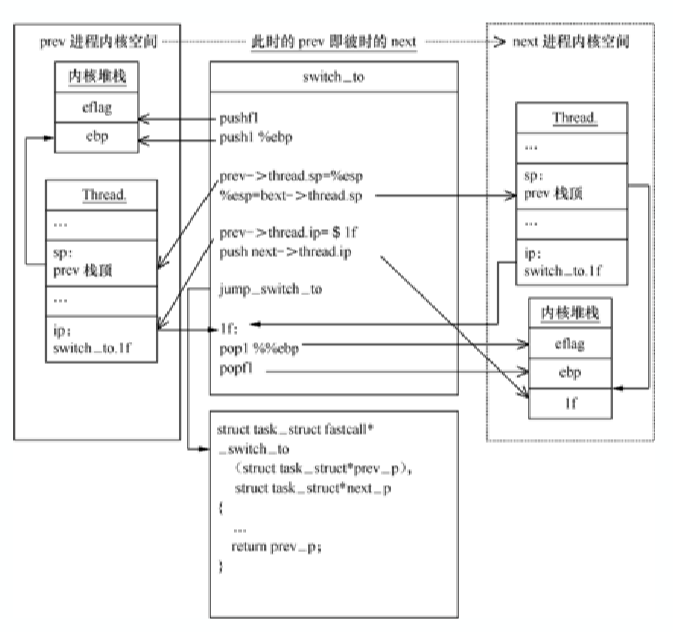
还有一个很重要的问题是,父进程和子进程fork完成之后的返回值不同,进而可以执行不同的程序分支,这是怎么实现的呢?这是因为__do_fork() 在返回后,会从内核堆栈中的eax读取返回地址,而eax在copy_thread函数中被强制设置为0,因此子进程的返回值就是0。
四、Linux内核的一般执行过程
中断是在⼀个进程当中从进程的⽤户态到进程的内核态,或从进程的内核态返回到进程的⽤户态,其中断上下⽂切换过程中最关键的栈顶寄存器sp和指令指针寄存器ip 是由CPU协助完成的;⽽进程切换是在不同的进程间进行切换,完全由内核来实现,其中栈顶寄存器sp切换是通过进程描述符的thread.sp实现的,指令指针寄存器ip的切换是在内核堆栈切换的基础上巧妙利⽤call/ret指令实现的。这是二者的主要区别,但⼀般进程上下⽂切换是嵌套在中断上下⽂切换中的。
综上所述,linux内核的一般执行过程可以归纳如下:
1. 正在运⾏的⽤户态进程X。
2. 发⽣中断(包括异常、系统调⽤等),CPU完成load cs:rip(entry of a specific ISR),即跳转到中断处理程序⼊⼝。
3. 中断上下⽂切换,包括swapgs指令保存现场、加载当前进程内核堆栈栈顶地址到RSP寄存器、:将当前CPU关键上下⽂压⼊进程X的内核堆栈。此时已经完成进程X的⽤户态切换到进程X的内核态。
4. 中断处理过程中或中断返回前调⽤了schedule函数,其中完成了进程调度算法选择next进程、进程地址空间切换、以及switch_to关键的进程上下⽂切换等。
5. switch_to调⽤了__switch_to_asm汇编代码做了关键的进程上下⽂切换。将当前进程X的内核堆栈切换到进程调度算法选出来的next进程(本例假定为进程Y)的内核堆 栈,并完成了进程上下⽂所需的指令指针寄存器状态切换。之后开始运⾏进程Y(这⾥进程Y曾经通过以上步骤被切换出去,因此可以从switch_to下⼀⾏代码继续执⾏)。
6. 中断上下⽂恢复,与(3)中断上下⽂切换相对应。注意这⾥是进程Y的中断处理过程中,⽽(3)中断上下⽂切换是在进程X的中断处理过程中,因为内核堆栈从进程X 切换到进程Y了。
7. iret - pop cs:rip/ss:rsp/rflags,从Y进程的内核堆栈中弹出(3)中对应的压栈内容。此时完 成了中断上下⽂的切换,即从进程Y的内核态返回到进程Y的⽤户态。
8. 继续运⾏⽤户态进程Y。