在基于敏捷的测试金字塔模型中,把测试的层次分为三层,其中最底层的是单元测试,中间层是API测试,最上面层次是UI层,基于saas化的架构模式以及新的思想层次,我们
可以更加细化的,增加组件测试,具体如下图所示:

在这里,我们更多看到的是思想背后的成本,也就是说从软件经济学的角度而言,越底层的测试应该投入的越多,而最上层应用应该投入的资源更少,这很好的理解。在用户的角度,更
多关注的是最上层的产品形态,也就是用户最直观的体验,这些体验就包含了产品的UI设计,产品的基本逻辑等等,以及这些逻辑给用户可以带来那些有价值的信息流。但是呈现在上层
的这些应用感受,都需要底层一个好的架构设计和底层产品质量体系的保障,比如底层服务雪崩,OOM,连接数泄露,DB层面出现无法连接,MQ组件消息堵塞,任务积压,这些任何
的一个问题暴露,直接影响的是最上层的用户对产品的体验。我们可以更加具体点,比如在上层应用中,一个UI设计的不好,最多影响的是部分用户的感受,因为对“审美”的定义是很
难满足所有的用户形态的,即使再糟糕的用户UI设计,也影响的是部分用户,但是如果是一个服务组件雪崩,那么影响的是所有的用户,也就是说在前者问题上,虽然用户感觉这个UI
设计很不具备艺术性,很丑,但是产品逻辑是可以的,逻辑背后是用户需要的价值流的信息,但是如果是一个服务雪崩,那么意味着产品某一个模块出问题,影响的直接是用户获取价值
流的东西,和对产品的极度不信任感。在人性的角度而言,可以接受一个很丑的东西,但是无法接受一个不可用的东西。从如上的这些信息我们看出,也就很好的理解了为什么越底层的
测试应该投入更多的资源,到最后它的成本是最小的。
单元测试更多的是开发同学在承载这部分的任务,测试更多的在服务端的测试和客户端的测试投入的精力比较多,从上面的金字塔模型而言,我们应该把更多的精力投入到服务端的测
试,比如是一本微服务的架构产品,我们在底层的测试到底需要保障那些了?先来看一个简单的请求,具体如下图所示:

客户端发起一个请求,请求到网关,经过网关后,由调度程序决定任务是否下发,经过一系列的资源检查,任务下发后,请求到服务端的程序,然后进行执行,最后把执行的结果信息响应回复
给客户端。这个过程中,先来关注第一个点,也就是请求流程,在微服务的架构中,服务和服务之间的通信是非常重要的,它是基于轻量级的HTTP协议的REST API为通信,那么在这个通信中
,我们更多关心的是一个请求流程,也就是说客户端发送请求,到服务端的响应回复,它的完整的请求流程如下图所示:
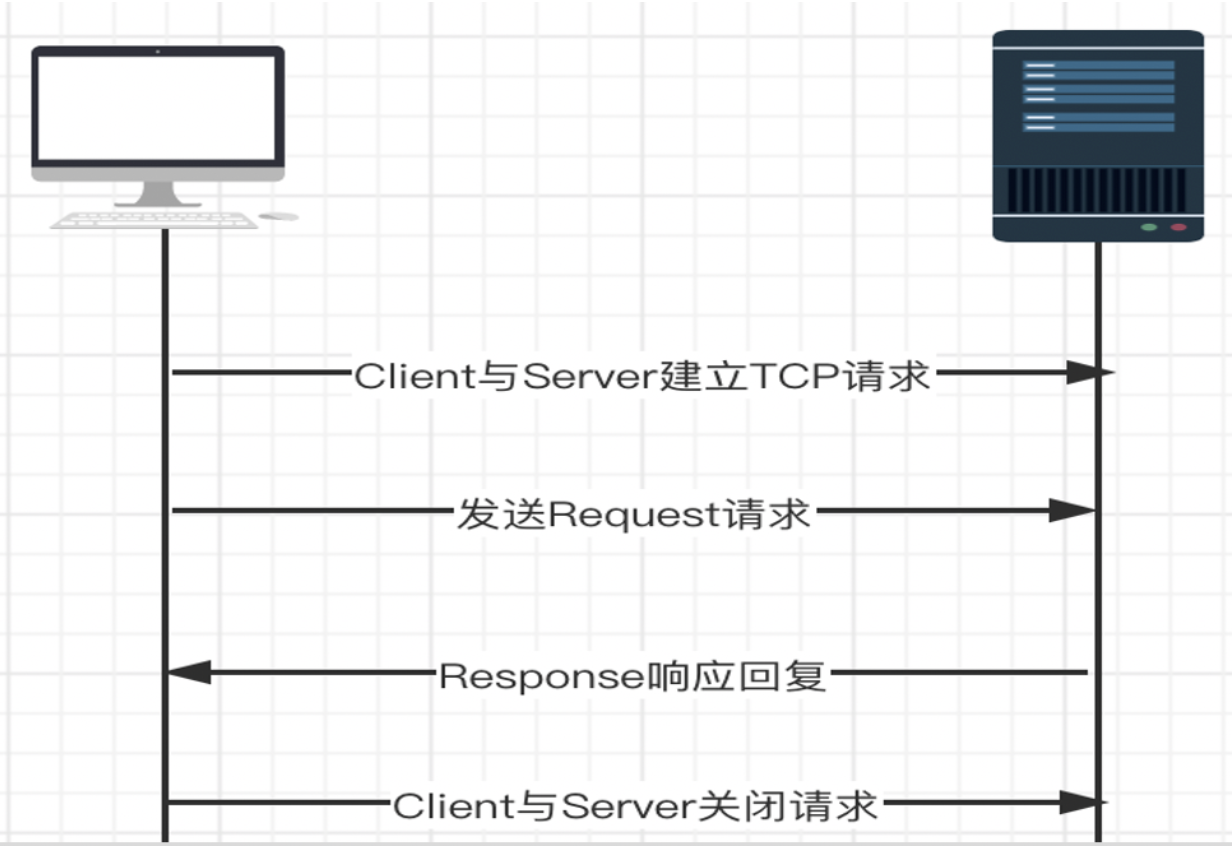
HTTP是基于应用层的协议,所以它不需要关注底层网络传属层协议的事情,但是客户端与服务端的通信,首先需要客户端与服务端建立TCP的连接,然后才能够进行通信。在通信交互的过程中,
涉及到同步通信和异步通信,同步通信可以简单的描述为客户端向服务端发送请求后,服务端必须得回应客户端的请求,所以它的缺点是超时,因为客户端向服务端发送请求后,这个过程中可能会
存在网络超时或者是网关超时的情况,导致没有回应而出现超时,它的交互为:

也可以理解为请求/响应的模式。基于同步通信的超时,或者说有的业务形态,使用异步通信的方式更加合理,在异步通信中,客户端和服务端根本不知道对方的存在,双方更多关注的是MQ消息,也
就是说客户端生成消息发送给消息代理,客户端根本不需要关心服务端是否存在,只需要关心的是想要的消息在MQ代理中存在就读取它,这样的交互也就避免了同步通信中可能出现的线程阻塞的情况
,异步通信的交互如下图所示:

了解了这些信息后,在服务端的底层测试中,我们需要在不同维度来进行思考,从而来保障它的稳定性这部分,具体可以描述为服务端的并发能力,也就是说性能测试部分,这部分在文章的后面部分
我们详细的去讲,还有就是稳定性部分,如服务持续的请求是否会出现线程堵塞,任务积压的情况,以及可能服务假死的异常,另外如果服务是基于IO密集型的,在多任务的请求后,是否存在内存溢出
(OOM)的异常情况,最大承载的数据量是多少,比如到某一个人值请求,服务就会出现内存泄露,那么这个值是否满足业务的需求,如果不满足,就需要对这个服务进行优化和调整,可能还需要调整JVM
的参数,以及内存线程堆栈等信息的监控,最后调整到符合业务形态的情况,还有一点就是在服务端的角度而言,不可能所有的客户端请求都进行及时有效的处理,因为服务端的资源有限的,这就涉及到
到底可以承载多少的并发请求,但是超过这个并发请求后,服务端这层的调度策略是什么,任务排队的机制是什么,任务排队是否有超时时间,如果任务在运行过程中服务出现异常情况,服务重新启动后
之前运行的任务怎么处理等等这些逻辑都需要考虑进去,另外就是DB层面,这个层面需要关注超时情况,以及连接数的情况,和连接数的泄露情况,如建立连接数后,任务处理完成了,但是连接数并没有
得到释放,而是一直在累加,最后导致DB的连接数被占用完,这个时候所有的客户端请求都会报无法建立新的连接,也就导致了所有的读写都会进行超时等情况。
针对前面说的,下面更加的具体化,就是在服务端的测试中,我们怎么编写一个好的测试用例,或者说是一个合格的测试用例,在一个完整的测试中,我们期望自动化它能够承载最大的价值,去替代
