前言
本文介绍一个Pytorch模型的静态分析器 PyTea,它不需要运行代码,即可在几秒钟之内扫描分析出模型中的张量形状错误。文末附使用方法。
本文转载自机器之心
编辑:CV技术指南
关注公众号
张量形状不匹配是深度神经网络机器学习过程中会出现的重要错误之一。由于神经网络训练成本较高且耗时,在执行代码之前运行静态分析,要比执行然后发现错误快上很多。
由于静态分析是在不运行代码的前提下进行的,因此可以帮助软件开发人员、质量保证人员查找代码中存在的结构性错误、安全漏洞等问题,从而保证软件的整体质量。
相比于程序动态分析,静态分析具有不实际执行程序;执行速度快、效率高等特点而广受研究者青睐,目前,已有许多分析工具可供研究使用,如斯坦福大学开发的 Meta-Compilation(Coverity)、利物浦大学开发的 LDRA Testbed 等。
近日,来自韩国首尔大学的研究者们提出了另一种静态分析器 PyTea,它可以自动检测 PyTorch 项目中的张量形状错误。在对包括 PyTorch 存储库中的项目以及 StackOverflow 中存在的张量错误代码进行测试。结果表明,PyTea 可以成功的检测到这些代码中的张量形状错误,几秒钟就能完成。

-
论文地址:https://arxiv.org/pdf/2112.09037.pdf
-
项目地址:https://github.com/ropas/pytea
几秒就能查找张量形状错误的 PyTea
PyTea 工具可以静态地扫描 PyTorch 程序并检测可能的形状错误。PyTea 通过额外的数据处理和一些库(例如 Torchvision、NumPy、PIL)的混合使用来分析真实世界 Python/PyTorch 应用程序的完整训练和评估路径。
PyTea 的工作原理是这样的:给定输入的 PyTorch 源,PyTea 静态跟踪每个可能的执行路径,收集路径张量操作序列所需的张量形状约束,并决定约束满足与否(因此可能发生形状错误)。
具体来说:如下图所示, PyTea 首先将原始 Python 代码翻译成一种内核语言,即 PyTea 内部表示(PyTea IR)。然后,它跟踪转换后的 IR 的每个可能执行路径,并收集有关张量形状的约束,这些约束规定了代码在没有形状错误的情况下运行的条件。 PyTea 将收集到的约束集提供给 SMT(Satisfiability Modulo Theories)求解器 Z3,以判断这些约束对于每个可能的输入形状都是可满足的。根据求解器的结果,PyTea 会得出结论,哪条路径包含形状错误。如果 Z3 的约束求解花费太多时间,PyTea 会停止并发出「don’t know」提示。
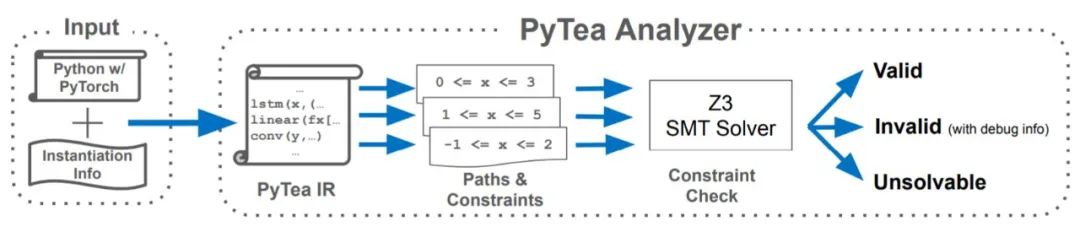
PyTea 的整体结构。
PyTea 由两个分析器组成,在线分析器:node.js (TypeScript / JavaScript);离线分析器:Z3 / Python。
-
在线分析器:查找基于数值范围的形状不匹配和 API 参数的滥用。如果 PyTea 在分析代码时发现任何错误,它将停在该位置并将错误和违反约束通知用户;
-
离线分析器:生成的约束传递给 Z3 。Z3 将求解每个路径的约束集并打印第一个违反的约束(如果存在)。
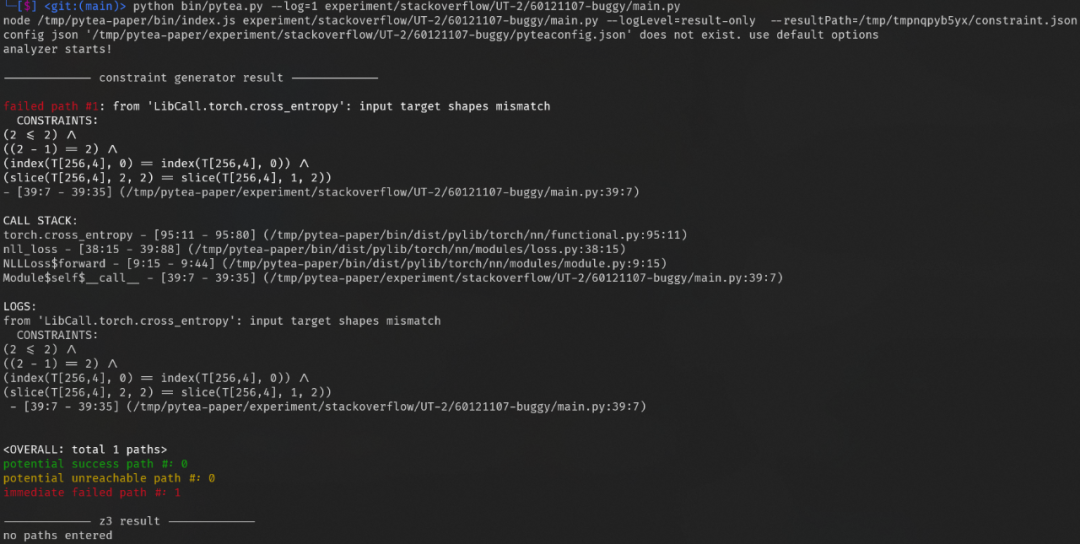
我们先来看下结果展示,在线分析器发现错误:
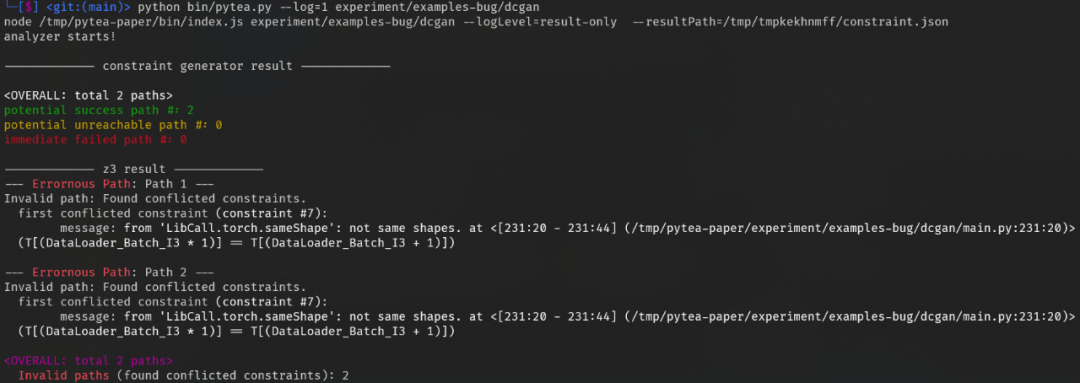
离线分析器发现错误:
为了更好的理解 PyTea 执行静态分析过程,下面我们介绍一下主要的技术细节,包括 PyTorch 程序结构、张量形状错误、PyTea IR 等,以便读者更好的理解执行过程。
首先是 PyTorch 程序结构,PyTorch、TensorFlow 和 Keras 等现代机器学习框架需要使用 Python API 来构建神经网络。使用此类框架训练神经网络大多遵循如下四个阶段的标准程序。
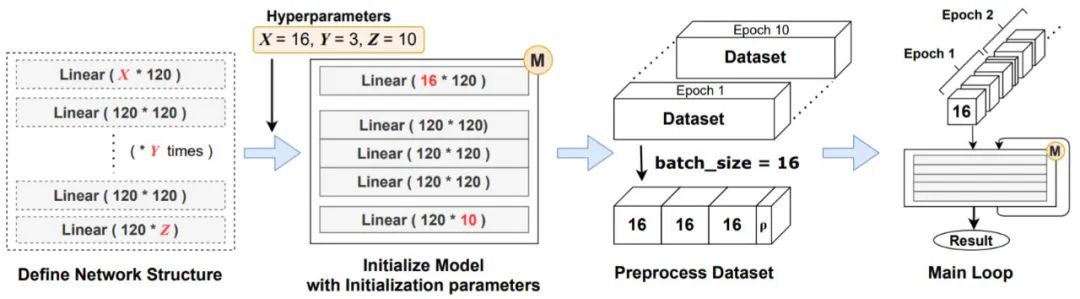
在 PyTorch 中,常规神经网络训练代码的结构。
训练模型需要先定义网络结构,图 2 为一个简化的图像分类代码,取自官方的 PyTorch MNIST 分类示例:
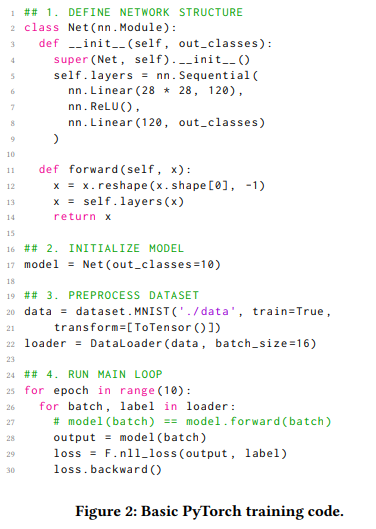
![]()
在这里,上述代码首先定义一系列神经网络层,并使它们成为单一的神经网络模块。为了正确组装层,前一层的返回张量必须满足下一层的输入要求。网络使用超参数的初始化参数进行实例化,例如隐藏层的数量。接下来,对输入数据集进行预处理并根据网络的要求进行调整。从该阶段开始,每个数据集都被切成较小的相同大小的块(minibatch)。最后,主循环开始,minibatch 按顺序输入网络。一个 epoch 是指将整个数据集传递到网络的单个循环,并且 epoch 的数量通常取决于神经网络的目的和结构。除了取决于数据集大小的主训练循环之外,包括 epoch 数在内,训练代码中的迭代次数在大多数情况下被确定为常数。
在构建模型时,网络层之间输入、输出张量形状的不对应就是张量形状错误。通常形状错误很难手动查找,只能通过使用实际输入运行程序来检测。下图就是典型的张量形状错误(对图 2 的简单修改),如果不仔细查看,你根本发现不了错误:

对于张量形状错误(如上图的错误类型),PyTea 将原始 Python 代码翻译成 PyTea IR 进行查找,如下图是 PyTea IR 示例:

上面提到,PyTea 会跟踪转换后的 IR 的每个可能执行路径,并收集有关张量形状约束。其实约束是 PyTorch 应用程序所需要的条件,以便在没有任何张量形状误差的情况下执行它。例如,一个矩阵乘法运算的两个操作数必须共享相同的维数。下图显示了约束的抽象语法:

约束的抽象语法部分截图
如何使用 PyTea
首先,安装环境要求:node.js >= 12.x,python >= 3.8,z3-solver >= 4.8。
安装和使用可参考以下代码:
# install node.js
sudo apt-get install nodejs
# install python z3-solver
pip install z3-solver
# download pytea
wget https://github.com/ropas/pytea/releases/download/v0.1.0/pytea.zip
unzip pytea.zip
# run pytea
python bin/pytea.py path/to/source.py
# run example file
python bin/pytea.py packages/pytea/pytest/basics/scratch.py编译代码:
# install dependencies
npm run install:all
pip install z3-solver
# build
npm run build
相关文章阅读:
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
在公众号中回复关键字 “入门指南“可获取计算机视觉入门所有必备资料。

其它文章