这些年来,以神经网络为代表的机器学习技术逐渐走进了人们的视野。“机器学习”、“深度学习”、“神经网络”、“人工智能”这些概念也从计算机术语走下神坛,成为了妇孺皆知的网红名词。在这篇以及之后的几篇博文里,我就介绍一下机器学习最核心的理论:神经网络的原理,希望能使大家在读完后,能够对神经网络有一个基本的认识。
本系列博客内容主要来源于:《Python神经网络编程》一书。此书前半部分讲理论,后半部分讲Python的实现。我主要讲前半部分,对实现感兴趣的可以阅读它的后半部分。
基本的线性预测机
我们先来看一个最基本的预测模型:在2维空间上,分布着一些点,我们希望输入根据顶点的分布来对它们进行分类,如下图所示:
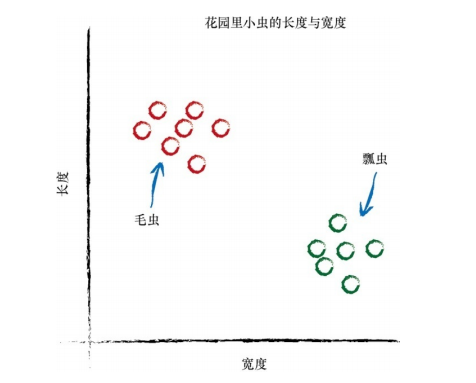
最基本的做法是画一条直线,根据在直线之上还是之下来划分类别:

这条直线的数学表达式还是非常简单的 y=ax+b。那么对这个问题,我们要做的就是输入一系列的顶点和它们的类别,然后根据这些输入数据去计算一个最优的a,b。那么当新来了一个顶点时,输入顶点的坐标,根据判断这个顶点在直线的上面还是下面,我们就可以预测这个顶点属于哪一个类别。
如下图所示:
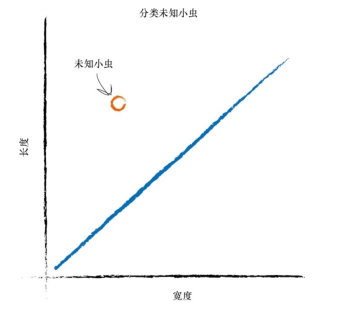
这就是一个机器学习的过程:输入数据的参数和类别用以学习,建立一个数学模型(在上面的例子中就是直线的表达式y=ax+b)来对数据类别进行预测,然后根据输入数据为数学模型来拟合出一个最优的参数(这就是一个所谓“学习”的过程),利用这个参数就可以预测新的数据。这个过程被称为有监督学习,指的是需要提前准备一些数据并标注正确的值,然后将它喂给分类器用于学习,才能预测新的数据。与之对应的是无监督学习,现实中也存在一些难以人工标注类别或进行人工类别标注的成本太高的数据,这种时候期望让计算机自动完成分类的工作,这种就是无监督学习。
线性模型的不足
当然,上面的线性分类器只是一个非常非常简单的数学模型,它面对很多数据是无法进行分类的。比如计算机的逻辑异或函数,它的函数表现如下:
| 输入A | 输入B | 输出 |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
表现在二维坐标系上就是下图的样子:
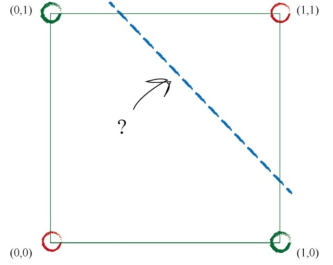
可以看到,无论怎么调整参数,都是无法用一条直线对上图中的红点(标注为0)和绿点(标注为1)完美划分的。但是如果用两条直线就可以了:

所以说,面对复杂的问题,我们可以使用多个线性分类器一起工作。只要线足够多,总是可以得到一个恰当的划分,这就是神经网络的核心思想。我们将在下一篇中介绍神经网络的具体理论。