人可以持续去做的事情,而让人投入到机器无法实现的点上,比如前面说的,内存泄露,这些场景需要多次验证校验,不是一次就可以搞定的。不管自动化测试用例怎么执行,怎么编写,我们期望的是执行
前和执行后环境是一致的,不能让每次执行一次后对现有环境进行破坏,或者说需要人为的去参与进去,比如之前,为了某些场景人为刻意的去添加一些数据,这些很不符合自动化的设计思想,因为在一个
完整的自动化测试用例中,我们第一步需要做的是初始化,第二步是执行测试步骤,也就是我们的CASE,第三步是断言,验证CASE是否满足期望的结果信息,最后一步是清理环境,具体如下图所示:
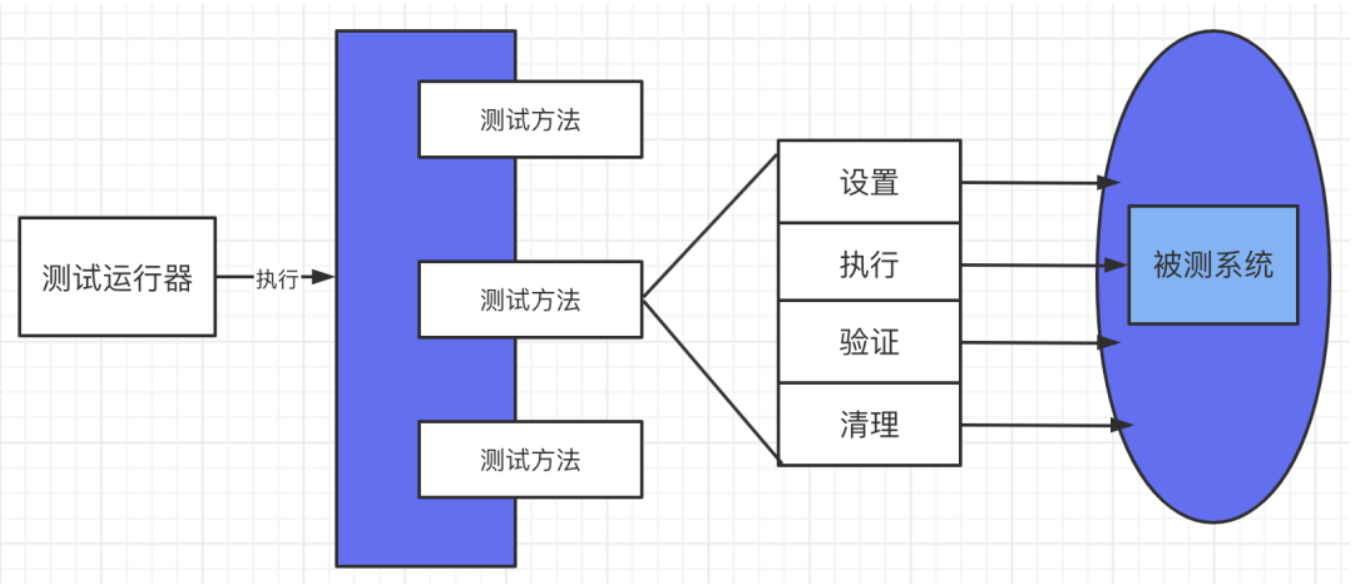
在如上的图中,我们可以很清晰的看到每个测试用例,都必须并且得包含初始化,测试执行,测试验证以及最后的清理过程。其实我们的目的非常单独以及简单,我们期望的是自动化测试用例执行前和执行
后环境是一样的,不能因为每次自动化测试用例执行了而破坏了环境,这是第一要务。当然还有一点需要注意的是,这我们我们更多基于API的维度来思考,就是API测试用例的编写,我们平常遇到的测试用
例基本都是有互相关联的,也就是说A测试用例的输出是B测试用例的输入,这是一个场景,还有就是依赖性,依赖性主要表现为我们需要验证B,可能需要依赖A和C这样的测试用例,这也就导致了测试用例
执行是有顺序的,那么就涉及一个问题,既然是依赖性的,我们编写的测试用例应该具备有顺序性吗?如下的案例场景,被测试的源码为:
from flask import Flask,make_response,jsonify,abort,request
from flask_restful import Api,Resource
from flask_httpauth import HTTPBasicAuth
from flask import Flask
from flask_jwt import JWT, jwt_required, current_identity
from werkzeug.security import safe_str_cmp
app=Flask(__name__)
app.debug = True
app.config['SECRET_KEY'] = 'super-secret'
api=Api(app=app)
auth=HTTPBasicAuth()
@auth.get_password
def get_password(name):
if name=='admin':
return 'admin'
@auth.error_handler
def authoorized():
return make_response(jsonify({'msg':"请认证"}),403)
books=[
{'id':1,'author':'wuya','name':'Python接口自动化测试实战','done':True},
{'id':2,'author':'无涯','name':'Selenium3自动化测试实战','done':False}
]
class User(object):
def __init__(self, id, username, password):
self.id = id
self.username = username
self.password = password
def __str__(self):
return "User(id='%s')" % self.id
users = [
User(1, 'wuya', 'asd888'),
User(2, 'admin', 'asd888'),
User(3,'share','asd888')
]
username_table = {u.username: u for u in users}
userid_table = {u.id: u for u in users}
def authenticate(username, password):
user = username_table.get(username, None)
if user and safe_str_cmp(user.password.encode('utf-8'), password.encode('utf-8')):
return user
def identity(payload):
user_id = payload['identity']
return userid_table.get(user_id, None)
jwt = JWT(app, authenticate, identity)
class Books(Resource):
# decorators = [auth.login_required]
decorators=[jwt_required()]
def get(self):
return jsonify({'status':0,'msg':'ok','datas':books})
