这里的几道题都是自己在学习Python中常遇到的几个问题,这里整理出来,防止自己忘记。
1,python中@property的用法
(学习于廖雪峰:https://www.liaoxuefeng.com/wiki/1016959663602400/1017502538658208)
在Python中,可以通过@property (装饰器)将一个方法转换为属性,从而实现用于计算的属性。将方法转换为属性后,可以直接通过方法名来访问方法,而不需要一对小括号“()”,这样可以让代码更加简洁。
在绑定属性时,如果我们直接把属性暴露出去,虽然写起来很简单,但是,没办法检查参数,导致可以随便赋值给对象,比如:
s = Student() s.score = 9999
这显然不合逻辑,为了限制score的范围,可以通过一个 set_score() 方法来设置成绩,再通过一个 get_score() 来获取成绩,这样,在 set_score() 方法里,就可以检查参数:
class Student(object):
def get_score(self):
return self._score
def set_score(self, value):
if not isinstance(value, int):
raise ValueError("score must be an integer")
if value < 0 or value > 100:
raise ValueError("score must between 0~100")
self._score = value
现在,对任意的Student 实例进行操作,就不能随心所欲的设置score了。
s = Student()
s.set_score(60)
print(s.get_score())
s.set_score(2123)
print(s.get_score())
'''
60
Traceback (most recent call last):
... ...
raise ValueError("score must between 0~100")
ValueError: score must between 0~100'''
但是,上面的调用方法又略显复杂,没有直接用属性这么直接简单 。
有没有既能检查参数,又可以用类似属性这样简单的方法来访问类的变量呢?对于追求完美的Python程序员来说,这是必须做到的。
还记得装饰器(decorator)可以给函数动态加上功能吗?对于类的方法,装饰器一样起作用。Python内置的@property装饰器就是负责把一个方法编程属性调用的。
class Student(object):
@property
def score(self):
return self._score
@score.setter
def score(self, value):
if not isinstance(value, int):
raise ValueError("score must be an integer")
if value < 0 or value > 100:
raise ValueError("score must between 0~100")
self._score = value
@property 的实现比较复杂,我们先考察如何使用。把一个 getter方法编程属性,只需要加上 @property 就可以了,此时,@property本身又创建了另一个装饰器 @score.setter ,负责把一个 setter 方法变成属性赋值,于是,我们就拥有一个可控的属性操作:
s = Student()
s.score = 60
print(s.score)
s.score = 1232
print(s.score)
'''
60
Traceback (most recent call last):
... ...
raise ValueError("score must between 0~100")
ValueError: score must between 0~100'''
注意到这个神奇的 @property ,我们在对实例属性操作的时,就知道该属性很可能不是直接暴露的,而是通过 getter 和 setter 方法来实现的。
还可以定义只读属性,只定义 getter 方法,不定义 setter 方法就是一个只读属性:
class Student(object):
@property
def birth(self):
return self._birth
@birth.setter
def birth(self, value):
self._birth = value
@property
def age(self):
return 2015 - self._birth
上面的 birth 是可读写属性,而 age 就是一个只读属性,因为 age 可以根据 birth 和当前时间计算出来的。
所以 @property 广泛应用在类的定义中,可以让调用者写出简短的代码,同时保证对参数进行必要的检查,这样,程序运行时就减少了出错的可能性。
@property为属性添加安全保护机制
在Python中,默认情况下,创建的类属性或者实例是可以在类外进行修改的,如果想要限制其不能再类体外修改,可以将其设置为私有的,但设置为私有后,在类体外也不能获取他的值,如果想要创建一个可以读但不能修改的属性,那么也可以用@property 实现只读属性。
注意:私有属性__name 为单下划线,当然也可以定义为 name,但是为什么定义_name?
以一个下划线开头的实例变量名,比如 _age,这样的实例变量外部是可以访问的,但是,按照约定俗成的规定,当看到这样的变量时,意思是:虽然可以被访问,但是,请视为私有变量,不要随意访问。
2,Python中类继承object和不继承object的区别
我们写代码,常发现,定义class的时候,有些代码继承了object,有些代码没有继承object,那么有object和没有object的区别是什么呢?
