伪LRU英文全名为Pseudo-LRU (PLRU),本概念略难懂,单独解决。
For CPU caches with large associativity (generally >4 ways), the implementation cost of LRU becomes prohibitive. In many CPU caches, a scheme that almost always discards one of the least recently used items is sufficient. So many CPU designers choose a PLRU algorithm which only needs one bit per cache item to work.
PLRU typically has a slightly worse miss ratio, has a slightly better latency, and uses slightly less power than LRU.
并行多核体系结构基础一书给出的概念:
一种可能的近似LRU的方法是记录最近最常访问的一部分数据块,当需要替换时, 那些未被记录的数据块通过随机或者特定的算法被替换出高速缓存。这种方法的一个最简单的例子就是记录最近最常使用(Most Recently Used, MRU)的数据块,当需要替换时,通过伪随机算法选择非MRU的数据块替换出高速缓存。
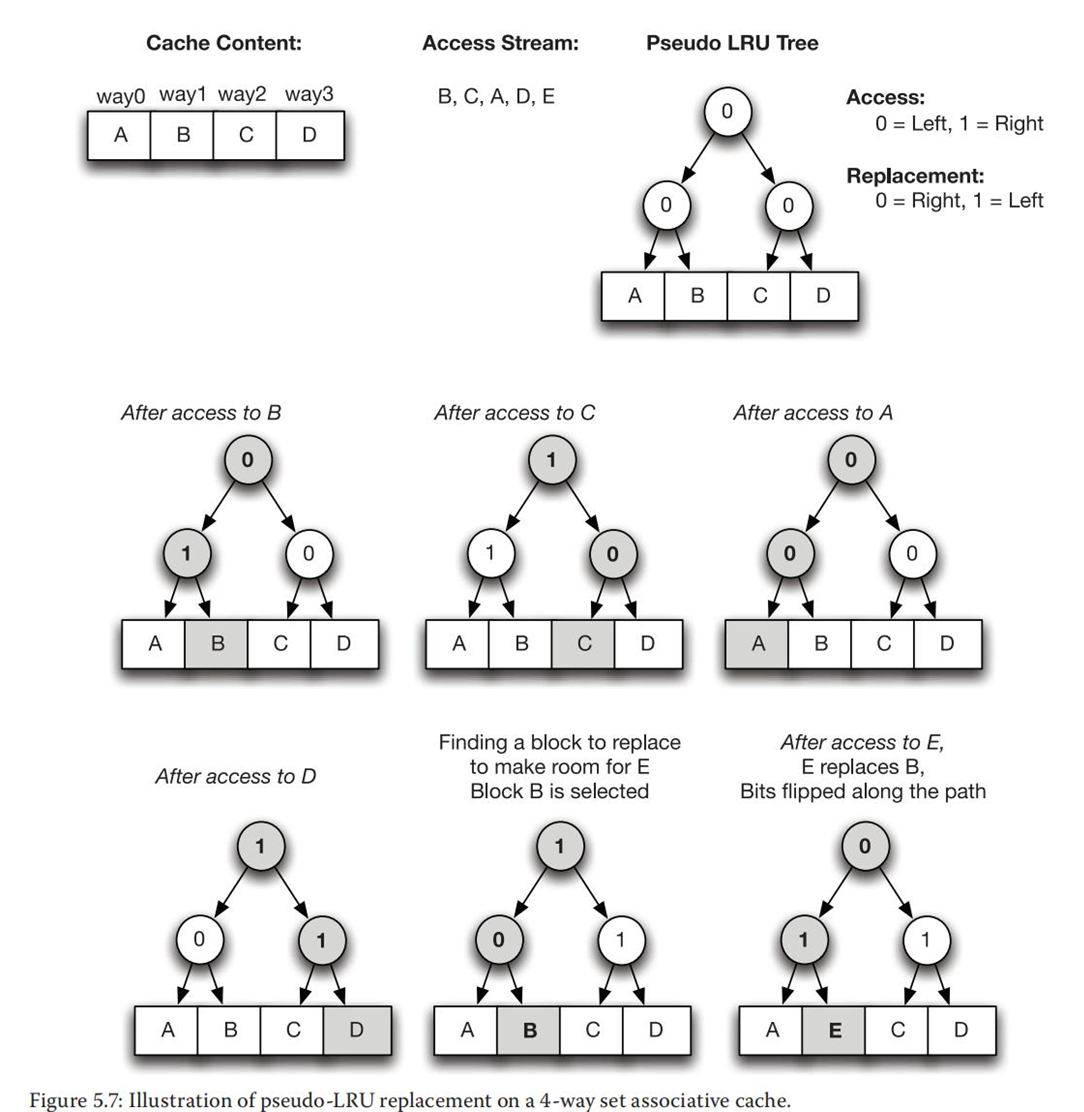
下图中展示的基于树的伪LRU替换策略:
笔者翻阅资料,找到一个非常nice的解释文章,参考于:Cache replacement policies(缓存替换策略)
该算法的工作方式如下:考虑一个二叉搜索树(BST)为所讨论的项目。树的每个节点具有一位标志,该标志指示“向左查找伪LRU元素”或“向右查找伪LRU元素”。要查找伪LRU元素,请根据标志的值遍历树。要使用对项N的访问来更新树,请遍历树以找到N,并在遍历期间将节点标志设置为表示与所取方向相反的方向。
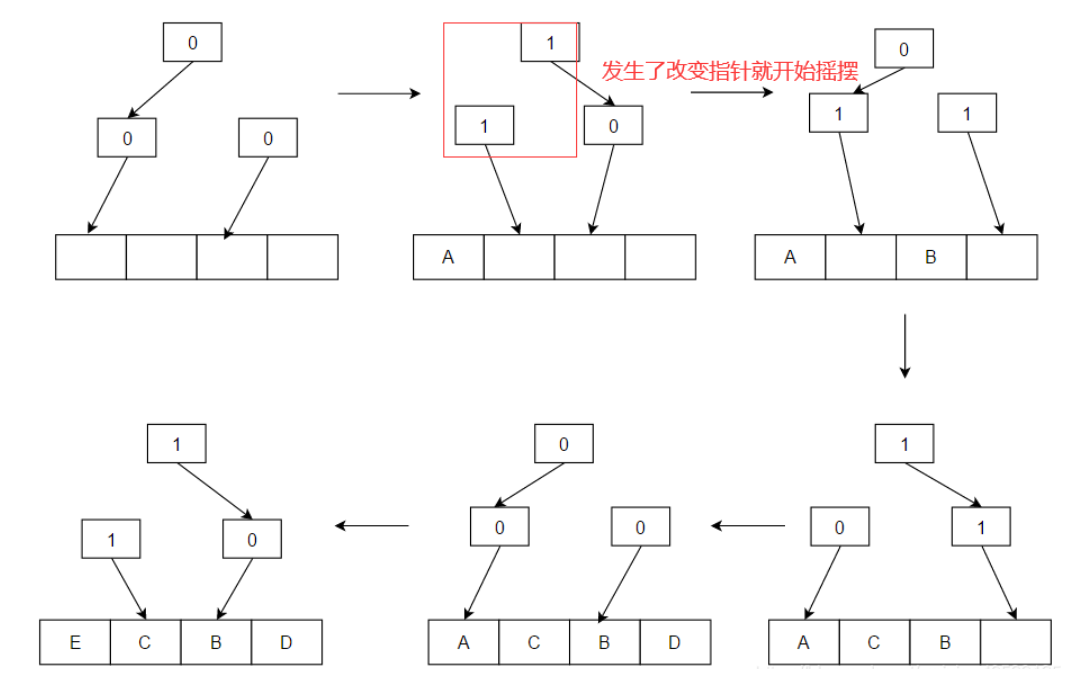
访问顺序为ABCDE。如果只看箭头,这里的原理很容易理解。当可以访问值时,说A,我们无法在缓存中找到它,然后从内存中加载它,并将其放置在箭头所指的块上,从上到下,并在放置该块时使箭头指向远离该块的底部和顶部。在上面的示例中,我们看到如何放置A,然后放置B,C和D.然后,当缓存已满时,E替换为A,因为那是箭头所指的时间。下次访问时,将替换保存B的块。
该算法可能是次优的,因为它是近似值。例如,在上图中具有A,C,B,D缓存行的情况下,如果访问模式为:C,B,D,A则在逐出时我们选择B而不是C。这是因为A和C在同一部分,访问A会将算法定向到不包含高速缓存行C的另一部分。