def post(self):
if not request.json:
return jsonify({'status':1001,'msg':'请求参数不是JSON的数据,请检查,谢谢!'})
else:
book = {
'id': books[-1]['id'] + 1,
'author': request.json.get('author'),
'name': request.json.get('name'),
'done': True
}
books.append(book)
return {'status':1002,'msg': '添加书籍成功','datas':book}
# return jsonify({'status':1002,'msg': '添加书籍成功','datas':book}, 201)
class Book(Resource):
# decorators = [auth.login_required]
decorators = [jwt_required()]
def get(self,book_id):
book = list(filter(lambda t: t['id'] == book_id, books))
if len(book) == 0:
return jsonify({'status': 1003, 'msg': '很抱歉,您查询的书的信息不存在'})
else:
return jsonify({'status': 0, 'msg': 'ok', 'datas': book})
def put(self,book_id):
book = list(filter(lambda t: t['id'] == book_id, books))
if len(book) == 0:
return jsonify({'status': 1003, 'msg': '很抱歉,您查询的书的信息不存在'})
elif not request.json:
return jsonify({'status': 1001, 'msg': '请求参数不是JSON的数据,请检查,谢谢!'})
elif 'author' not in request.json:
return jsonify({'status': 1004, 'msg': '请求参数author不能为空'})
elif 'name' not in request.json:
return jsonify({'status': 1005, 'msg': '请求参数name不能为空'})
elif 'done' not in request.json:
return jsonify({'status': 1006, 'msg': '请求参数done不能为空'})
elif type(request.json['done'])!=bool:
return jsonify({'status': 1007, 'msg': '请求参数done为bool类型'})
else:
book[0]['author'] = request.json.get('author', book[0]['author'])
book[0]['name'] = request.json.get('name', book[0]['name'])
book[0]['done'] = request.json.get('done', book[0]['done'])
return jsonify({'status': 1008, 'msg': '更新书的信息成功', 'datas': book})
def delete(self,book_id):
book = list(filter(lambda t: t['id'] == book_id, books))
if len(book) == 0:
return jsonify({'status': 1003, 'msg': '很抱歉,您查询的书的信息不存在'})
else:
books.remove(book[0])
return jsonify({'status': 1009, 'msg': '删除书籍成功'})
api.add_resource(Books,'/v1/api/books')
api.add_resource(Book,'/v1/api/book/<int:book_id>')
if __name__ == '__main__':
app.run(debug=True,port=5001)
比如这地方需要测试书籍的删除这么一个场景,那么它的前置业务场景就是添加,以及获取到它的ID,才能够到删除的步骤。我们需要清楚的执行,在编写的测试用例中,每个测试用例都需要
保持独立性,不要有任何的依赖性,这样也是为了自动化测试用例的维护性,以及可扩展性,但是业务场景就像我说的,它存在千丝万缕的关系,那么我们的测试用例难道真的需要写成按顺序执
行吗?当然是不可以的,因为按顺序执行,这样在设计上就违背了每个测试用例它的独立性而言,我们所测试的每个测试用例都是一个独立的属性,那么我们编写每个测试的场景,它的前置条件