下面我们查看,在Python2.x 中和Python3.x中,通过分别继承object和不继承object定义不同的类,之后通过dir() 和 type 分别查看该类的所有方法和类型:
Python2.X
>>> class test(object): ... pass ... >>> dir(test) ['__class__', '__delattr__', '__dict__', '__doc__', '__format__', '__getattribute__', '__hash__', '_ _init__', '__module__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__size of__', '__str__', '__subclasshook__', '__weakref__'] >>> type(test) <type 'type'> >>> class test2(): ... pass ... >>> dir(test2) ['__doc__', '__module__'] >>> type(test2) <type 'classobj'>
Python3.X
>>> class test(object): pass >>> class test2(): pass >>> type(test) <class 'type'> >>> type(test2) <class 'type'> >>> dir(test) ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__'] >>> dir(test2) ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__']
所以:在Python3.X中,继承和不继承object对象,我们创建的类,均拥有好多可操作对象。所以不用管。而python2.X中,却不一样。那这是为什么呢?
这就需要从新式类和经典类说起了。
#新式类是指继承object的类
class A(obect):
pass
#经典类是指没有继承object的类
class A:
pass
Python中推荐大家使用新式类(新式类已经兼容经典类,修复了经典类中多继承出现的bug)
那经典类中多继承bug是什么呢?
(参考文献:https://www.cnblogs.com/attitudeY/p/6789370.html)
下面我们看下图:

BC为A的子类,D为BC的子类,A中有save方法,C对其进行了重写。
在经典类中,调用D的save 方法,搜索按深度优先,路径 B-A-C,执行的为A中save ,显然不合理
在新式类中,调用D的save 方法,搜索按广度优先,路径B-C-A,执行的为C中save
代码:
#经典类
class A:
def __init__(self):
print 'this is A'
def save(self):
print 'come from A'
class B(A):
def __init__(self):
print 'this is B'
class C(A):
def __init__(self):
print 'this is C'
def save(self):
print 'come from C'
class D(B,C):
def __init__(self):
print 'this is D'
d1=D()
d1.save() #结果为'come from A
#新式类
class A(object):
def __init__(self):
print 'this is A'
def save(self):
print 'come from A'
class B(A):
def __init__(self):
print 'this is B'
class C(A):
def __init__(self):
print 'this is C'
def save(self):
print 'come from C'
class D(B,C):
def __init__(self):
print 'this is D'
d1=D()
d1.save() #结果为'come from C'
所以,Python3.X 中不支持经典类了,虽然还是可以不带object,但是均统一使用新式类,所以在python3.X 中不需要考虑object的继承与否。但是在 Python 2.7 中这种差异仍然存在,因此还是推荐使用新式类,要继承 object 类。
3,深度优先遍历和广度优先遍历
图的遍历是指从图中某一顶点除法访遍图中其余顶点,且使每一个顶点仅被访问一次,这一过程就叫做图的遍历。
深度优先遍历常用的数据结构为栈,广度优先遍历常用的数据结构为队列。
3.1 深度优先遍历Depth First Search(DFS)
深度优先遍历的思想是从上至下,对每一个分支一直往下一层遍历直到这个分支结束,然后返回上一层,对上一层的右子树这个分支继续深搜,直到一整棵树完全遍历,因此深搜的步骤符合栈后进先出的特点。
深度优先搜索算法:不全部保留节点,占用空间少;有回溯操作(即有入栈,出栈操作),运行速度慢。
其实二叉树的前序,中序,后序遍历,本质上也可以认为是深度优先遍历。
3.2 广度优先遍历Breadth First Search(BFS)
广度优先遍历的思想是从左到右,对树的每一层所有节点依次遍历,当一层的节点遍历完全后,对下一层开始遍历,而下一层节点又恰好是上一层的子结点。因此广搜的步骤符合队列先进先出的思想。
广度优先搜索算法:保留全部节点,占用空间大;无回溯操作(即无入栈,出栈操作),运行速度快。
其实二叉树的层次遍历,本质上也可以认为是广度优先遍历。
4,Python 逻辑运算符 异或 xor
首先,让我们用真值表来看一下异或的运算逻辑:
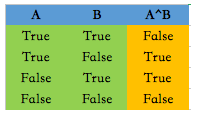
也就是说:
AB有一个为真,但不同时为真的运算称作异或
看起来,简单明了,但是如果我们将布尔值之间的异或换成数字之间的异或会发生什么呢?
