方法一:使用pyhive库
如上图所示我们需要四个外部包
中间遇到很多报错。我都一一解决了
1.Connection Issue: thrift.transport.TTransport.TTransportException: TSocket read 0 bytes
2.安装sasl 遇到Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools"
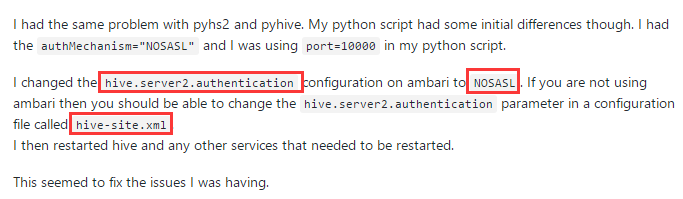
解决了 点击
3.遇到
thrift.transport.TTransport.TTransportException: Could not start SASL: b'Error in sasl_client_start (-4) SASL(-4): no mechanism available: Unable to find a callback: 2'
处理
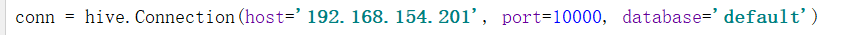
加上 auth="NOSAL"这个参数
4.我发现上面这个包有的安装不了 我强行用pycharm alt+enter强行按安装的
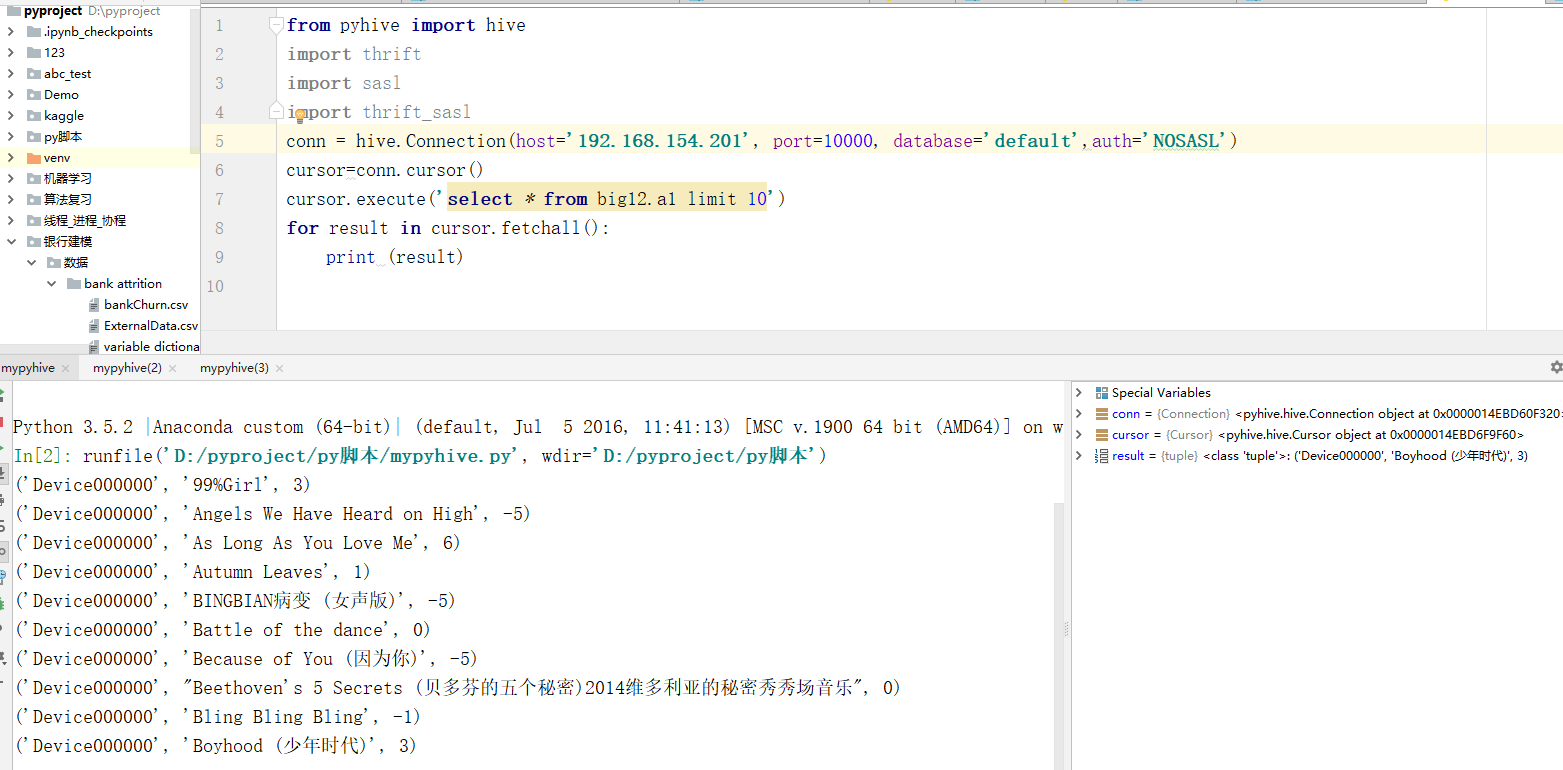
最后附上测试代码
from pyhive import hive import thrift import sasl import thrift_sasl conn = hive.Connection(host='192.168.154.201', port=10000, database='default',auth='NOSASL') cursor=conn.cursor() cursor.execute('select * from a1 limit 10') for result in cursor.fetchall(): print (result)
方法二:使用impyla库
pip install thrift-sasl==0.2.1 pip install sasl pip install impyla
测试代码如下:
from impala.dbapi import connect conn = connect(host='192.168.154.201', port=10000, database='default') cursor = conn.cursor() cursor.execute('select * from a1 limit 10') for result in cursor.fetchall(): print(result)
方法三:使用ibis库
# # 1.查询hdfs数据 from ibis import hdfs_connect hdfs = hdfs_connect(host='xxx.xxx.xxx.xxx', port=50070) hdfs.ls('/') hdfs.ls('/apps/hive/warehouse/ai.db/tmp_ys_sku_season_tag') hdfs.get('/apps/hive/warehouse/ai.db/tmp_ys_sku_season_tag/000000_0', 'parquet_dir')
# 2.查询数据到python dataframe from ibis.impala.api import connect ImpalaClient = connect('192.168.154.201',10000,database='default') lists=ImpalaClient.list_databases() print(lists) isExist=ImpalaClient.exists_table('a1') # # 执行SQL # if(isExist): # sql='set mapreduce.job.queuename=A' # ImpalaClient.raw_sql(sql) # 将SQL结果导出到python dataframe requete = ImpalaClient.sql('select * from a1 limit 10') df = requete.execute(limit=None) print(type(df)) print(df)
结果:

官网API:https://docs.ibis-project.org/api.html#impala-client
变成df确实能用pandas和numpy两个包能做很多事情