我们都可以放在初始化的这部分,而作为前置的要求,我们尽可能的,或者更加具体的说我们要让编写的每个测试用例不管它有多少个前置条件,我们都要让每个测试用例保持独立性,除非前置
的业务场景存在产品上的bug,那么也就导致了该测试用例失败,这是不可避免的,我们只所以强调独立性是因为不想让代码的bug导致测试用例的失败,以及维护成本的提高,那么如上的测试用
例,我们可以写成如下的方式:
#!/usr/bin/python3
#coding:utf-8
import pytest
import requests
def writeBook(bookID):
with open('bookID','w') as f:
f.write(bookID)
def readBookID():
with open('bookID','r') as f:
return int(f.read())
def addBook():
dict1={"author":"无涯","name":"Python自动化测试实战","done":True}
r=requests.post(
url='http://127.0.0.1:5000/v1/api/books',
json=dict1)
writeBook(str(r.json()['datas']['id']))
return r
def queryBook():
r=requests.get(
url='http://127.0.0.1:5000/v1/api/book/{0}'.format(readBookID()))
return r
def setBook():
dict1 = {"author": "无涯课堂", "name": "Python自动化测试实战", "done": True}
r=requests.put(
url='http://127.0.0.1:5000/v1/api/book/{0}'.format(readBookID()),
json=dict1)
return r
def delBook():
r=requests.delete(
url='http://127.0.0.1:5000/v1/api/book/{0}'.format(readBookID()))
return r
def test_addBook():
'''创建书籍'''
r=addBook()
delBook()
assert r.json()['datas']['author']=='无涯'
def test_queryBook():
'''查看创建的书籍信息'''
addBook()
r=queryBook()
delBook()
assert r.json()['datas'][0]['id']==readBookID()
def test_updateBook():
'''修改书籍信息'''
addBook()
r=setBook()
delBook()
assert r.json()['datas'][0]['author']=='无涯课堂'
def test_delBook():
'''删除书籍信息'''
addBook()
r=delBook()
assert r.json()['status']==1001
关于API的测试用例编写规则以及注意事项,在我的文章API测试用例的编写有很详细的介绍,感兴趣的同学可以继续查看该文章的细节性的东西。
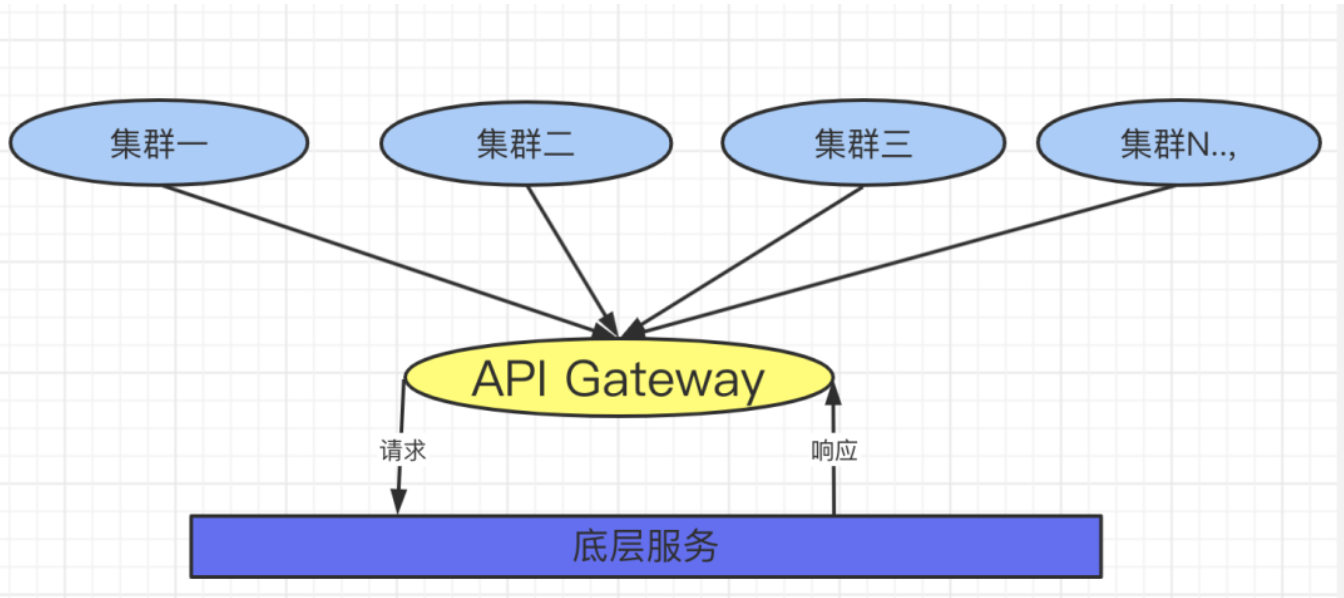
作为微服务的架构产品,它的难点首先需要面对的就是它的底层服务是共享的,所有的服务进程之间通过同步或者是异步通信的方式进行交互,在它的上层中部署了很多的集群,这
些集群的用户它都具备不同的用户数据,如下图所示:
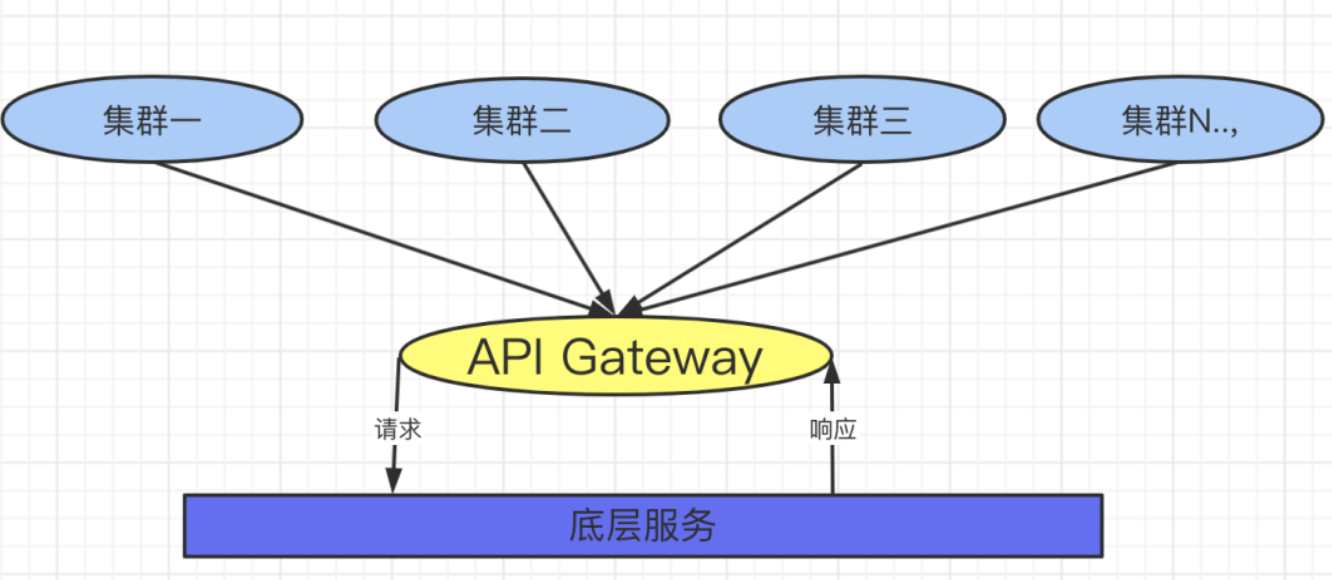
在这样的形态中,我们先不讨论它的调度策略,以及它的资源管理,服务自动注册与发现机制,它连接数的管理这些等等,我们首先遇到的问题就是当一个产品发布后,这些所有的集群都需要
被验证,这是一个现实的问题,第二个现实的问题就是会有多个不同的环境,比如QA,预发布环境,线上环境,那么自动化测试用例需要面对的就是针对这些不同的环境,是否写多套不同环境
的测试代码了?写多套在理论上是成立的,但是在思想是它违背了容易维护的原则,其实我们仔细的来思考,这些不同的环境,它的业务形态是一致的,这是它的共同点,它的不同点是不同环
境的测试数据是不同的,但是我们不能因为测试数据不同就多个环境写多套重复性的代码,这样在维护成本上首先会加大的,我们解决的思路是什么了?其实我们定义一个基准,根据这个基准,
我们来判断不同环境使用不同的测试数据,让它自动进行匹配选择数据,这样我们只需要针对不同环境执行我们的CASE,只需要修改基准的配置文件而已,当然这个基准的配置文件就是我们
的URL,如配置文件信息为:
urls:
qa: 'http://127.0.0.1:5000/'
line: 'http://127.0.0.1:5001/'