让我们来试一下
0 ^ 0 0 ^ 1 1 ^ 0 1 ^ 1 >>>0 1 1 0
结果告诉我们,数字相同异或值为0 数字不相同异或值为1
让我们再试试0, 1 除外的数字
5 ^ 3 >>>6
为什么答案是6呢?(其中这里经历了几次计算,下面学习一下)
异或是基于二进制基础上按位异或的结果计算 5^3 的过程,其实是将5和3分别转成二进制,然后进行异或计算。
5 = 0101(b) 3 = 0011(b)
按照位 异或:

0^0 ->0 1^0 ->1 0^1 ->1 1^1 ->0
排起来就是 0110(b) 转换为十进制就是 6

注意上面:如果a,b两个值不相同,则异或结果为1,如果两个值相同,则异或结果为0
5,Python的位运算
位运算:就是对该数据的二进制形式进行运算操作。
位运算分为六种情况,如下:
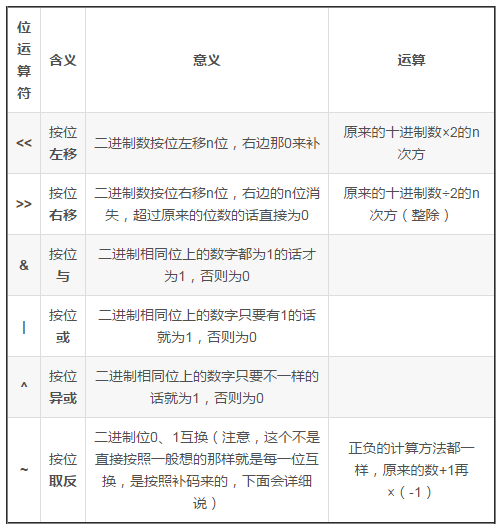
我们可以看一下1~10的十进制转二进制结果表示:
 注意:这个 bin() 函数对于负数的二进制解析要多加注意。而且 Python里面的内置函数 bin() 是解析为二进制,和实际的在计算机里面的二进制表示有点不一样,bin() 函数的输出通常不考虑最高位的运算符,而是拿 - 来代替!
注意:这个 bin() 函数对于负数的二进制解析要多加注意。而且 Python里面的内置函数 bin() 是解析为二进制,和实际的在计算机里面的二进制表示有点不一样,bin() 函数的输出通常不考虑最高位的运算符,而是拿 - 来代替!

左移运算
左移运算符:运算数的各二进制全部左移若干位,由“<<” 右边的数指定移动的位数,高位丢弃,低位补0。
规律简单来说就是:
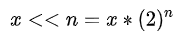
举个例子:
# 运算数的二进制左移若干位,高位丢弃,低维补0 a = 2 其二进制为:0b10 a << 2 : 将a移动两位: ob1000 a << n = a*(2**n) =8 8的二进制为: 0b1000 a << 4 : 将a移动两位: ob100000 a << n = a*(2**n) =32 32的二进制为: 0b10000 a << 5 : 将a移动两位: ob1000000 a << n = a*(2**n) =64 64的二进制为: 0b100000
右移运算
右移运算符:把“>>” 左边的运算数的各二进制全部右移若干位,“>>” 右边的数指定移动的位数。正数补0,负数补1。
规律简单来说就是:
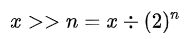
举个例子:
# 把“>>” 左边的运算数的各二进位全部右移若干位,“>>” 右边的数指定移动的位数。 # 正数补0,负数补1 a = 64 其二进制为:0b1000000 a >> 2 : 将a移动两位: ob10000 a >> n = a%(2**n) =16 16的二进制为: 0b10000 a >> 4 : 将a移动两位: ob100 a >> n = a%(2**n) =4 4的二进制为: 0b100 a >> 5 : 将a移动两位: ob10 a >> n = a%(2**n) =2 2的二进制为: 0b10
注意:左移右移不一样,右移复杂一些。
按位与
按位与运算符:参与运算的两个值,如果两个相应位都是1,则该位的结果为1,否则为0。
举个例子:
# 参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0。
a = 2 其二进制为:0b10
b = 4 其二进制为:0b100
a & b 010 & 100 000
print(int('0', 2)) 0 # 0的二进制为 ob0
按位或
按位或运算符:只要对应的二个二进位有一个为1时,结果就为1,否则为0。
举个例子:
# 按或运算的两个值,只要对应的两个二进位有一个为1时,则该位的结果为1,否则为0。
a = 2 其二进制为:0b10
b = 4 其二进制为:0b100
a | b 010 | 100 110
print(int('110', 2)) 6 # 6的二进制为 ob110
按位异或
按位异或运算符:当两对应的二进位相异时,结果为1,否则为0。
举个例子:
# 按位异或运算的两个值,当对应的两个二进位相异时,则该位的结果为1,否则为0。
a = 2 其二进制为:0b10
b = 4 其二进制为:0b100
a ^ b 010 ^ 100 110
