需要批量操作时候,节省网络连接交互次数,可以使用 bulk_write。
方法一:批量插入insert_many
arr = [] # 初始化一个空列表
for line in mmap_lines(file_path):
arr.append(DbPushPortraitObject(uid=uid, hash_key=hash_key, tag_ids=tag_ids, dt=dt)) # 每次往列表里插DbPushPortraitObject对象
if num % 10000 == 0: # 每次批量插入的数量,10000条插入一次
#print(arr)
DbPushPortraitObject.collection.insert_many(arr)
arr = []
print("num:%d mid: %s" % (num, datetime.datetime.now()))
else:
continue
DbPushPortraitObject.collection.insert_many(arr)
方法二:批量更新bulk_write(UpdateOne)
arr = [] # 初始化一个空列表
for line in mmap_lines(file_path):
one = UpdateOne({"uid": uid}, {"$set": {"hash_key": hash_key, "tag_list": tag_ids, "dt": dt}}, upsert=True) # 每次往列表里插UpdateOne对象
arr.append(one)
if num % 50000 == 0: # 每次批量插入的数量,50000条插入一次
DbPushPortraitObject.collection.bulk_write(arr)
arr = []
print("num:%d mid: %s" % (num, datetime.datetime.now()))
else:
continue
DbPushPortraitObject.collection.bulk_write(arr)
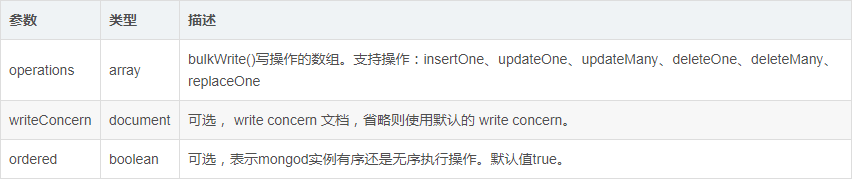
- bulk_write定义
db.collection.bulkWrite()
提供可控执行顺序的批量写操作。
语法格式如下:
db.collection.bulkWrite(
[ <operation 1>, <operation 2>, ... ],
{
writeConcern : <document>,
ordered : <boolean>
}
)
方法返回值:
- 操作基于 write concern 运行则 acknowledged 值为true,如果禁用 write concern 运行则 acknowledged 值为false。
- 每一个写操作数。
- 成功 inserted 或 upserted文档的 _id 的组数。
性能测试
批量更新现在采用的是每5万条进行一次批量更新,更新的效率:2.3255s/每万条
更新的效率还会跟索引数,表collection中原始数据的规模等有关。

转载:https://blog.csdn.net/nihaoxiaocui/article/details/95060906