stage: 'http://127.0.0.1:5002/'
url: 'http://127.0.0.1:5001/'
然后我们编写函数来处理不同环境的URL,依据不同的URL来处理不同环境的测试数据,处理URL的函数为:
#!/usr/bin/env python
#!coding:utf-8
import yaml
def readYaml():
with open('config.yaml','r') as f:
return yaml.safe_load(f)
def isUrl():
'''依据url的信息来决定使用那个环境'''
if readYaml()['urls']['url']==readYaml()['urls']['qa']:
return readYaml()['urls']['qa']
elif readYaml()['urls']['url']==readYaml()['urls']['line']:
return readYaml()['urls']['line']
elif readYaml()['urls']['url']==readYaml()['urls']['stage']:
return readYaml()['urls']['stage']
依据URL来选择不同环境的测试数据,源码如下:
def readJson(qaFile='qa.json',stageFile='stage.json',lineFile='line.json'):
if isUrl()==readYaml()['urls']['qa']:
return json.load(open(qaFile,'r'))
elif isUrl()==readYaml()['urls']['stage']:
return json.load(open(stageFile,'r'))
elif isUrl()==readYaml()['urls']['line']:
return json.load(open(lineFile,'r'))
这样在执行层面,涉及到测试数据的部分,我们只调用readJson的函数,至于环境这个事,我们只备注基准的环境。这样就可以很轻松的实现了多个环境使用一套代码的事情。
上面我们说到多个环境的自动匹配以及不同环境下的测试数据自动适配和匹配,下面接着上面的思路继续来讲针对微服务架构的可持续的验证。了解以及熟悉微服务的同学应该清楚,在微
服务的架构中,底层服务是共享的,在它的上层应用中会有很多的应用层来进行部署,那么也就涉及到这些应用层都需要在每次发布版本后都需要进行自动化测试的回归测试验证,从而来保障
底层以及应用层的功能是正常的,满足交付的目标的。其实从理论的角度而言,既然底层的服务是共享的,那么即使在微服务上层中有很多的用户,我们是不是只需要验证一个用户就可以理解
为满足交付目标了?在理论的角度而言,这个结论是可以成立的,但是这只是一个理论的层面,在实践的层面其实并不是的,主要有这么几个点,我们抛开稳定性,高并发,高可用,以及异常,
队列,调度层面的,就单纯的说功能层面的测试,在上层的用户,它的数据都是有差异的,不同的数据差异也就导致了服务在处理不同数据时的逻辑判断和代码分支,这是一点,另外一点就是
服务是多实例的,如果单纯的一个用户验证,只能侧面验证这个用户对应的集群是好的,但是微服务上面会有很多的集群,一个集群符合期望目标并不代表其他集群也是符合目标的,不同的集
群它的数据引擎都是有差异的。那么就涉及到一个问题,我们如何编写一套代码,来实现验证不同集群不同用户的目标了?有同学可能会想到参数化的方式,其实参数化的方式在这样的场景中
只有固定我们的思维,从而在扩展性方面会限制我们的思路,因为不同集群不同用户是很随意的,这种随意就是可能某些时候所有集群都需要验证,可能某些时候只验证某一个集群,有的时候
需要验证一些活跃用户,有的时候需要验证一些特殊的用户,那么这地方这些用户就是系统部署的用户但是我们验证的时候不能写死,得根据不同场景的形态下自定义验证的用户,只要这个用
户是系统(部署)用户即可。这地方举一个简单的案例,比如一个登录的接口需要验证,但是它在不同集群,那么我登录这个用户只要是系统(部署)的用户,符合这个要求就可以了,我们可
以通过Pytesrt测试框架的addoption可以轻松的实现,也就是自定义命令行解释器,代码如下:
import pytest
def pytest_addoption(parser):
parser.addoption('--username',action='store',default='wuya',help='')
parser.addoption('--password',action='store',default='asd888',help='')
@pytest.fixture()
def username(request):
return request.config.getoption('--username')
@pytest.fixture()
def password(request):