print(int('110', 2)) 6 # 0的二进制为 ob110
按位取反
按位取反运算符:对数据的每个二进制值加1再取反, ~x 类似于 -x-1
举个例子:
# 按位取反运算符:对数据的每个二进制位取反,即把 1 变为 0,把 0 变为 1。 a = 2 其二进制为:0b10 (a+1)*(-1) = -3 其二进制为:-0b11 res = ~a
二进制转十进制
二进制转十进制方法很简单:即每一位都乘以2的(位数-1)次方。
# 二进制转为十进制,每一位乘以2的(位数-1)次方
# 如下:
比如4,其二进制为 ob100, 那么
100 = 1*2**(3-1) + 0*2**(2-1) + 0*2**(1-1) = 4
即将各个位拆开,然后每个位乘以 2 的(位数-1)次方。
十进制转二进制
十进制转二进制时,采用“除2取余,逆序排列”法。
- 用 2 整除十进制数,得到商和余数
- 再用 2 整数商,得到新的商和余数
- 重复第一步和第二步,直到商为0
- 将先得到的余数作为二进制数的高位,后得到的余数作为二进制数的低位,依次排序
如下:
# 十进制转二进制 采用 除2取余,逆序排列 # 比如 101 的二进制 '0b1100101' 101 % 2 = 50 余 1 50 % 2 = 25 余 0 25 % 2 = 12 余 1 12 % 2 = 6 余 0 6 % 2 = 3 余 0 3 % 2 = 1 余 1 1 % 2 = 0 余 1 # 所以 逆序排列即二进制中的从高位到低位排序:得到7位数的二进制数为 ob1100101
6,collections.defaltdict()的用法
我们先看看其源码解释:
class defaultdict(dict):
"""
defaultdict(default_factory[, ...]) --> dict with default factory
The default factory is called without arguments to produce
a new value when a key is not present, in __getitem__ only.
A defaultdict compares equal to a dict with the same items.
All remaining arguments are treated the same as if they were
passed to the dict constructor, including keyword arguments.
"""
就是说collections类中的 defaultdict() 方法为字典提供默认值。和字典的功能是一样的。函数返回与字典类似的对象。只不过defaultdict() 是Python内建字典(dict)的一个子类,它重写了方法_missing_(key) ,增加了一个可写的实例变量 default_factory,实例变量 default_factory 被 missing() 方法使用,如果该变量存在,则用以初始化构造器,如果没有,则为None。其他的功能和 dict一样。
而它比字典好的一点就是,使用dict的时候,如果引入的Key不存在,就会抛出 KeyError。如果希望Key不存在时,返回一个默认值,就可以用 defaultdict。
from collections import defaultdict res = defaultdict(lambda: 1) res['key1'] = 'value1' # key1存在 key2不存在 print(res['key1'], res['key2']) # value1 1 # 从结果来看,key2不存在,则返回默认值 # 注意默认值是在调用函数返回的,而函数在创建defaultdict对象时就已经传入了。 # 除了在Key不存在返回默认值,defaultdict的其他行为与dict是完全一致的
7,Python中 pyc文件学习
参考地址:https://blog.csdn.net/newchitu/article/details/82840767
这个需要从头说起。
7.1 Python为什么是一门解释型语言?
初学Python时,听到的关于 Python的第一句话就是,Python是一门解释型语言,直到发现了 *.pyc 文件的存在。如果是解释型语言,那么生成的 *.pyc 文件是什么呢?
