1.前言背景
没怎么用过df.where 都是直接使用loc、apply等方法去解决。


可能是某些功能还没有超出loc和apply的适用范围。
2.进入df.where和df.mask
DataFrame.where(self, cond, other=nan, inplace=False, axis=None, level=None, errors='raise', try_cast=False)
note:Replace values in DataFrame with other where the cond is False.
我们还是要看一下官网对里面每一个参数的解释:
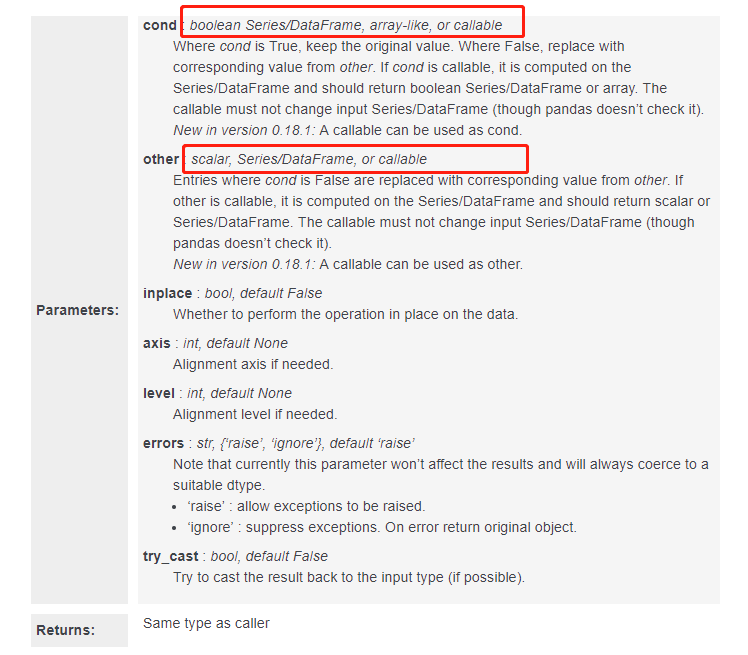
红色是特别注意的,往往无论是博客还是案例一般给不会穷举所有可能,只有把api的每一种可能理解了,才能无招胜有招。
大体意思:就是对一个DataFrame进行条件判断当他的条件不符合就选择other参数里面的数值。
其实它拥有一个相反的函数where<==>mask:where条件不符合进行替换,mask是条件符合进行替换。
DataFrame.mask(self, cond, other=nan, inplace=False, axis=None, level=None, errors='raise', try_cast=False)
note:Replace values in DataFrame with other where the cond is True.
我们还是要看一下官网对里面每一个参数的解释:

也可以看到两者参数并无差异。
3.与np.where的异同?

np.where(condition, [x, y]),这里三个参数,其中必写参数是condition(判断条件),后边的x和y是可选参数.那么这三个参数都有怎样的要求呢?
condition:array_like,bool ,当为True时,产生x,否则产生y
简单说,对第一个参数的要求是这样的,首先是数据类型的要求,类似于数组或者布尔值,当判断条件为真时返回x中的值,否则返回y中的值
x,y:array_like,可选,要从中选择的值。 x,y和condition需要可广播到某种形状
x和y是可选参数,并且对这两个参数的数据类型要求只有类似数组这一条,当条件判断为true或者false时从这两个类似数组的容器中取数.
4.实际案例
4.1mask和where 的区别,np.where(cond,df1,df2)
s = pd.Series(range(5))

s.mask(s > 0)

s.where(s > 0)

ss = pd.Series(range(10,20,2)) import numpy as np np.where(s>2,s,ss)

4.2探究cond : boolean Series/DataFrame, array-like, or callable和other : scalar, Series/DataFrame, or callable
下面我在cond使用callable类型,在other参数中使用callable参数
df = pd.DataFrame(np.arange(10).reshape(-1, 2), columns=['A', 'B']) df
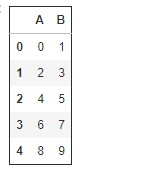
def cond1(x): return x%3==0 def mult3(x): return x*3 df.where(cond1, mult3)