https://software.intel.com/en-us/blogs/2014/05/10/debugging-performance-issues-in-go-programs
https://studygolang.com/articles/2729
Go 程序的性能调试问题
假设你手上有个Go语言编写的程序,你打算提升它的性能。目前有一些工具可以为此提供帮助。这些工具能帮你发现包括CPU、IO和内存在内多种类型的热点。所谓热点,是指那些为了能显著提升性能而值得你去关注的地方。有时候这些工具还能帮助你发现程序中主要的性能瑕疵。举个例子,你没必要每次执行SQL查询前都对SQL语句进行参数化解析,你可以将这个准备过程在程序启动时一次完成。再举个例子,当前某个算法的复杂度是O(N²),但其实存在一个复杂度是O(N)的解决方案。为了能发现这些问题,需要理智地检查你在优化分析器中获取到的信息。比如上面提到的第一个问题,你会注意到相当长的时间被花费在了对SQL语句的准备上。
了解针对性能的不同边界因素也是比较重要的。比方说,如果一个程序使用100 Mbps带宽的网络进行通信,而目前已经占用了超过90 Mbps的带宽,为了提升它的性能,你拿这样的程序也没啥办法了。在磁盘IO、内存消耗和计算密集型任务方面,也有类似的边界因素。
将这点牢记在心,让我们看看有哪些工具可以用。
注意:这些工具会彼此互相影响。例如,对内存使用优化分析器会导致针对CPU的优化分析器产生误差,对goroutine阻塞使用优化分析器会影响调度器跟踪等等。为了获得更加精确的信息,请在隔离的环境中使用这些工具。
注意:本文描述的用法基于Go语言发布的1.3版。
CPU 分析器
Go 运行时包含了内建的CPU分析器,它用来展示某个函数耗费了多少CPU百分时间。这里有三种方式来使用它:
1. 最简单的是用"go test"的-cpuprofile选项。例如下面的命令:
$ go test -run=none -bench=ClientServerParallel4 -cpuprofile=cprof net/http
将会分析所给的基准并将结果写入"cprof"文件中。
然后:
$ go tool pprof --text http.test cprof
将会打印耗费最多CPU时间的函数列表。
这里有几种可用的输出形式,最实用的有 --text, --web 和 --list。运行 "go tool pprof" 来得到完整的列表。
这个选项最明显的缺点是它只能用来做测试。
2. net/http/pprof 包。这是网络服务器的理想解决方案。你可能仅仅需要导入net/http/pprof,然后使用下面的方法收集分析结果:
$ go tool pprof --text mybin http://myserver:6060:/debug/pprof/profile
3. 手动收集. 你需要导入 runtime/pprof 然后再main函数中添加下面的代码:
if *flagCpuprofile != "" { f, err := os.Create(*flagCpuprofile) if err != nil { log.Fatal(err) } pprof.StartCPUProfile(f) defer pprof.StopCPUProfile() }
分析结果会被写入指定的文件中,像第一种方式一样使之可视化。
这里有一个使用 --web 选项来实现可视化的例子:
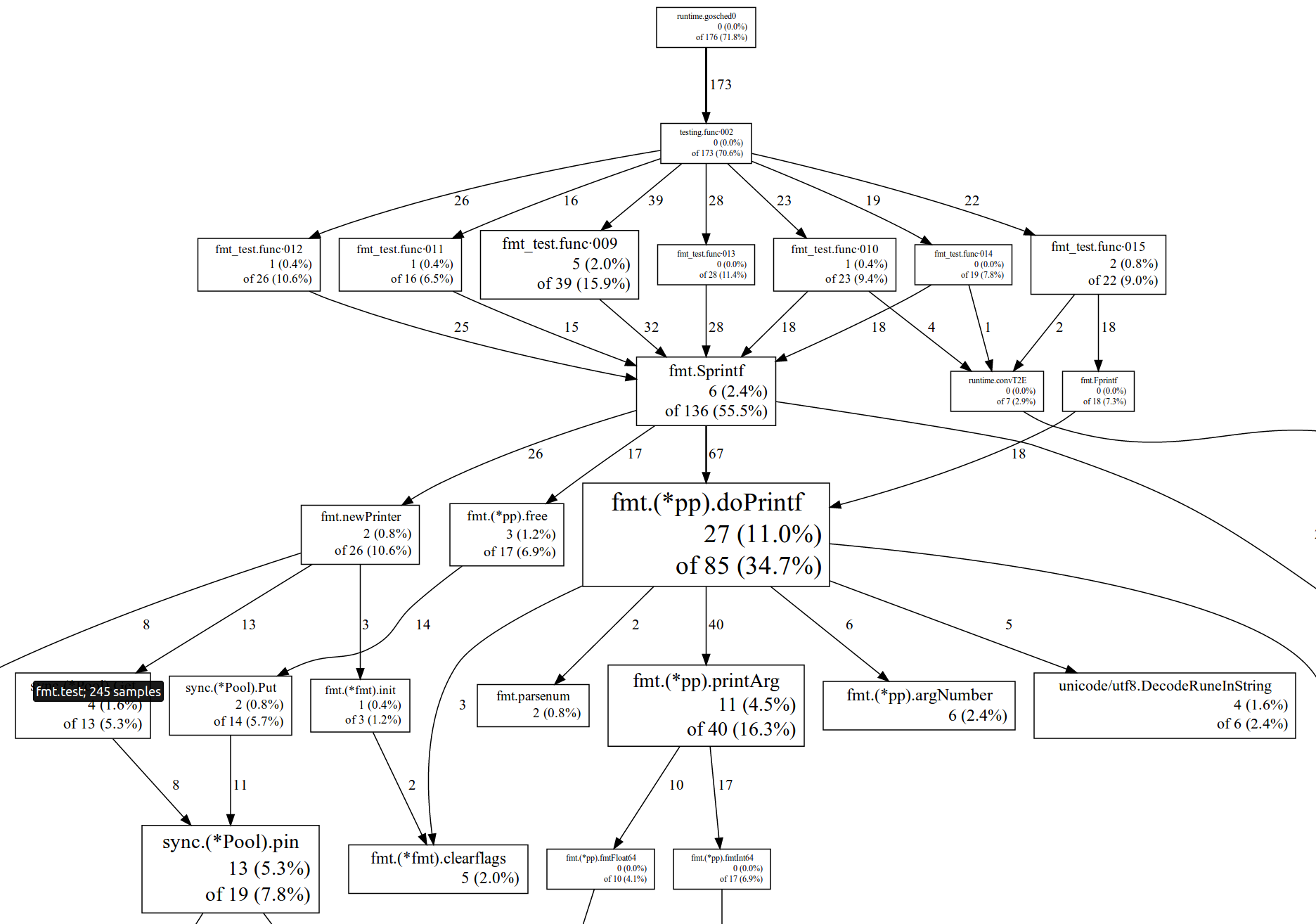
你可以使用--list=funcname来审查单一函数。例如,下面的结果显示了附加函数中的时间流逝:
. . 93: func (bp *buffer) WriteRune(r rune) error { . . 94: if r < utf8.RuneSelf { 5 5 95: *bp = append(*bp, byte(r)) . . 96: return nil . . 97: } . . 98: . . 99: b := *bp . . 100: n := len(b) . . 101: for n+utf8.UTFMax > cap(b) { . . 102: b = append(b, 0) . . 103: } . . 104: w := utf8.EncodeRune(b[n:n+utf8.UTFMax], r) . . 105: *bp = b[:n+w] . . 106: return nil . . 107: }