c 应该是 compiled 的缩写,那么Python是解释型语言如何解释呢?下面先来看看编译型语言与解释型语言的区别。
7.2 编译型语言与解释型语言
计算机是不能识别高级语言的,所以当我们运行一个高级语言程序的时候就需要一个“翻译机”来从事把高级语言转变为计算机能读懂的机器语言的过程。这个过程分为两类,第一种是编译,第二种是解释。
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言。
解释型语言就没有这个编译的过程,而程序执行的时候,通过解释器对程序逐行做出解释,然后直接运行,最典型的例子就是Ruby。
所以说,编译型语言在程序运行之前就已经对程序做出了“翻译”,所以在运行时就少掉了“翻译”的过程,所以效率比较高。但是我们也不能一概而论,一些解释型语言也可以通过解释器的优化来对程序做出翻译时对整个程序做出优化,从而在效率上接近编译型语言。
此外,随着Java等基于虚拟机的语言的兴起,我们又不能把语言纯粹的分为解释型和编译型两种,用Java来说,java就是首先通过编译器编译成字节码文件,然后在运行时通过解释器给解释成及其文件,所以说java是一种先编译后解释的语言。
7.3 Python是什么呢?
其实Python和Java/ C# 一样,也是一门基于虚拟机的语言。
当我们在命令行中输入 python test.py 的时候,其实是激活了 Python的“解释器”,告诉“解释器”: 要开始工作了。
可是在“解释”之前,其实执行的第一项工作和java一样,是编译。
所以Python是一门先编译后解释的语言。
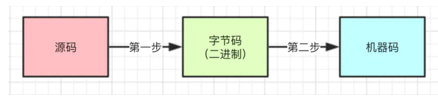
Python在解释源码程序时分为两步:
如下图所示:第一步:将源码编译为字节码;第二步:将字节码解释为机器码。
当我们的程序没有修改过,那么下次运行程序的时候,就可以跳过从源码到字节码的过程,直接加载pyc文件,这样可以加快启动速度。
7.4 简述Python的运行过程
在学习Python的运行过程之前,先说两个概念,PyCodeObject和pyc文件。
其实PyCodeObject 是Python编译器真正编译成的结果。
当Python程序运行时,编译的结果则是保存在位于内存中的 PyCodeObject中,当Python程序运行结束时,Python解释器则将 PyCodeObject写回pyc文件中。
当Python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样定位PyCodeObject和pyc文件,我们说 Pyc文件其实是PyCodeObject的一种持久化保存方式。
7.5 Python中单个pyc文件的生成
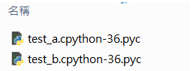
pyc文件是当我们 import 别的 py文件时,那个 py文件会被存一份 pyc 加速下次装载,而主文件因为只需要装载一次就没有存 pyc。

比如上面的例子,从上图我们可以看出 test_b.py 是被引用的文件,所以它会在__pycache_ 下生成 test_b.py 对应的 pyc 文件,若下次执行脚本时,若解释器发现你的 *.py 脚本没有变更,便会跳出编译这一步,直接运行保存在 __pycache__ 目录下的 *.pyc文件。
7.6 Python中pyc文件的批量生成
针对一个目录下所有的 py文件进行编译,Python提供一个模板叫 compileall,代码如下:
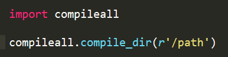
这样就可以批量生成所有文件的 pyc。
命令行为:
python -m compileall <dir>
7.7 Python中pyc文件的注意点
使用 pyc文件可以跨平台部署,这样就不会暴露源码。
- 1,import 过的文件才会自动生成 pyc文件
- 2,pyc文件不可以直接看到源码,但是可以被反编译
- 3,pyc的内容,是跟-Python版本相关的,不同版本编译后的pyc文件是不同的,即3.6编译的文件在 3.5中无法执行。
7.8 Python中pyc文件的反编译
使用 uncompyle6, 可以将 Python字节码转换回等效的 Python源代码,它接受python1.3 到 3.8 版本的字节码。
安装代码:
pip install uncompyle6
使用示例:
# 反编译 test_a.pyc 文件,输出为 test_a.py 源码文件 uncompyle6 test_a.py test_a.cpython-36.pyc
如下: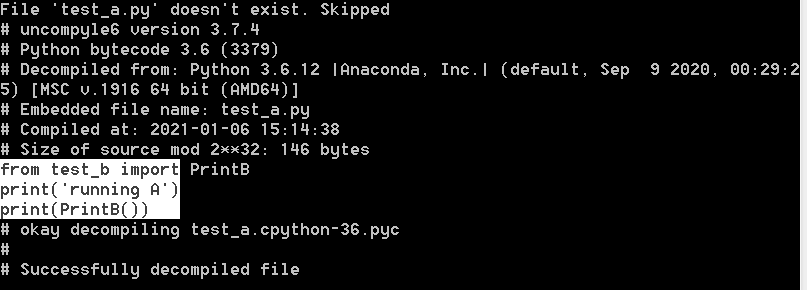
源代码如下:

感觉反编译对于简单的文件还是很OK的。我将复杂代码进行反编译,发现也可以出现,但是注释等一些代码就不会出现。
8,super() 函数
参考地址:https://www.runoob.com/python/python-func-super.html
8.1 super()函数描述
super() 函数是用于调用父类(超类)的一个方法。根据官方文档,super函数返回一个委托类 type 的父类或者兄弟类方法调用的代理对象。super 函数用来调用已经在子类中重写过的父类方法。
python3是直接调用 super(),这其实是 super(type, obj)的简写方式。
super 是用来解决多重继承问题的,直接用类名调用父类方法在使用单继承的时候没问题,但是如果使用多继承,会涉及到查找顺序(MRO),重复调用(钻石继承)等种种问题。
8.2 单继承
在单继承中,super().__init__() 与 Parent.__init__() 是一样的。super()避免了基类的显式调用。
下面看一个实例来验证结果是否一致:
# -*- coding:utf-8 -*-
# 下面两种class 的方法一样,现在建议使用第二种,毕竟使用新式类比较方便
# class FooParent(object):
class FooParent:
def __init__(self):
print('this is parent')
def bar(self, message):
print('%s from parent'%message)
print('parent bar function')
class FooChild(FooParent):
def __init__(self):
