1.活体检测面临的问题
在一些业务需要中,需要识别场景中的用户是否为"真人",因此需要活体检测技术,这篇文章将针对当前行业中的活体检测技术进行总结。
在人脸检测中,攻击者往往会通过PA(Presentation Attacks)对系统进行攻击,常见的PA操作包括打印照片,虚假录制视频,面部伪装,3D人脸面具等方式,如果没有活体检测,系统的安全性会比较低。在2017年之前,行业主要的实现方向是使用传统的机器视觉方法,在17年之后,较多的使用CNN卷积网络来辅助性能,在2019年CVPR中就有多篇关于活体检测的Paper,目前已成热门方向。
2.常见活体检测方式调研
1.传统的活体检测处理方法
Ⅰ:基于传统图像处理的活体检测
传统的活体检测主要的思路是捕捉图像的纹理信息,从而进行分类。
这类方法整体的流程大致如下:
1:图像预处理,对图像进行裁剪,对齐,分割等操作,同时对图像的空间进行变换和叠加,通过从时域到频域,空域或者改变其颜色空间来进行操作。
2:使用如SIFT,HOG,LBP,SURF以及各种魔改变种来对图像的特征进行提取。
3:使用如降维,编码,多通道组合的方法进行进一步的特征提取,进行分类前的预处理
4:使用SVM/LR等特征分类器进行二分类
Ⅱ:传统方法论文思想总结:
①:通过活体和PA攻击纹理统计特性不一致,基于纹理特征进行分类
比较具有代表性的论文:
1:Face Spoofing Detection Using Colour Texture Analysis
通过HSV空间人脸多级LBP特征 + YCbCr空间人脸LPQ特征
Link:https://ieeexplore.ieee.org/abstract/document/7454730
2: Face anti-spoofing based on color texture analysis
通过观测在频域上分布不同,先区分活体还是照片攻击 (因为照片中的人脸提取的频域分布不同),若判别上述结果是活体,再设计一个纹理LBP分类器,来区分活体还是屏幕攻击(因为屏幕视频中人脸频率分布与活体相近)
Link:https://ieeexplore.ieee.org/abstract/document/735128
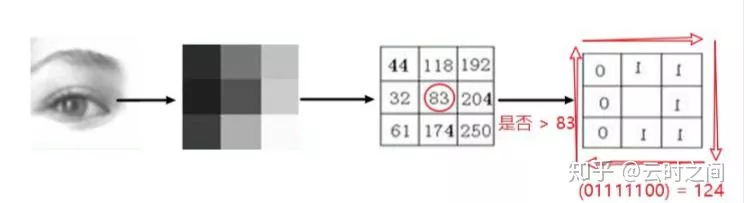
在这类论文中,活体和PA纹理不一致,如下图:

可以通过LBP(局部二值)来提取其纹理特征,再对LBP进行分类:
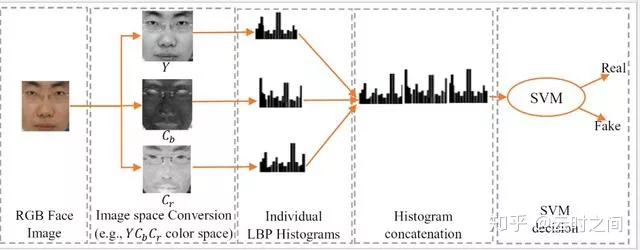
使用到的模型架构:
②:基于纹理统计特性进行分类
代表论文:
1:Chromatic cooccurrence of local binary pattern for face presentation attack detection
Link:https://ieeexplore.ieee.org/document/8487325
模型架构:

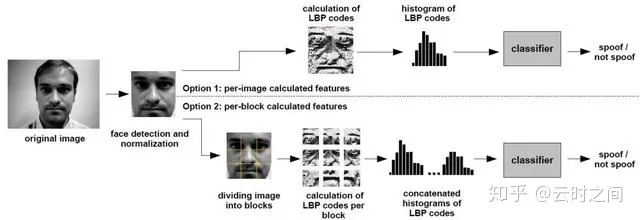
②:On the effectiveness of local binary patterns in face anti-spoofing
Link:https://ieeexplore.ieee.org/abstract/document/6313548
模型架构:
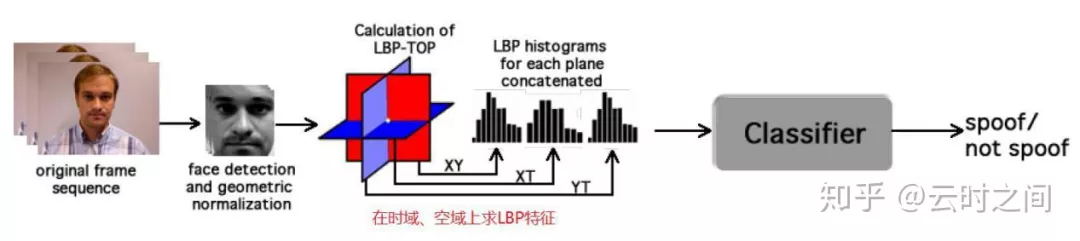
③:LBP-TOP based countermeasure against face spoofing attacks
Link:http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=271BCC281BDD5D9B869D3DB92A278BB0?doi=10.1.1.493.6222&rep=rep1&type=pdf
模型架构:
④:Face Liveness Detection with Component Dependent Descriptor
这篇文章也是用的纹理统计,但是比较有意思的是使用了面部分割的方法
模型流程:
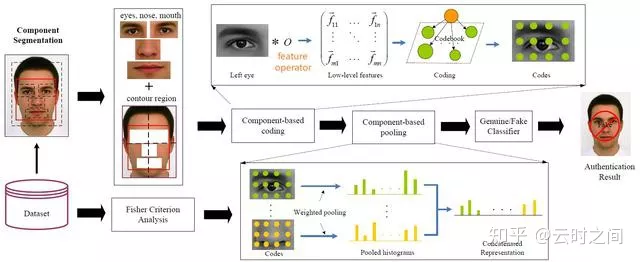
1:检测面部位置,将面部分割为轮廓,面部,左右眼,鼻,嘴,六个区域
2:提取面部特征,LBP+HOG,将不同部位进行特征联结
3: SVM分类器进行二分类
以上为比较传统的机器学习的活体检测方法,虽然这些算法有一些历史,但大致流程不变,我们仍可以学习其处理的内核精神,下面我们将介绍下现在比较主流的基于深度学习的活体检测!
2.深度学习活体检测方法
An original face anti-spoofing approach using partial convolutional neural network
Link:ieeexplore.ieee.org/doc
模型架构:
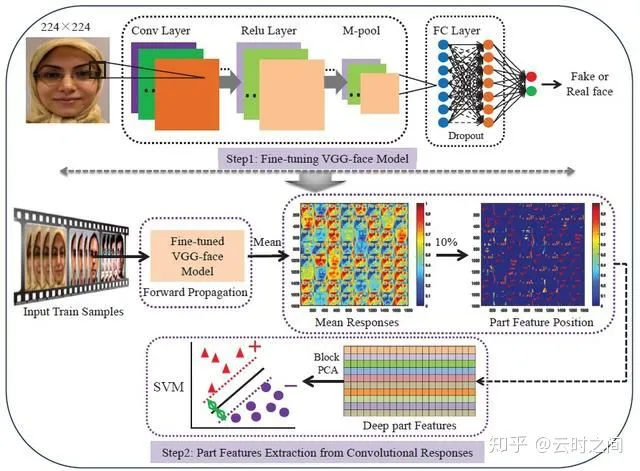
和传统的方法结构类似,只是使用了VGG进行特征提取,通过CNN网络端到端学习anti-spoofing的表示空间
Face anti-spoofing using patch and depth-based cnns
Link:cvlab.cse.msu.edu/pdfs/
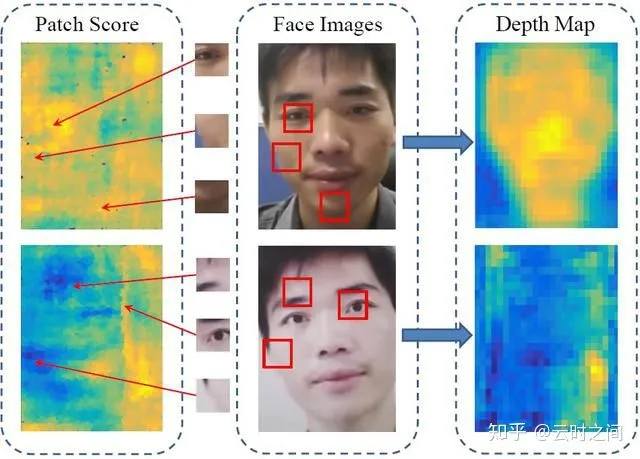
基本思想:基于纹理的特征提取
主要表现为:局部特征+整体深度图
人脸活体和PA的局部区域提取出来的特征不同,因此得到的统计特征不同。同时采用图片等攻击方法的PA模型往往呈现为扁平,缺少面部深度特征,如下图,人脸活体会有深度图状。
模型框架:
模型主要使用了两个CNN框架:
patch-based CNN:
端到端训练的,并为每个从人脸图像中随机抽取的patch打一个分数,取平均分。
使用patch的好处:
1. 增加训练数据。
2. 不用resize整张脸,保持原本的分辨率。
3. 在局部检测可用于活体检测的特征时,设定更具挑战性的约束条件,加强特征提取的性能。
输入:相同大小的不同patches的RGB, HSV, YCbCr特征图等。
输出:pacth spoof scores。
depth-based CNN:
完全卷积网络(FCN),对人脸图像的深度图进行估计,并提供一个真实度评分。
研究表明高频部分对anti-spoofing非常重要,为避免对原图进行resize而损失图片的高频部分,因此使用FCN以无视输入特征图的size。
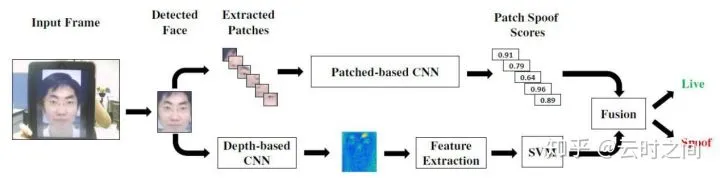
并且还用到了两个监督信号:
1:patch spoof scores
从人脸图像中挑选某些局部区域patches,根据patch内的文理统计特征计算一个patch spoof scores,用于监督patch-based CNN部分。
2:深度图Depth Map
面部深度图显示了面部不同位置的深度信息,据此计算深损失,用于监督depth-based CNN部分。
整个模型的架构:

但是这个模型性能一般,甚至比不上一些传统的算法。
Deep Convolutional Dynamic Texture Learning with Adaptive Channel-discriminability for 3D Mask Face Anti-spoofing
*这篇文章值得读一下,这篇文章主要是针对3D面具的攻击。3D面具的攻击和其他的PA攻击不同,由于面具覆盖了脸部,面具是无法呈现出人脸的脸部运动的,真实的人脸的面部运动更加的细腻,精细,比如苹果肌,皱纹,眨眼,脸部肌肉的微动等等,我们可以认为是动态纹理的不同。
这套算法基本流程与之前平面处理的不太一致:
1:首先需要对视频进行预处理,这里用到了CLNF模型,来检测面部,对面部的68个特征点进行检测,并对面部进行align对齐。
CLNF模型论文地址:cl.cam.ac.uk/research/r
CLNK模型的介绍:

2:通过VGG网络提取特征
从视频流中连续的5帧选择其中的一帧来作为VGG网络的输入,3*3卷积网络输出的特征图作为光流提取的输入。
3:分类
使用SVM进行分类
模型结构:
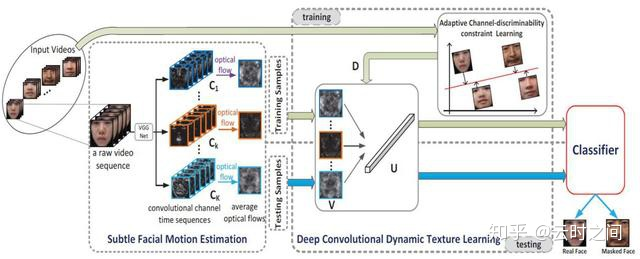
网络结构:

结果:
①:Intra-dataset
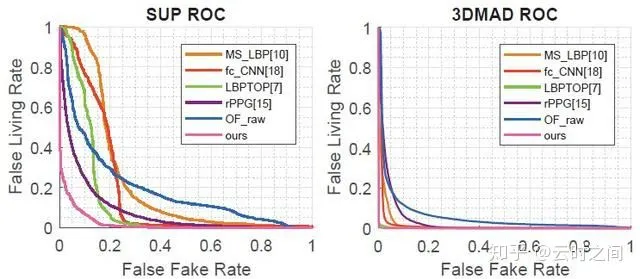
②:Cross-dataset

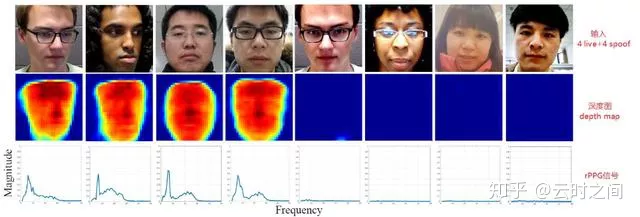
Learning Deep Models for Face Anti-Spoofing: Binary or Auxiliary Supervision
这篇文章还是很有意思的,性能超过了传统方法。整篇文章的亮点在于Non-rigid Registration部分来对齐各帧人脸的非刚性运动,然后再去让RNN学习。
模型的基本思想:
①:基于纹理:活体和PA攻击的面部深部图不一致
②:基于生物信号:可以通过面部信息来测量相关的RRPG(心率)
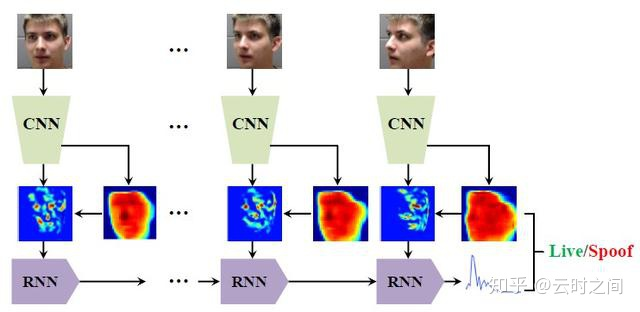
模型的结构:

网络结构:
CNN
若干block串联,每个block包括三个conv+exponential linear+bn和一个pooling。
每个block输出特征图经过resize layer将其resize为64×64,并将其通道维联结。
联结后的特征图经过两个branches,一个估计深度图depth map,另一个估计特征图feature map。
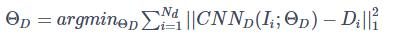
RNN

Non-rigid Registration部分*
根据估计的3D面部形状图S对特征图feature map进行对齐,保证RNN跟踪并学习面部同一个区域的特征随时间和物体的变化。RNN不用考虑表情、姿态、背景的影响。

这里最有价值的就是为什么设计这个对齐网络:
结合做运动识别的任务进行思考,做运动识别时只需简单把连续帧 合并起来喂进网络就行了,是假定相机是不动的,对象在运动
而文中需要对连续人脸帧进行pulse特征提取,主要对象是人脸上对应ROI在 temporal 上的 Intensity 变化,所以就需要把人脸当成是相机固定不动。
实验结果:但是没有找到开源代码,比较遗憾。
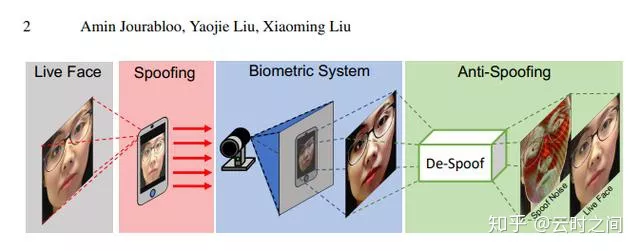
Face De-Spoofing: Anti-Spoofing via Noise Modeling
*这篇论文比较抽象,代码虽然开源但质量一般,约等于没有开源~
实际部署起来也比较难,主要针对print, replay, make-up类别的PA
以往的Anti-Spoofing在基于深度学习方法做的时候通常当做一个二分类,输出是Real/Spoof,内部模型是一个黑箱。这个方法将De-Spoofing的模型的内部机理考虑了进去。
文章中假设:对于照片、视频播放来进行的Spoof会引入噪声,而这个噪声普遍存在且可重复,因此,设公式为:

其中的x是原图,是一个与原始图片N(x)有关的噪声函数,这个公式就是算法的核心。通过估计x^,N(x^)并去除spoof noise、以重建x^。若给定x=x^,则其spoof noise = 0。
退化图像的频谱分析:
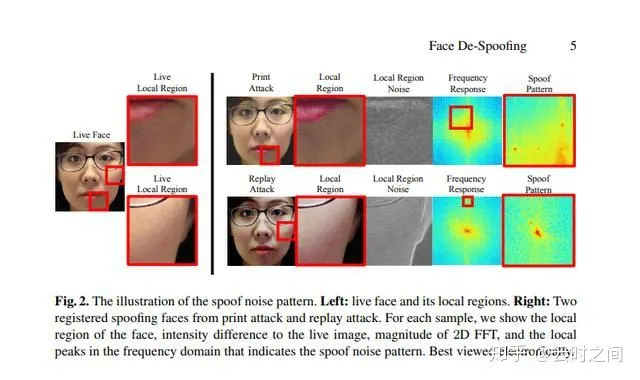
造成图像退化的几个原因:
1:色域:spoof介质色域更窄,颜色空间会出现错误
2: 显示干扰:相机本身在输出图像的时候,会出现颜色近似,下采样的过程,这样会导致像素扰动,模糊等问题。
3:介质:存放图像的介质会产生比如反射,表面透明度等变化
4::CMOS和CCD的传感器阵列的成像矩阵会有光干涉,某些情况下会产生失真和摩尔纹。
以上这些噪声干扰往往都是可加性的,因此也是可以消除,重建的。
模型结构:
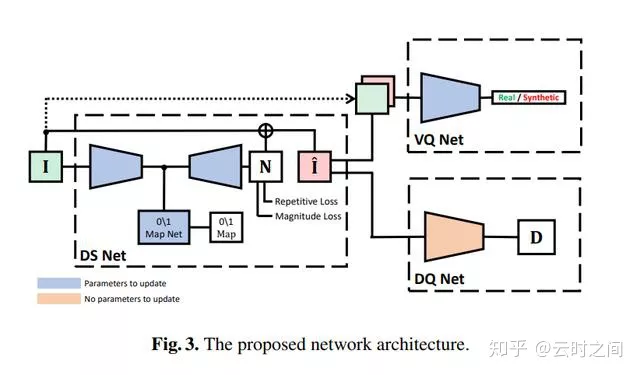
模型分为三个部分:
输入:256*256*6,RGB+HSV的颜色空间
1:DS Net

2:DQ Net
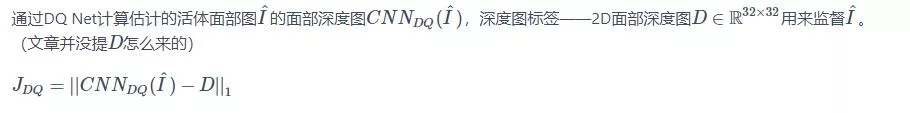
3:VQ Net

效果:

Exploiting Temporal and Depth Information for Multi-frame face Anti-Spoofing
基本思想:在视频流中,物体的运动有利于提取人脸深度信息,可将面部运动和面部深度信息结合,用于活体检测。
文章给出了很好的思路和结论来使用多帧,这也是继MSU使用多帧来预测rPPG频域后的一大进步,这样未来face anti-spoofing将更多focus在多帧上;而不是单帧深度,单帧color texture,这些方向上。
具体的文章解读在后续会单独拿出一篇文章了解.
总结:
