使用Scrapy爬取图片入库,并保存在本地
上
篇博客已经简单的介绍了爬取数据流程,现在让我们继续学习scrapy
目标:
爬取爱卡汽车标题,价格以及图片存入数据库,并存图到本地

好了不多说,让我们实现下效果
我们仍用scrapy框架来编写我们的项目:
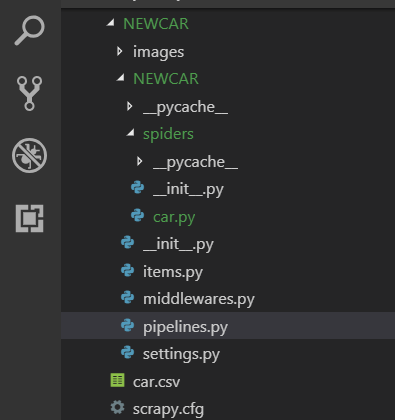
1.首先用命令创建一个爬虫项目(结合上篇博客),并到你的项目里如图所示
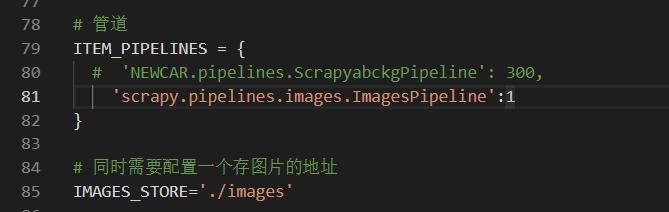
2.先到你的settings.py中配置 ,这里需要注意要 爬图(配置一个爬图管道 ImagesPipeline 为系统中下载图片的管道),
同时还有存图地址(在项目中创建一个为images的文件夹),
存图有多种方式,本人只是列举其中一种,大家可采取不同的方法
3.然后打开你的爬虫文件(即:car.py)开始编写你要爬取的数据,这里需要注意,要将start_urls[] 改为我们要爬取的Url 地址,然后根据xpath爬取图片
(这里代码得自己写,不要复制)

4.爬取的字段要跟 items.py里的一致

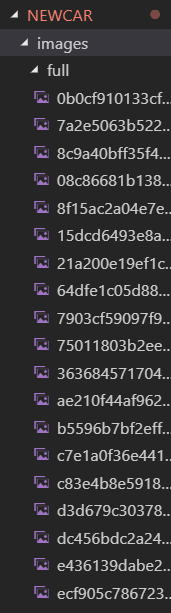
5.在命令行输入启动爬虫命令 scrapy crawl car 运行就能看到爬到图片存放在本地如下
6.最后入库,看你要入那个库,这里可入mysql和mongdb
mysql: 需提前创好库以及表,表中字段
import pymysql # class NewcarPipeline(object): # 连接mysql改为你的用户密码以及自己的库 # def __init__(self): # self.conn = pymysql.connect(host='127.0.0.1',user='root', password='123456', db='zou') # 建立cursor对象 # self.cursor = self.conn.cursor() # # 传值 # def process_item(self, item, spider): # name = item['name'] # content = item['content'] # price = item['price'] # image = item['image_urls'] # # insert into 你的表名,括号里面是你的字段要一一对应 # sql = "insert into zou(name,content,price) values(%s,%s,%s)" # self.cursor.execute(sql, (name,content,price)) # self.conn.commit() # return item #关闭爬虫 # def close_spider(self, spider): # self.conn.close()
mongdb: 不用提前建好库,表
from pymongo import MongoClient # class NewcarPipeline(object): # def open_spider(self, spider): # # 连端口 ip # self.con = MongoClient(host='127.0.0.1', port=27017) # # 库 # db = self.con['p1'] # # 授权 # self.con = db.authenticate(name='wumeng', password='123456', source='admin') # # 集合 # self.coll = db[spider.name] # def process_item(self, item, spider): # # 添加数据 # self.coll.insert_one(dict(item)) # return item # def close_spider(self): # # 关闭 # self.con.close()
7.运行 启动爬虫命令 scrapy crawl car 就可在库中看到数据.
至此爬虫项目做完了,这只是一个简单的爬虫,仅供参考,如遇其他方面的问题,可参考本人博客!尽情期待!