一、环境准备
本机环境:jdk11、scala2.12、maven3.6
新建一个maven项目,pom如下
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.wzy</groupId> <artifactId>flink-project</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-scala_2.12</artifactId> <version>1.10.2</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-scala_2.12</artifactId> <version>1.10.2</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_2.12</artifactId> <version>1.10.2</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.4.6</version> <executions> <execution> <!-- 声明绑定到 maven 的 compile 阶段 --> <goals> <goal>compile</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.0.0</version> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>
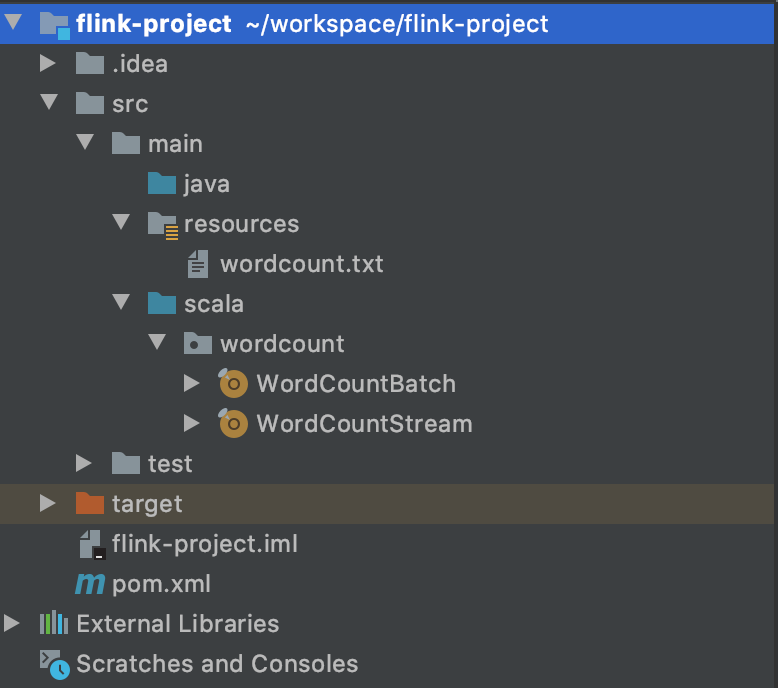
项目结构如下