return request.config.getoption('--password')
我们可以看到在这个代码中,我们并不清楚username和password是什么,我们只需要在实际验证的时候自定义指定存在的用户,如涉及到的测试代码如下
import requests
def test_ci_login(username,password):
dict1={'username':username,'password':password}
r=requests.post(
url='http://localhost:5000/auth',
json=dict1)
r.status_code=200
实际在CI里面我们结合流水线来演示这部分案例应用,涉及脚本命令为:
node{
stage("集群一")
{
sh'''
cd /Applications/code/Yun/saasMonitor/tests
python3 -m pytest -s -v test_ci_monitor.py --username=wuya --password=asd888
'''
}
stage("集群二")
{
sh'''
cd /Applications/code/Yun/saasMonitor/tests
python3 -m pytest -s -v test_ci_monitor.py --username=admin --password=asd888
'''
}
stage("集群三")
{
sh'''
cd /Applications/code/Yun/saasMonitor/tests
python3 -m pytest -s -v test_ci_monitor.py --username=share --password=asd888
'''
}
}
执行后就会显示如下所示:

当然针对微服务的架构以及不同的数据引擎,我们可以针对不同集群增加定时任务的监控,再出现问题后可以钉钉随时的通知我们,我们可以把钉钉整合进去,涉及代码如下:
import json
import requests
def getHeaders():
return {'Content-Type':'application/json ;charset=utf-8'}
def sendMsg():
''''''
url='https://oapi.dingtalk.com/robot/send?access_token=******'
msg='请检查服务'
dict1 = {
"msgtype": "text",
"text": {"content": msg},
"at": {"atMobiles": ["18294342805"],"isAtAll": 0}}
dict1=json.dumps(dict1)
r = requests.post(url, data=dict1, headers=getHeaders())
这样在测试点里面再把监控整合进去。我们就是一个体系,基于微服务架构的不同集群自定义的验证和自动化测试回归测试,以及定时任务定时扫描,出异常进行监控报警。
对服务而言,并发测试是常态,以及服务稳定性测试这些都是必然要考虑到的点,特别是某些服务都是有性能指标的,这些性能指标不是什么计算公式能够计算出来的,而应该是我们通
过不断的验证,依据得到的数据得到一个公式,来论证某个阶段中资源的计算能力,从而判断决策资源是否做弹升以及资源压缩,当然这里我们更多讨论的是性能测试的角度,主要围绕IO密
集型的角度而言,我们完全可以使用多线程的技术来实现,这样它的效率比较高,我们更加希望执行结束后能够快速的看到结果信息,必然中位数,成功率,错误率以及其他的信息,涉及代
码如下:
#!/usr/bin/env python
#!coding:utf-8
from flask import Flask,make_response,jsonify,abort,request
from flask_restful import Api,Resource
from flask import Flask
import requests
import time
import matplotlib.pyplot as plt
from threading import Thread
import datetime
import numpy as np
import json
import re
import hashlib
from urllib import parse
import datetime
app=Flask(__name__)
api=Api(app=app)
class OlapThread(Thread):
def __init__(self,func,args=()):
'''
:param func: 被测试的函数
:param args: 被测试的函数的返回值
'''
super(OlapThread,self).__init__()
self.func=func
self.args=args
def run(self) -> None:
self.result=self.func(*self.args)
def getResult(self):
try:
return self.result
except BaseException as e:
return e.args[0]
def targetURL(code,seconds,text,requestUrl):
'''
高并发请求目标服务器
:param code:
:param seconds:
:param text:
:param requestUrl: 请求地址
:return:
'''
r=requests.get(url=requestUrl)
print('输出信息昨状态码:{0},响应结果:{1}'.format(r.status_code,r.text))
code=r.status_code
seconds=r.elapsed.total_seconds()
text=r.text
return code,seconds,text
def calculationTime(startTime,endTime):
'''计算两个时间之差,单位是秒'''
return (endTime-startTime).seconds
def getResult(seconds):
'''获取服务端的响应时间信息'''
data={
'Max':sorted(seconds)[-1],
'Min':sorted(seconds)[0],
'Median':np.median(seconds),
'99%Line':np.percentile(seconds,99),
'95%Line':np.percentile(seconds,95),
'90%Line':np.percentile(seconds,90)
}
return data
def show(i,j):
'''
:param i: 请求总数
:param j: 请求响应时间列表
:return:
'''
fig,ax=plt.subplots()
ax.plot(list_count,seconds)
ax.set(xlabel='number of times', ylabel='Request time-consuming',
title='olap continuous request response time (seconds)')
ax.grid()
fig.savefig('target.png')
plt.show()
def highConcurrent(count,requestUrl):
'''
对服务端发送高并发的请求
:param count: 并发数
:param requestData:请求参数
:param requestUrl: 请求地址
:return:
'''
startTime=datetime.datetime.now()
sum=0
list_count=list()
tasks=list()
results = list()
#失败的信息
fails=[]
#成功任务数
success=[]
codes = list()
seconds = list()
texts=[]
for i in range(0,count):
t=OlapThread(targetURL,args=(i,i,i,requestUrl))
tasks.append(t)
t.start()
print('测试中:{0}'.format(i))
for t in tasks:
t.join()
if t.getResult()[0]!=200:
fails.append(t.getResult())
results.append(t.getResult())
for item in fails:
print('请求失败的信息:
',item[2])
endTime=datetime.datetime.now()
for item in results:
codes.append(item[0])
seconds.append(item[1])
texts.append(item[2])
for i in range(len(codes)):
list_count.append(i)
#生成可视化的趋势图
fig,ax=plt.subplots()
ax.plot(list_count,seconds)
ax.set(xlabel='number of times', ylabel='Request time-consuming',
title='taobao continuous request response time (seconds)')
ax.grid()
fig.savefig('target.png')
plt.show()
for i in seconds:
sum+=i
rate=sum/len(list_count)
# print('
总共持续时间:
',endTime-startTime)
