本文主要介绍Azkaban的使用,文中文中使用到的软件版本:Azkaban 3.90.0、MySQL 5.7、Centos 7。
1、关系
一个project包含多个flow,一个flow包含多个job,job之间可以有依赖关系。
2、创建flow
2.1、flow 1.0
由于flow 1.0即将被flow 2.0替代,这里简单介绍下其使用方法。
2.1.1、创建job文件
直接创建三个job文件:JobA.job、JobB.job、JobC.job
JobA.job:
type=command command=echo 'this is JobA'
JobB.job:
type=command command=echo 'this is JobB'
JobC.job:
type=command command=echo 'this is JobC' dependencies=JobA,JobB
2.1.2、打包上传
把JobA.job、JobB.job、JobC.job打包成一个zip文件,并上传到一个已创建的project中;上传后会自动生成flow的名称(最后一个没有被依赖的job名称)

2.2、flow 2.0
2.2.1、创建project文件
创建flow20.project文件:
azkaban-flow-version: 2.0
2.2.2、创建flow文件
创建basic.flow文件:
nodes: - name: jobC type: command # jobC depends on jobA and jobB config: command: echo "This is JobC." dependsOn: - jobA - jobB - name: jobA type: command config: command: echo "This is JobA." - name: jobB type: command config: command: echo "This is JobB."
一个flow文件对应一个flow,如果有多个flow,可以创建多个flow文件。
2.2.3、打包上传
把flow20.project、basic.flow文件打包成一个zip文件,并上传到一个已创建的project中。
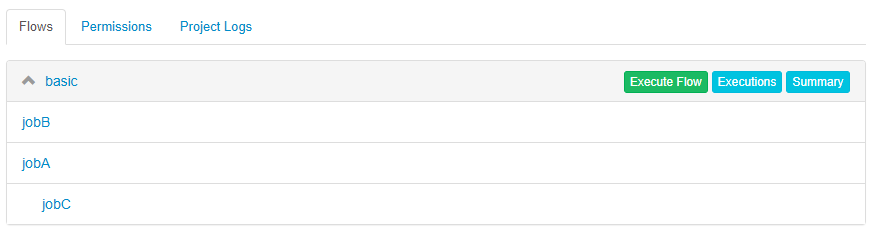
3、执行flow或job
点击flow的"Execue Flow"来执行flow或点击job的”Run job“来运行job

在弹出的页面中点击”Executor“或”Schedule“来立即执行或定时执行:
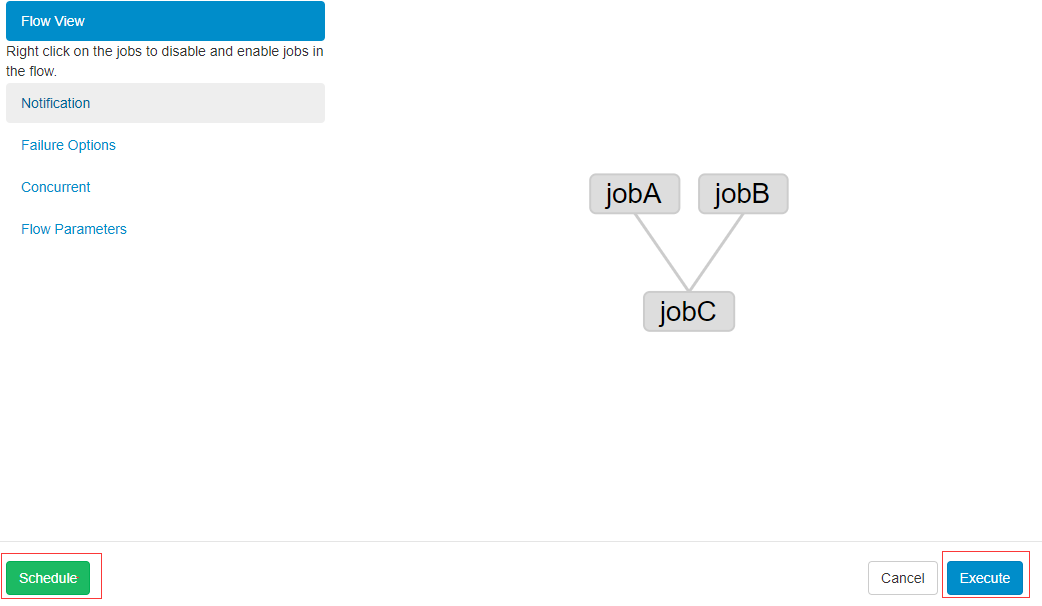
3.1、立即执行flow或job
点击”Execute“按钮来立即执行flow或立即运行job。
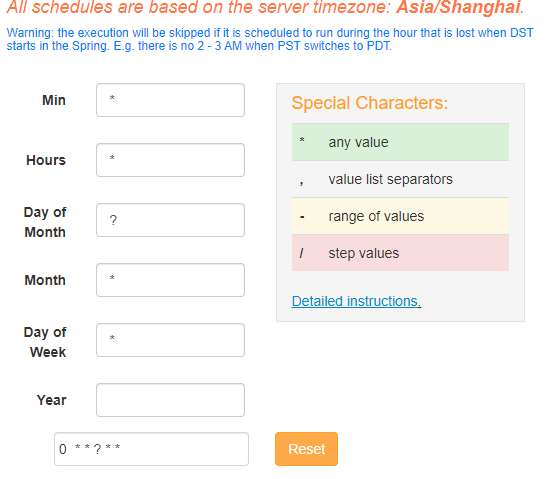
3.2、定时执行flow
点击”Execute“按钮来定时执行flow或立即运行job,在弹出的页面可以定义运行周期:
3.3、查看运行情况

在Scheduling中可以查看定义的定时任务,在Executing中可以查看正在或最近执行的flow或job,在History中可以查看历史的flow或job。
4、执行sql
azkaban默认不能直接执行sql,需要安装插件;插件地址为https://gitee.com/centy/azkaban-plugin-jobtype-sql/tree/master,上面有详细的使用说明;这里简单介绍其使用方法。
4.1、安装azkaban-plugin-jobtype-sql插件
下载安装包,下载地址为:https://gitee.com/centy/azkaban-plugin-jobtype-sql/releases;然后安装包拷贝到${ExecutorServerHome}/plugins/jobtypes/目录下,直接解压到当前目录。
重启Executor Server及Web Server,完成安装。
4.2、使用方法
4.2.1、创建project、flow文件及sql执行脚本
创建flow20.project、quickstart_example.flow文件,创建scripts目录,在该目录下创建create_and_insert.sql、update_value.sql执行脚本。
flow20.project文件:
azkaban-flow-version: 2.0
quickstart_example.flow文件:
config: sql_job.database.type: mysql sql_job.database.driver: com.mysql.jdbc.Driver sql_job.database.host: 10.49.196.10 sql_job.database.port: 3306 sql_job.database.database: test sql_job.database.schema: sql_job.database.username: admin sql_job.database.password: Root_123! nodes: - name: create_and_insert_job type: sql_job config: sql_job.scripts: scripts/create_and_insert.sql - name: update_value_job type: sql_job dependsOn: - create_and_insert_job config: sql_job.scripts: scripts/update_value.sql
scripts/create_and_insert.sql文件:
create table if not exists table_a( id int(10) not null, name varchar(16) not null, value double(20,3) not null ); insert into table_a values (1,"test-1",1), (2,"test-2",2), (3,"test-3",3), (4,"test-4",4), (5,"test-5",5), (6,"test-6",6), (7,"test-7",7), (8,"test-8",8) ; select count(*) from table_a;
scripts/update_value.sql文件:
update table_a set value = value*2; select count(*) from table_a;
然后把这些文件打成一个zip包:

4.2.2、上传zip包

4.2.3、执行flow
执行结果如下:
