对于span标签。
content = node.xpath('.//div[@class="content"]/span')[0].text
这样的话,只能取到第一段的内容。
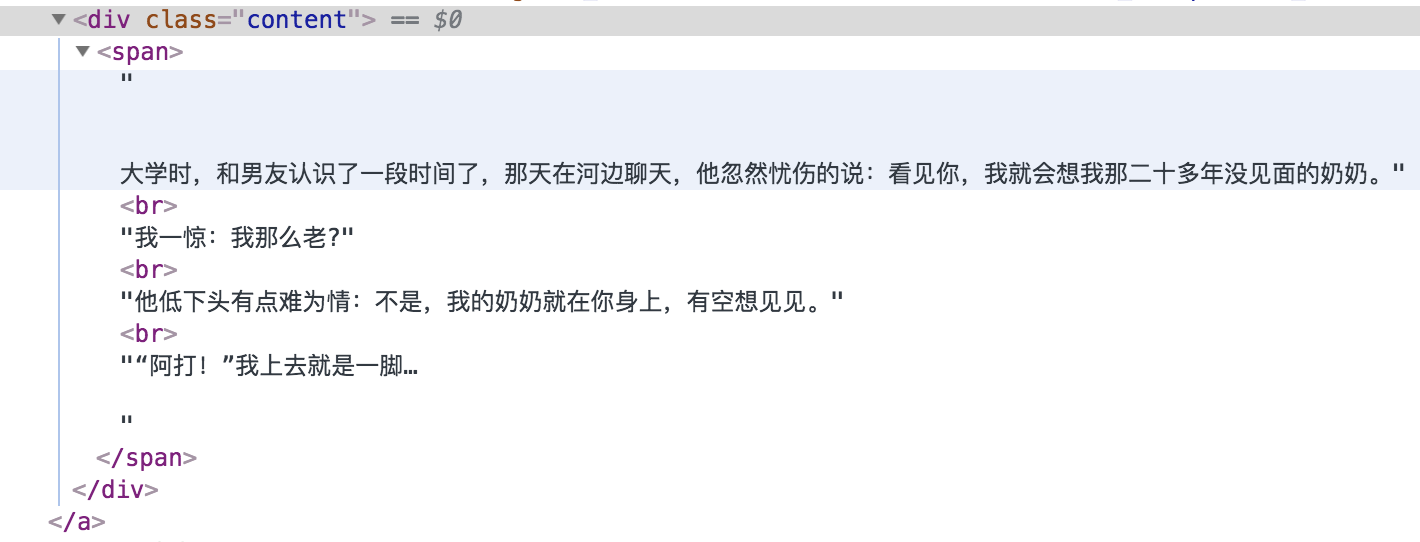
item["content"] = [i.strip() for i in div.xpath(".//div[@class='content']/span/text()")]
完整代码
1 # coding=utf-8 2 import requests 3 from lxml import etree 4 import time 5 6 class QiuBai: 7 def __init__(self): 8 self.temp_url = "http://www.qiushibaike.com/8hr/page/{}" 9 self.headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36"} 10 11 def get_url_list(self): 12 '''准备url地址的刘表''' 13 return [self.temp_url.format(i) for i in range(1,14)] 14 15 def parse_url(self,url): 16 '''发送请求,获取响应''' 17 response = requests.get(url,headers=self.headers) 18 return response.content.decode() 19 20 def get_content_list(self,html_str): 21 '''提取数据''' 22 html = etree.HTML(html_str) 23 div_list = html.xpath("//div[@id='content-left']/div") 24 content_list = [] 25 for div in div_list: 26 item = {} 27 item["user_name"] = div.xpath(".//h2/text()")[0].strip() 28 item["content"] = [i.strip() for i in div.xpath(".//div[@class='content']/span/text()")] 29 content_list.append(item) 30 return content_list 31 32 def save_content_list(self,content_list): 33 '''保存''' 34 for content in content_list: 35 print(content) 36 37 def run(self):#实现做主要逻辑 38 #1. 准备url列表 39 url_list = self.get_url_list() 40 #2. 遍历发送请求,获取响应 41 for url in url_list: 42 html_str = self.parse_url(url) 43 #3. 提取数据 44 content_list = self.get_content_list(html_str) 45 #4. 保存 46 self.save_content_list(content_list) 47 48 49 if __name__ == '__main__': 50 t1 = time.time() 51 qiubai = QiuBai() 52 qiubai.run() 53 print("total cost:",time.time()-t1)