totalTime=calculationTime(startTime=startTime,endTime=endTime)
if totalTime<1:
totalTime=1
#吞吐量的计算
try:
throughput=int(len(list_count)/totalTime)
except Exception as e:
print(e.args[0])
getResult(seconds=seconds)
errorRate=0
if len(fails)==0:
errorRate=0.00
else:
errorRate=len(fails)/len(tasks)*100
throughput=str(throughput)+'/S'
timeData=getResult(seconds=seconds)
# print('总耗时时间:',(endTime-startTime))
timeConsuming=(endTime-startTime)
return timeConsuming,throughput,rate,timeData,errorRate,len(list_count),len(fails)
class Index(Resource):
def get(self):
return {'status':0,'msg':'ok','datas':[]}
def post(self):
if not request.json:
return jsonify({'status':1001,'msg':'请求参数不是JSON的数据,请检查,谢谢!'})
else:
try:
data={
'count':request.json.get('count'),
'requestUrl':request.json.get('requestUrl')
}
timeConsuming,throughput,rate,timeData,errorRate,sum,fails=highConcurrent(
count=data['count'],
requestUrl=data['requestUrl'])
print('执行总耗时:',timeConsuming)
return jsonify({'status':0,'msg': '请求成功','datas':[{
'吞吐量':throughput,
'平均响应时间':rate,
'响应时间信息':timeData,
'错误率':errorRate,
'请求总数':sum,
'失败数':fails
}]}, 200)
except Exception as e:
return e.args[0]
api.add_resource(Index,'/v1/index')
if __name__ == '__main__':
app.run(debug=True,port=5003,host='0.0.0.0')
我们启动该服务,在postman里面测试验证下,如下显示postman里面的请求信息:
请求后得到的结果信息如下所示:
[
{
"datas": [
{
"吞吐量": "125/S",
"响应时间信息": {
"90%Line": 0.21584840000000002,
"95%Line": 0.23521154999999996,
"99%Line": 0.2866666799999997,
"Max": 0.334945,
"Median": 0.162997,
"Min": 0.124598
},
"失败数": 0,
"平均响应时间": 0.172092518,
"请求总数": 500,
"错误率": 0.0
}
],
"msg": "请求成功",
"status": 0
},
200
]
执行成功后,也会显示出可视化的趋势图,如下所示:

服务端测试其实是一个比较庞大的知识体系,它涉及协议,也涉及服务内部的实现以及架构,我们对它的测试不能单纯的在功能方面考虑,比如说之前说的调度,那么就涉及到线程的优先级
的东西,但是对于一个依赖的任务执行顺序而言,仅仅是优先级是不能解决的,任务的冲突执行必然导致数据的混乱,也就会出现疯狂的打印日志信息等。另外一点,特别是涉及服务底层的稳定
性的测试,需要考虑很多的因素,这些因素一方面是产品方面的,另外一方面是服务本身的,产品方面主要需要思考的是服务与产品之间的关系,服务是服务产品的,但是不能完全按照服务产品
来进行设计,这样在扩展性方面就存在很多的局限,那么也就在测试的时候,如果我们看不到这点,可能就会抱怨开发同学。我一直认为底层服务与上层应用之间的关系是若即若离的,不能完全
搞到一起,那样在后续发展中会存在很大的局限。当然在本文章中,我们介绍到了它的功能层次的测试,稳定性方面的测试,其实这些还远远不够,后续我们再仔细的来看服务内部的交互体系,
在这些体系中,我们的测试解决方案思路是什么,什么样的思维能够找出这些隐藏的bug但是它又是影响很大的问题。当然,在下一个文章中,我会详细的介绍下Python测试技术栈中API框架的
设计,以及我们需要的简约模式。其实这些在很早的文章中有介绍,本次给它更加系统化的来看每个思路以及它的优点和缺点。
