前言
自动驾驶、手势控制、美颜相机
发展:
- 50-60s 看
- 70-90s 看懂
- 90s-2012 识别
- 2012++理解
传统方法
直线检测、形状检测
ADAS(Advanced Driver Assistant System)高级智能驾驶系统 见:ADAS系统-ADAS|车道偏离预警|前车碰撞预警|行人识别|3D高清全景 http://www.adas.cc/adas/#_20
ADAS的核心功能集中在前车碰撞预警(FCW)、车道偏离预警(LDW)、行人检测预警(PCW)等。
检测圆形:找到一个点到边缘(由边缘检测来)的距离全部相等时,则判定区域覆盖为圆形。
机器学习方法
特征+模型

CNN 卷积层,提取特征类似HOG、LBP、Haar
前面卷积和池化,提取特征
全连接FC,或softmax(本质是将逻辑回归的二分类问题向多分类扩展),分类
卷积核(kernel、window)得到特征图(feature map)
sliding window
原始图滑窗很慢,改为在特征图上滑窗就很快
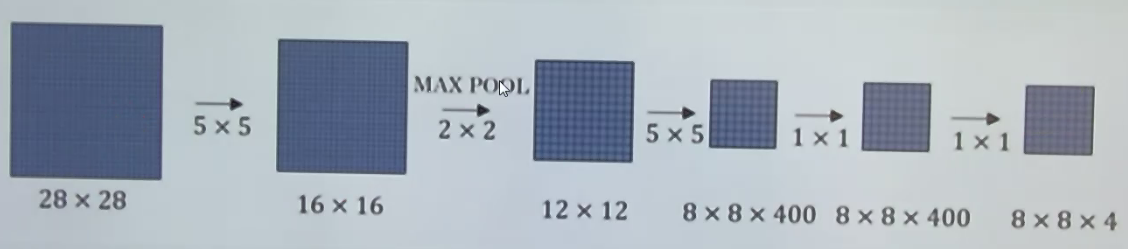
滑窗大量重复信息
R-CNN(Regions with CNN features)
Region proposals 500-2000个可能区域。先类似K-means聚类,每一个可能存在东西的部分都进模型检测
NMS 抑制掉周围方块
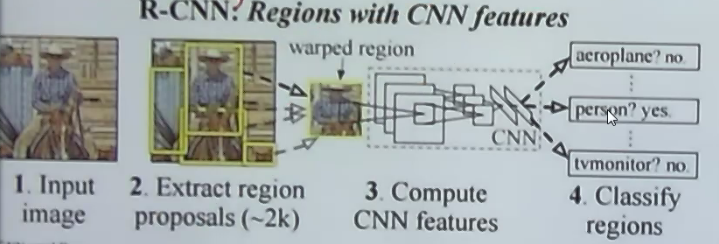

还是感觉R-CNN框太多了,还是无法实时。
RCNN 提取特征用的是神经网络+SVM分类
Fast RCNN 特征+分类都是神经网络
Faster RCNN ,Region proposals也用神经网络(RPN寻找潜在region)
YOLO 图像分成若干cell,只回归一次,可将图像中所有物体全都提取出来。非常先进、豪华。
bounding box 位置定位
x,y,w,h连续变量——>回归(解决的是在哪)
侦测到物体在哪,画个框
semantic segmantation
图像语义分割
更精细,像素级
卷积:

上卷积(反卷积)
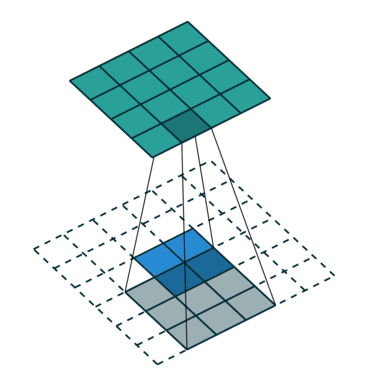
端对端
较新的技术:
MASK-RCNN 反卷积形成Mask
U-NET层数比较少,医学图像
【其他资料】
关于semantic segmentation的几篇论文 - Marcovaldong的博客 - CSDN博客 https://blog.csdn.net/MajorDong100/article/details/78958656
计算机视觉之语义分割 http://blog.geohey.com/ji-suan-ji-shi-jue-zhi-yu-yi-fen-ge/