# 方法一
# super(FooChild, self).__init__() # 在Python3中写成 super().__init()
# 方法二
FooParent.__init__(self)
print('this is child')
if __name__ == '__main__':
foochild = FooChild()
foochild.bar('message')
'''
方法1结果:
this is parent
this is child
message from parent
parent bar function
方法2结果:
this is parent
this is child
message from parent
parent bar function
'''
8.3 多继承
super 与父类没有实质性的关联。在单继承时,super获取的类刚好是父类,但多继承时,super获取的是继承顺序中的下一个类。
以下面继承方式为例:
Parent
/
/
child1 child2
/
/
grandchild
使用super,代码如下:
# -*- coding:utf-8 -*-
# 下面两种class 的方法一样,现在建议使用第二种,毕竟使用新式类比较方便
# class FooParent(object):
class FooParent:
def __init__(self):
print('this is parent')
def bar(self, message):
print('%s from parent'%message)
print('parent bar function')
class FooChild1(FooParent):
def __init__(self):
# 方法一
# super(FooChild1, self).__init__() # 在Python3中写成 super().__init()
# 方法二
FooParent().__init__()
print('this is child1111')
class FooChild2(FooParent):
def __init__(self):
# 方法一
# super(FooChild2, self).__init__() # 在Python3中写成 super().__init()
# 方法二
FooParent().__init__()
print('this is child2222')
class FooGrandchild(FooChild1, FooChild2):
def __init__(self):
# 方法一
#super(FooGrandchild, self).__init__() # 在Python3中写成 super().__init()
# 方法二
FooChild1().__init__()
FooChild2().__init__()
print('this is FooGrandchild')
if __name__ == '__main__':
FooChild1 = FooChild1()
FooChild1.bar('message')
'''
方法1结果:
this is parent
this is child2222
this is child1111
this is FooGrandchild
message from parent
parent bar function
方法2结果:
this is parent
this is parent
this is child1111
this is parent
this is parent
this is child1111
this is parent
this is parent
this is child2222
this is parent
this is parent
this is child2222
this is FooGrandchild
message from parent
parent bar function
为了方便查看,我们打印child1的结果如下:
this is parent
this is parent
this is child1111
message from parent
parent bar function
'''
可以看出如果不使用 super,会导致基类被多次调用,开销非常大。
最后一个例子:
# -*- coding:utf-8 -*-
# 下面两种class 的方法一样,现在建议使用第二种,毕竟使用新式类比较方便
# class FooParent(object):
class FooParent:
def __init__(self):
self.parent = "I'm the parent"
print('this is parent')
def bar(self, message):
print('%s from parent'%message)
class FooChild(FooParent):
def __init__(self):
# super(FooChild, self)首先找到FooChild的父类
# 就是类 FooParent,然后把类 FooChild的对象转换为类 FooParent 的对象
super(FooChild, self).__init__()
print('this is child')
def bar(self, message):
super(FooChild, self).bar(message)
print('Child bar function')
if __name__ == '__main__':
foochild = FooChild()
foochild.bar('durant is my favorite player')
'''
this is parent
this is child
durant is my favorite player from parent
Child bar function
'''
这里解释一下,我们直接继承父类的bar方法,但是我们不需要其方法内容,所以使用super() 来修改。最后执行,我们也看到了效果。
注意:如果我们在__init__()里面写入:
FooParent.bar.__init__(self)
意思就是说,需要重构父类的所有方法,假设我们没有重构,则继承父类,如果重构了这里需要与父类的名称一样。
9, Python3的 int 类型详解(为什么int不存在溢出问题?)