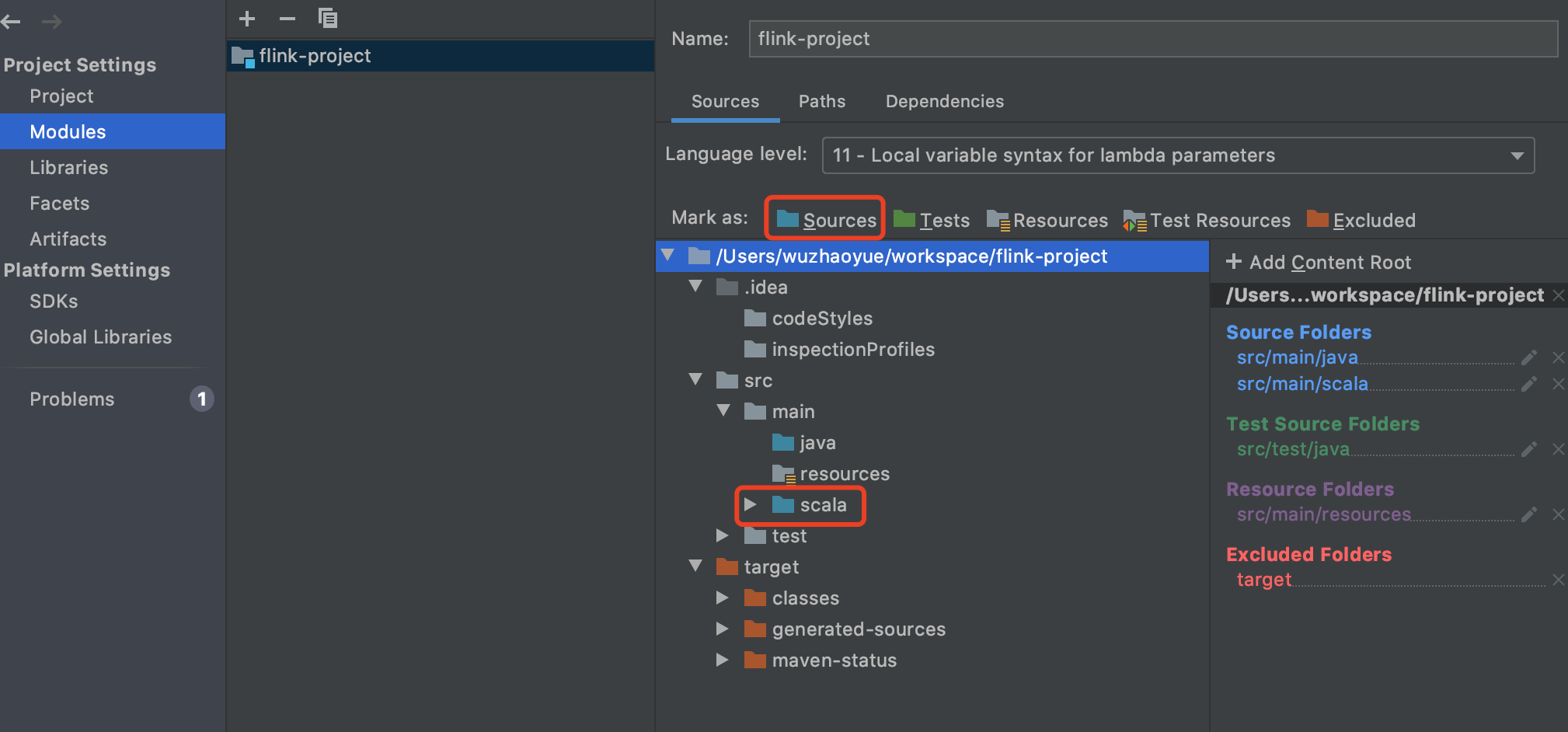
1、添加scala源文件,新建一个scala的文件夹,并把它设置成源文件。设置方法 File -> Project Structure -> Modules
2、添加scala框架支持,右键项目 -> Add Framework Support -> scala(需要提前配置上scala的sdk)
二、wordcount批处理
新建一个txt文件,让程序读取文件里内容进行单词的统计
package wordcount import org.apache.flink.api.scala._ /** * @description 批处理 */ object WordCountBatch { def main(args: Array[String]): Unit = { // 创建执行环境 val env = ExecutionEnvironment.getExecutionEnvironment // 从文件中读取数据 val inputPath = "src/main/resources/wordcount.txt" val inputDS: DataSet[String] = env.readTextFile(inputPath) // 分词之后, 对单词进行 groupby 分组, 然后用 sum 进行聚合 val wordCountDS: AggregateDataSet[(String, Int)] = inputDS .flatMap(_.split(" ")) .map((_, 1)) .groupBy(0) .sum(1) // 打印输出 wordCountDS.print() } }
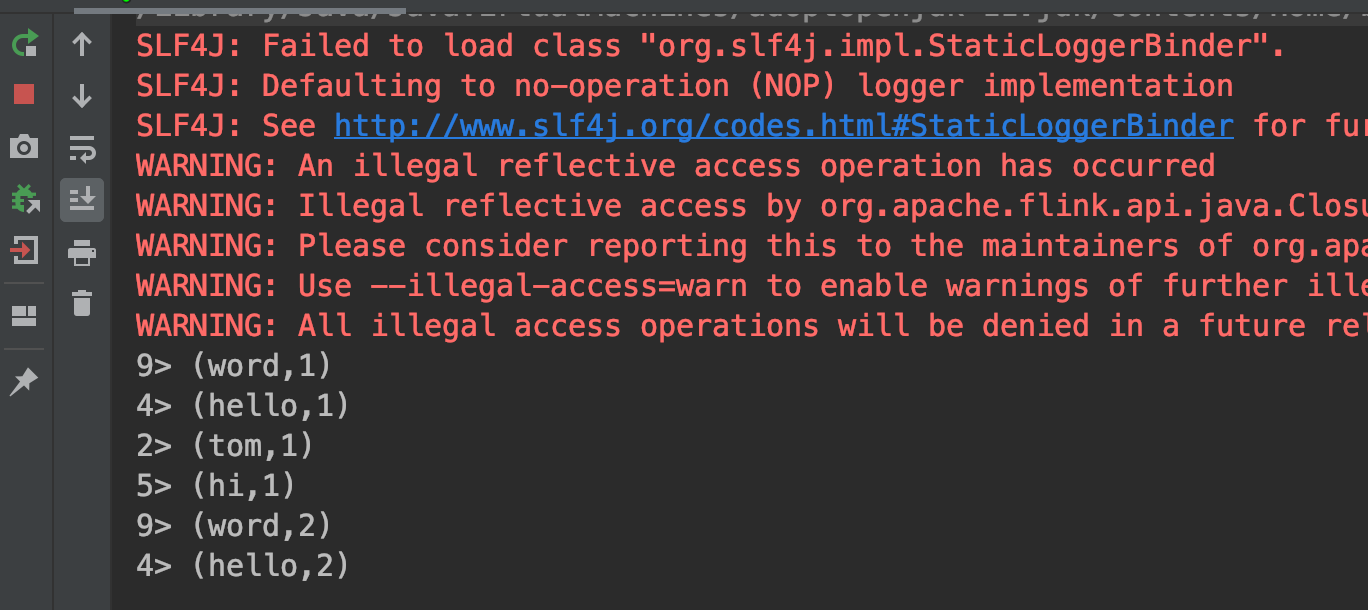
打印结果如下
三、wordcount流处理
新建一个服务端口,让程序监听端口,收到一条处理一条,结果累加
开启临时服务命令:nc -lk 8088
手动输入单词回车就会发送出去

然后程序进行端口的监听
package wordcount import org.apache.flink.streaming.api.scala._ /** * @description 流处理 */ object WordCountStream { def main(args: Array[String]): Unit = { val host: String = "localhost" val port: Int = 8088 // 创建流处理环境 val env = StreamExecutionEnvironment.getExecutionEnvironment // 接收 socket 文本流 val textDstream: DataStream[String] = env.socketTextStream(host, port) // flatMap 和 Map 需要引用的隐式转换 val dataStream: DataStream[(String, Int)] = textDstream .flatMap(_.split(" ")) .filter(_.nonEmpty) .map((_, 1)) .keyBy(0) .sum(1) dataStream.print() env.execute("wordcount job") } }
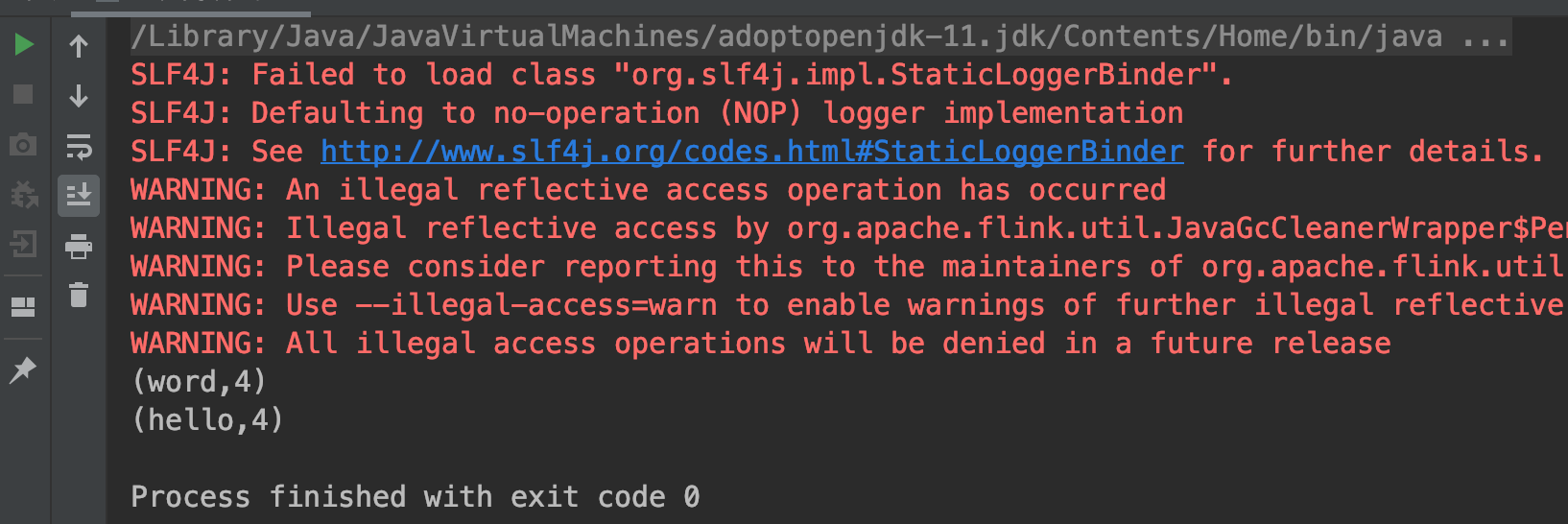
打印结果如下,可以看到结果是累加的