|
你可以在这里找到pprof工具的详细信息以及上图中数字的描述。 在3种特殊的情形下分析器不能解开堆栈:GC,System和ExternalCode。GC 表示垃圾回收期间的用时,查看下面的内存分析器和垃圾回收跟踪器以得到优化建议。System 表示goroutine调度程序,栈管理代码和其他辅助运行时代码的用时。ExternalCode 表示本地动态库耗时。 |

Micooz
|
对于你在简介中看到的东西的解释,这里有一些提示和技巧。
如果你看到大量的时间消耗在运行时间,内存分配的函数,那么暗示程序产生了大量过度的小内存分配工作。此描述将会告诉你这些分配来自哪里。查看内存分析器部分可以获得如何优化这种情况的建议。可考虑对程序进行重新调整以消除频繁对共享资源的获取和接入。对此,一般的解决技术方案包括有分片/分区,本地缓存/计量和写时拷贝。
如果大量的时间消耗在频道操作,同步。互斥代码和其他同步原语或者系统容器,那么程序很可能正在饱受资源争夺的痛苦。
如果大量的时间消耗在系统调用的读/写,那么暗示程序产生了大量过度的小块读写。对这种情况,围绕系统文件或者网络连接而包装的Bufio会很有帮助。
如果大量的时间消耗在GC容器,那么程序要么分配了大量的短暂临时的对象,要么堆栈的空间非常小以致垃圾回收收集变得非常频繁。通过查看垃圾收集追踪器和内存分析器这两部分可以得到一些优化的建议。
温馨提示:当前CPU分析器不能工作于darwin。
温馨提示:在windows系统上你需要安装Cygwin, Perl和Graphviz才能生成svg/web简介。
温馨提示:在linux系统上你也可以尝试PERF系统分析器。它不能解开Go的栈,但它可以获得cgo或者SWIG的代码和kernel内核的快照并解开。所以它对于洞悉本地/kernel内核的性能瓶颈非常有帮助。
内存分析器
内存分析器展示了哪些函数申请了堆内存。你可以通过熟悉的途径来收集这些信息,一如使用CPU分析器:和 'go test --memprofile', 以及通过 http://myserver:6060:/debug/pprof/heap的net/http/pprof 或者通过调用runtime/pprof.WriteHeapProfile。
你仅仅可以可视化描述收集器当前时间内的申请(默认下--inuse_space标识指向pprof),或者自程序启动以来全部的申请(--alloc_space标识指向pprof)。前者对于在当前活动的程序通过net/http/pprof收集描述很有帮助,而后者则对在程序后端(否则你将会看到的几乎都是空的描述)收集描述有帮助。
温馨提示:内存分析器采取抽样的方式,也就是说,它仅仅从一些内存分配的子集中收集信息。有可能对一个对象的采样与被采样对象的大小成比例。你可以通过使用go test --memprofilerate标识,或者通过程序启动时 的运行配置中的MemProfileRate变量来改变调整这个采样的比例。如果比例为1,则会导致全部申请的信息都会被收集,但是这样的话将会使得执行变慢。默认的采样比例是每512KB的内存申请就采样一次。
你同样可以将分配的字节数或者分配的对象数形象化(分别是以--inuse/alloc_space和--inuse/alloc_objects为标志)。分析器倾向于在性能分析中对较大的对象采样。但是需要注意的是大的对象会影响内存消耗和垃圾回收时间,大量的小的内存分配会影响运行速度(某种程度上也会影响垃圾回收时间)。所以最好同时考虑它们。
对象可以是持续的也可以是瞬时的。如果你在程序开始的时候需要分配几个大的持续对象,它们很有可能能被分析器取样(因为它们比较大)这些对象会影响内存消耗量和垃圾回收时间,但它们不会影响正常的运行速度(在它们上没有内存管理操作)。另一方面,如果你有大量持续期很短的对象,它们几乎不会表现在曲线中(如果你使用默认的--inuse_space模式)。但它们的确显著影响运行速度,因为它们被不断地分配和释放。所以再说一遍,最好同时考虑这两种类型的对象。
所以,大体上,如果你想减小内存消耗量,那么你需要查看程序正常运行时--inuse_space收集的概要。如果你想提升程序的运行速度,就要查看在程序特征运行时间后或程序结束之后--alloc_objects收集的概要。
报告间隔时间由几个标志控制,--functions让pprof报告在函数等级(默认)。--lines使pprof报告基于代码行等级,如果关键函数分布在不同的代码行上,这将变得很有用。同样还有--addresses和--files选项, 分别定位到精确的指令地址等级和文件等级。
还有一个对内存概要很有用的选项,你可以直接在浏览器中查看它(需要你导入net/http/pprof包)。你打开http://myserver:6060/debug/pprof/heap?debug=1就会看到堆概要,如下:
heap profile: 4: 266528 [123: 11284472] @ heap/1048576 1: 262144 [4: 376832] @ 0x28d9f 0x2a201 0x2a28a 0x2624d 0x26188 0x94ca3 0x94a0b 0x17add6 0x17ae9f 0x1069d3 0xfe911 0xf0a3e 0xf0d22 0x21a70 # 0x2a201 cnew+0xc1 runtime/malloc.goc:718 # 0x2a28a runtime.cnewarray+0x3a runtime/malloc.goc:731 # 0x2624d makeslice1+0x4d runtime/slice.c:57 # 0x26188 runtime.makeslice+0x98 runtime/slice.c:38 # 0x94ca3 bytes.makeSlice+0x63 bytes/buffer.go:191 # 0x94a0b bytes.(*Buffer).ReadFrom+0xcb bytes/buffer.go:163 # 0x17add6 io/ioutil.readAll+0x156 io/ioutil/ioutil.go:32 # 0x17ae9f io/ioutil.ReadAll+0x3f io/ioutil/ioutil.go:41 # 0x1069d3 godoc/vfs.ReadFile+0x133 godoc/vfs/vfs.go:44 # 0xfe911 godoc.func·023+0x471 godoc/meta.go:80 # 0xf0a3e godoc.(*Corpus).updateMetadata+0x9e godoc/meta.go:101 # 0xf0d22 godoc.(*Corpus).refreshMetadataLoop+0x42 godoc/meta.go:141 2: 4096 [2: 4096] @ 0x28d9f 0x29059 0x1d252 0x1d450 0x106993 0xf1225 0xe1489 0xfbcad 0x21a70 # 0x1d252 newdefer+0x112 runtime/panic.c:49 # 0x1d450 runtime.deferproc+0x10 runtime/panic.c:132 # 0x106993 godoc/vfs.ReadFile+0xf3 godoc/vfs/vfs.go:43 # 0xf1225 godoc.(*Corpus).parseFile+0x75 godoc/parser.go:20 # 0xe1489 godoc.(*treeBuilder).newDirTree+0x8e9 godoc/dirtrees.go:108 # 0xfbcad godoc.func·002+0x15d godoc/dirtrees.go:100
每个条目开头的数字("1: 262144 [4: 376832]")分别表示目前存活的对象,存活对象占据的内存, 分配对象的个数和所有分配对象占据的内存总量。
优化工作经常和特定应用程序相关,但也有一些普遍建议。
1. 将小对象组合成大对象。比如, 将 *bytes.Buffer 结构体成员替换为bytes。缓冲区 (你可以预分配然后通过调用bytes.Buffer.Grow为写做准备) 。这将减少很多内存分配(更快)并且减缓垃圾回收器的压力(更快的垃圾回收) 。
2. 离开声明作用域的局部变量促进堆分配。编译器不能保证这些变量拥有相同的生命周期,因此为他们分别分配空间。所以你也可以对局部变量使用上述的建议。比如:将
for k, v := range m { k, v := k, v // copy for capturing by the goroutine go func() { // use k and v }()
}
替换为:
for k, v := range m { x := struct{ k, v string }{k, v} // copy for capturing by the goroutine go func() { // use x.k and x.v }() }
这就将两次内存分配替换为了一次。然而,这样的优化方式会影响代码的可读性,因此要合理地使用它。
3. 组合内存分配的一个特殊情形是分片数组预分配。如果你清楚一个特定的分片的大小,你可以给末尾数组进行预分配:
type X struct { buf []byte bufArray [16]byte // Buf usually does not grow beyond 16 bytes. } func MakeX() *X { x := &X{} // Preinitialize buf with the backing array. x.buf = x.bufArray[:0] return x }
4. 尽可能使用小数据类型。比如用int8代替int。
5. 不包含任何指针的对象(注意 strings,slices,maps 和 chans 包含隐含指针)不会被垃圾回收器扫描到。比如,1GB 的分片实际上不会影响垃圾回收时间。因此如果你删除被频繁使用的对象指针,它会对垃圾回收时间造成影响。一些建议:使用索引替换指针,将对象分割为其中之一不含指针的两部分。
6. 使用释放列表来重用临时对象,减少内存分配。标准库包含的 sync.Pool 类型可以实现垃圾回收期间多次重用同一个对象。然而需要注意的是,对于任何手动内存管理的方案来说,不正确地使用sync.Pool 会导致 use-after-free bug。
你也可以使用Garbage Collector Trace(见后文)来获取更深层次的内存问题。
阻塞分析器
阻塞分析器展示了goroutine在等待同步原语(包括计时器通道)被阻塞的位置。你可以用类似CPU分析器的方法来收集这些信息:通过'go test --blockprofile', net/http/pprof(经由h ttp://myserver:6060:/debug/pprof/block) 或者调用 runtime/pprof.Lookup("block").WriteTo。
值得警示的是,阻塞分析器默认未激活。'go test --blockprofile' 将为你自动激活它。然而,如果你使用net/http/pprof 或者 runtime/pprof,你就需要手动激活它(否则分析器将不会被载入)。通过调用 runtime.SetBlockProfileRate 来激活阻塞分析器。SetBlockProfileRate 控制着由阻塞分析器报告的goroutine阻塞事件的比率。分析器力求采样出每指定微秒数内,一个阻塞事件的阻塞平均数。要使分析器记录每个阻塞事件,将比率设为1。
如果一个函数包含了几个阻塞操作而且并没有哪一个明显地占有阻塞优势,那就在pprof中使用--lines标志。
注意:并非所有的阻塞都是不利的。当一个goroutine阻塞时,底层的工作线程就会简单地转换到另一个goroutine。所以Go并行环境下的阻塞
与非并行环境下的mutex的阻塞是有很大不同的(例如典型的C++或Java线程库,当发生阻塞时会引起线程空载和高昂的线程切换)。为了让你感受一
下,我们来看几个例子。
在
time.Ticker上发生的阻塞通常是可行的,如果一个goroutine阻塞Ticker超过十秒,你将会在profile中看到有十秒的阻塞,这
是很好的。发生在sync.WaitGroup上的阻塞经常也是可以的,例如,一个任务需要十秒,等待WaitGroup完成的goroutine会在
profile中生成十秒的阻塞。发生在sync.Cond上的阻塞可好可坏,取决于情况不同。消费者在通道阻塞表明生产者缓慢或不工作。生产者在通道阻塞,表明消费者缓慢,但这通常也是可以的。在基于通道的信号量发生阻塞,表明了限制在这个信号量上的goroutine的数量。发生在sync.Mutex或sync.RWMutex上的阻塞通常是不利的。你可以在可视化过程中,在pprof中使用--ignore标志来从profile中排除已知的无关阻塞。
goroutine的阻塞会导致两个消极的后果:
-
程序与处理器之间不成比例,原因是缺乏工作。调度器追踪工具可以帮助确定这种情况。
-
过多的goroutine阻塞/解除阻塞消耗了CPU时间。CPU分析器可以帮助确定这种情况(在系统组件中找)。
这里是一些通常的建议,可以帮助减少goroutine阻塞:
-
在生产者--消费者情景中使用充足的缓冲通道。无缓冲的通道实际上限制了程序的并发可用性。
-
针对于主要为读取的工作量,使用sync.RWMutex而不是sync.Mutex。因为读取操作在sync.RWMutex中从来不会阻塞其它的读取操作。甚至是在实施级别。
-
在某些情况下,可以通过使用copy-on-write技术来完全移除互斥。如果受保护的数据结构很少被修改,可以为它制作一份副本,然后就可以这样更新它:
type Config struct { Routes map[string]net.Addr Backends []net.Addr } var config unsafe.Pointer // actual type is *Config
// Worker goroutines use this function to obtain the current config. func CurrentConfig() *Config { return (*Config)(atomic.LoadPointer(&config)) } // Background goroutine periodically creates a new Config object // as sets it as current using this function. func UpdateConfig(cfg *Config) { atomic.StorePointer(&config, unsafe.Pointer(cfg)) }
这种模式可以防止在更新时阻塞的读取对它的写入。
4. 分割是另一种用于减少共享可变数据结构竞争和阻塞的通用技术。下面是一个展示如何分割哈希表(hashmap)的例子:
type Partition struct { sync.RWMutex m map[string]string } const partCount = 64 var m [partCount]Partition func Find(k string) string { idx := hash(k) % partCount part := &m[idx] part.RLock() v := part.m[k] part.RUnlock() return v }
5. 本地缓存和更新的批处理有助于减少对不可分解的数据结构的争夺。下面你将看到如何分批处理向通道发送的内容:
const CacheSize = 16 type Cache struct { buf [CacheSize]int pos int } func Send(c chan [CacheSize]int, cache *Cache, value int) { cache.buf[cache.pos] = value cache.pos++ if cache.pos == CacheSize { c <- cache.buf cache.pos = 0 } }
这种技术并不仅限于通道,它还能用于批量更新映射(map)、批量分配等等。
6. 针对freelists,使用sync.Pool代替基于通道的或互斥保护的freelists,因为sync.Pool内部使用智能技术来减少阻塞。
Go协程分析器
Go协程分析器简单地提供给你当前进程中所有活跃的Go协程堆栈。它可以方便地调试负载平衡问题(参考下面的调度器追踪章节),或调试死锁。
这个配置仅仅对运行的程序有意义,所以去测试而不是揭露它. 你可以用net/http/pprof通过http://myserver:6060:/debug/pprof/goroutine来收集配置,并将之形象化为svg/pdf或通过调用runtime/pprof.Lookup("goroutine").WriteTo形象化。但最有用的方式是在你的浏览器中键入http://myserver:6060:/debug/pprof/goroutine?debug=2,它将会给出与程序崩溃时相同的符号化的堆栈。
需要注意的是:Go协程“syscall”将会消耗一个OS线程,而其他的Go协程则不会(除了名为runtime.LockOSThread的Go协程,不幸的是,它在配置中是不可见的)。同样需要注意的是在“IO wait”状态的Go协程同样不会消耗线程,他们停驻在非阻塞的网络轮询器(通常稍后使用epoll/kqueue/GetQueuedCompletionStatus来唤醒Go协程)。
垃圾收集器追踪
除了性能分析工具以外,还有另外几种工具可用——追踪器。它们可以追踪垃圾回收,内存分配和goroutine调度状态。要启用垃圾回收器(GC)追踪你需要将GODEBUG=gctrace=1加入环境变量,再运行程序:
$ GODEBUG=gctrace=1 ./myserver
然后程序在运行中会输出类似结果:
gc9(2): 12+1+744+8 us, 2 -> 10 MB, 108615 (593983-485368) objects, 4825/3620/0 sweeps, 0(0) handoff, 6(91) steal, 16/1/0 yieldsgc10(2): 12+6769+767+3 us, 1 -> 1 MB, 4222 (593983-589761) objects, 4825/0/1898 sweeps, 0(0) handoff, 6(93) steal, 16/10/2 yieldsgc11(2): 799+3+2050+3 us, 1 -> 69 MB, 831819 (1484009-652190) objects, 4825/691/0 sweeps, 0(0) handoff, 5(105) steal, 16/1/0 yields来看看这些数字的意思。每个GC输出一行。第一个数字("gc9")是GC的编号(这是从程序开始后的第九个GC),在括号中的数字("(2)")是参与GC的工作线程的编号。随后的四个数字("12+1+744+8 us")分别是工作线程完成GC的stop-the-world, sweeping, marking和waiting时间,单位是微秒。接下来的两个数字("2 -> 10 MB")表示前一个GC过后的存活堆大小和当前GC开始前完整的堆(包括垃圾)的大小。再接下来的三个数字 ("108615 (593983-485368) objects")是堆中的对象总数(包括垃圾)和和分配的内存总数以及空闲内存总数。后面的三个数字("4825/3620/0 sweeps")表示清理阶段(对于前一个GC):总共有4825个存储器容量,3620立即或在后台清除,0个在stop-the-world阶段清除(剩余的是没有使用的容量)。再后面的四个数字("0(0) handoff, 6(91) steal")表示在平行的标志阶段的负载平衡:0个切换操作(0个对象被切换)和六个steal 操作(91个对象被窃取)最后的三个数字("16/1/0 yields")表示平行标志阶段的系数:在等候其它线程的过程中共有十七个yield操作。
GC 是 mark-and-sweep 类型。总的 GC 可以表示成:
Tgc = Tseq + Tmark + Tsweep
这里的 Tseq 是停止用户的 goroutine 和做一些准备活动(通常很小)需要的时间;Tmark 是堆标记时间,标记发生在所有用户 goroutine 停止时,因此可以显著地影响处理的延迟;Tsweep 是堆清除时间,清除通常与正常的程序运行同时发生,所以对延迟来说是不太关键的。
标记时间大概可以表示成:
Tmark = C1*Nlive + C2*MEMlive_ptr + C3*Nlive_ptr
这里的 Nlive 是垃圾回收过程中堆中的活动对象的数量,MEMlive_ptr 是带有指针的活动对象占据的内存总量,Nlive_ptr 是活动对象中的指针数量。
清除时间大概可以表示成:
Tsweep = C4*MEMtotal + C5*MEMgarbage
这里的 MEMtotal 是堆内存的总量,MEMgarbage 是堆中的垃圾总量。
下一次垃圾回收发生在程序被分配了一块与其当前所用内存成比例的额外内存时。这个比例通常是由 GOGC 的环境变量(默认值是100)控制的。如果 GOGC=100,而且程序使用了 4M 堆内存,当程序使用达到 8M 时,运行时(runtime)就会再次触发垃圾回收器。这使垃圾回收的消耗与分配的消耗保持线性比例。调整 GOGC,会改变线性常数和使用的额外内存的总量。
只有清除是依赖于堆总量的,且清除与正常的程序运行同时发生。如果你可以承受额外的内存开销,设置 GOGC 到以一个较高的值(200, 300, 500,等)是有意义的。例如,GOGC=300 可以在延迟相同的情况下减小垃圾回收开销高达原来的二分之一(但会占用两倍大的堆)。
GC 是并行的,而且一般在并行硬件上具有良好可扩展性。所以给 GOMAXPROCS 设置较高的值是有意义的,就算是对连续的程序来说也能够提高垃圾回收速度。但是,要注意,目前垃圾回收器线程的数量被限制在 8 个以内。
内存分配器跟踪
内存分配器跟踪只是简单地将所有的内存分配和释放操作转储到控制台。通过设置环境变量“GODEBUG=allocfreetrace=1”就可以开启该功能。输出看起来像下面的内容:
tracealloc(0xc208062500, 0x100, array of parse.Node)goroutine 16 [running]:runtime.mallocgc(0x100, 0x3eb7c1, 0x0) runtime/malloc.goc:190 +0x145 fp=0xc2080b39f8runtime.growslice(0x31f840, 0xc208060700, 0x8, 0x8, 0x1, 0x0, 0x0, 0x0) runtime/slice.goc:76 +0xbb fp=0xc2080b3a90text/template/parse.(*Tree).parse(0xc2080820e0, 0xc208023620, 0x0, 0x0) text/template/parse/parse.go:289 +0x549 fp=0xc2080b3c50...tracefree(0xc208002d80, 0x120)goroutine 16 [running]:runtime.MSpan_Sweep(0x73b080) runtime/mgc0.c:1880 +0x514 fp=0xc20804b8f0runtime.MCentral_CacheSpan(0x69c858) runtime/mcentral.c:48 +0x2b5 fp=0xc20804b920runtime.MCache_Refill(0x737000, 0xc200000012) runtime/mcache.c:78 +0x119 fp=0xc20804b950...跟踪信息包括内存块地址、大小、类型、执行程序ID和堆栈踪迹。它可能更有助于调试,但也可以给内存分配优化提供非常详细的信息。
调度器追踪
调度器追踪可以提供对 goroutine 调度的动态行为的内视,并且允许调试负载平衡和可扩展性问题。要启用调度器追踪,可以带有环境变量 GODEBUG=schedtrace=1000 来运行程序(这个值的意思是输入的周期,单位 ms,这种情况下是每秒一次):
$ GODEBUG=schedtrace=1000 ./myserver
程序在运行过程中将会输出类似结果:
SCHED 1004ms: gomaxprocs=4 idleprocs=0 threads=11 idlethreads=4 runqueue=8 [0 1 0 3]SCHED 2005ms: gomaxprocs=4 idleprocs=0 threads=11 idlethreads=5 runqueue=6 [1 5 4 0]SCHED 3008ms: gomaxprocs=4 idleprocs=0 threads=11 idlethreads=4 runqueue=10 [2 2 2 1]注意:你可以随意组合追踪器,如:GODEBUG = gctrace = 1,allocfreetrace = 1,schedtrace = 1000。
注意:同样有详细的调度器追踪,你可以这样启用它:GODEBUG = schedtrace = 1000,scheddetail = 1。它将会输出每一个 goroutine、工作线程和处理器的详细信息。我们将不会在这里讨论它的格式,因为它主要是给调度器开发者使用;你可以在这里src/pkg/runtime/proc.c找到它的详细信息。