参考地址:https://www.cnblogs.com/ChangAn223/p/11495690.html
在Python内部对整数的处理分为普通整数和长整数,普通整数长度是机器位长,通常都是 32 位,超过这个范围的整数就自动当长整数处理,而长整数的范围几乎没有限制,所以long类型运算内部使用大数字算法实现,可以做到无长度限制。
在以前的 python2中,整型分为 int 和 Long,也就是整型和长整型,长整型不存在溢出问题,即可以存放任意大小的数值,理论上支持无线大数字。因此在Python3中,统一使用长整型,用 int 表示,在Python3中不存在 long,只有 int。
长整形 int 结构其实也很简单,在 longinterpr.h 中定义:
struct _longobject {
PyObject_VAR_HEAD
digit ob_digit[1];
};
ob_digit 是一个数组指针,digit可认为是 Int 的别名。
python中整型结构中的数组,每个元素最大存储 15位的二进制数(不同位数操作系统有差异 32 位系统存 16位,64位系统是 32位)。
如 64位系统最大存储32位的二进制数,即存储的最大十进制数为 2^31-1 = 2147483647,也就是说上面例子中数组的一个元素存储的最大值是 2147483647。
需要注意的是:实际存储是以二进制形式存储,而非我们写的十进制。
有人说:一个数组元素所需要的内存大小是4字节即 32 位,但是其实存储数字的有效位是30个(64位系统中)。其原因是:指数运算中要求位移量需要是 5的倍数,可能是某种优化算法,这里不做深究。
10,为什么Python的Range要设计成左开右闭?
Python的Range是左开右闭的,而且除了Python的Range,还有各种语言也有类似的设计。关于Range为什么要设计这个问题,Edsger W.Dijkstra在1982年写过一篇短文中分析了一下其中的原因,当然那时候没有Python,E.W.Dijkstra当年以其他语言为例,但是思路是相通的,这里做摘抄和翻译如下:
为了表示2,3,...,12这样一个序列,有四种方法
- 2 ≤ i < 13(左闭右开区间)
- 1 < i ≤ 12(左开右闭区间)
- 2 ≤ i ≤ 12(闭区间)
- 1 < i < 13(开区间)
其中有没有哪一种是最好的表示法呢?有的,前两种表示法的两端数字的差刚好是序列的长度,而且在这两种的任何一个表示法中,两个相邻子序列的其中一个子序列的上界就是就是另一个子序列的下界,这只是让我们跳出了前两种,而不能让我们从前两种中选出最好的一种方法来,让我们继续分析。
注意到自然数是有最小值的,当我们在下界取<(像第二和第四那样),如果我们想表示从最小的自然数开始的序列,那这种表示法的下界就会是非自然数(比如0,1,....,5会被表示为 -1 < i ≤ 5),这种表示法显得太丑了,所以对于下界,我们喜欢<=。
那我们再来看看上界,在下界使用<=的时候,如果我们对上界也使用<=会发生什么呢?考虑一下当我们想要表示一个空集时,比如0 ≤ i ≤ -1上界会小于下界。显然,这也是很难令人接受的,太反直觉了,而如果上界使用<,就会方便很多,同样表示空集:0 ≤ i < 0。所以,对于上界,我们喜欢 <。
好的,我们通过这些分析发现,第一种表示法是最直接的,我们再来看下标问题,到底我们应该给第一个元素什么值呢?0还是1?对于含有N个元素的序列,使用第一种表示法:
- 当从 1 开始时,下标范围是 1 ≤ i < N+1;
- 而如果从零开始,下标范围是 0 ≤ i < N;
让我们的下标从零开始吧,这样,一个元素的下标就等于当前元素之前的元素的数量了。(an element's subscript equals the number of elements preceding it in the sequence. )