当一个程序不与 GOMAXPROCS 成线性比例和/或没有消耗 100% 的 CPU 时间,调度器追踪就显得非常有用。理想的情况是:所有的处理器都在忙碌地运行 Go 代码,线程数合理,所有队列都有充足的任务且任务是合理均匀的分布的:
gomaxprocs=8 idleprocs=0 threads=40 idlethreads=5 runqueue=10 [20 20 20 20 20 20 20 20]
不好的情况是上面所列的东西并没有完全达到。例如下面这个演示,没有足够的任务来保持所有的处理器繁忙:
gomaxprocs=8 idleprocs=6 threads=40 idlethreads=30 runqueue=0 [0 2 0 0 0 1 0 0]
注意:这里使用操作系统提供的实际CPU利用率作为最终的标准。在 Unix 系操作系统中是 top 命令。在 Windows 系统中是任务管理器。
你可以使用 goroutine 分析器来了解哪些 goroutine 块处于任务短缺状态。注意,只要所有的处理器处于忙绿状态,负载失衡就不是最坏的,它只会导致适度的负载平衡开销。
内存统计
Go 运行时可以通过 runtime.ReadMemStats 函数提供粗糙的内存统计。这个统计同样可以通过 http://myserver:6060/debug/pprof/heap?debug=1 底部的net/http/pprof提供。统计资料,点击此处。
一些值得关注的地方是:
1. HeapAlloc - 当前堆大小。
2. HeapSys - 总的堆大小。
3. HeapObjects - 堆中对象的总数。
4. HeapReleased - 释放到操作系统中的内存;如果内存超过五分钟没有使用,运行时将会把它释放到操作系统中,你可以通过 runtime/debug.FreeOSMemory 来强制改变这个过程。
5. Sys - 操作系统分配的总内存。
6. Sys-HeapReleased - 程序的有效内存消耗。
7. StackSys - goroutine 栈的内存消耗(注意:一些栈是从堆中分配的,因此没有计入这里,不幸的是,没有办法得到栈的总大小(https://code.google.com/p/go/issues/detail?id=7468))。
8. MSpanSys/MCacheSys/BuckHashSys/GCSys/OtherSys - 运行时为各种辅助用途分配的内存;它们没什么好关注的,除非过高的话。
9. PauseNs - 最后一次垃圾回收的持续时间。
堆倾卸器
最后一个可用的工具是堆倾卸器,它可以将整个堆的状态写入一个文件中,留作以后进行探索。它有助于识别内存泄露,并能够洞悉程序的内存消耗。
首先,你需要使用函数runtime/debug.WriteHeapDump函数编写倾卸器(dump):
f, err := os.Create("heapdump") if err != nil { ... } debug.WriteHeapDump(f.Fd())
然后,你既可以将堆以图形化的表现形式保存为.dot文件,也可以将它转换为hprof格式。为了将它保存为.dot文件,你需要执行以下指令:
|
1
2
|
$ go get github.com/randall77/hprof/dumptodot$ dumptodot heapdump mybinary > heap.dot |
最后,使用Graphviz工具打开heap.dot文件。
为了将堆转换成hprof格式,需要执行以下指令:
|
1
2
3
|
$ go get github.com/randall77/hprof/dumptohprof$ dumptohprof heapdump heap.hprof$ jhat heap.hprof |
结束语
优化是一个开放的问题,你可以使用很多简单的方法来提高性能。然而,有时优化需要对程序进行完整地重新架构。但我们希望这些工具能够成为你工具箱中一个有价值的新增成员,至少你可以使用它们分析并理解到底发生了什么。
《剖析Go程序》是一个很好的教程,它讲解了如何利用CPU和内存分析器来优化简单的程序。