一:前言
一个服务上线了后,你想知道这个服务是否可用,需要监控。假如线上出故障了,你要先于顾客感知错误,你需要监控。还有对数据库,服务器的监控,等等各层面的监控。
近年来,微服务架构的流行,服务数越来越多,监控指标变得越来越多,所以监控也变得越来越复杂,需要新的监控系统适应这种变化。
以前我们用zabbix,StatsD监控,但是随着容器化,微服务的流行,我们需要新的监控系统来适应这种变化。于是监控项目Prometheus就应运而生。
二:Prometheus介绍
介绍
-
网站地址:https://prometheus.io/
https://prometheus.io/docs/introduction/overview/
https://github.com/prometheus/docs -
github:github.com/prometheus
Prometheus是一款基于时序数据库的开源监控告警系统,它是SoundCloud公司开源的,SoundCloud的服务架构是微服务架构,他们开发了很多微服务,由于服务太多,传统的监控已经无法满足它的监控需求,于是他们在2012就着手开发新的监控系统。Prometheus的原作者Matt T. Proud在2012年加入SoundCloud公司,他之前服务于Google公司,他从google的监控系统Borgmon中获取灵感,与另外一名工程师Julius Volz合作开发了开源监控系统Prometheus。(总之感觉是因为有了这个前google工程师到来,才有能力开发了Prometheus)。后来其他开发人员陆续加入了这个项目,并在 SoundCloud 内部继续开发,最终于 2015 年 1 月将其发布。后来在2016年,SoundCloud把它捐献给了云原生基金会(Cloud Native Computing Foundation),在它下面继续孵化。
Prometheus是用go语言开发。它的很多理念跟google的SRE不谋而合。所以有时间,可以去看看google SRE那本书,可以更好的理解Prometheus。
主要特性(功能)
- 多维数据模型(时序由 metric 名字和 k/v 的labels构成)
- 灵活的查询语言(PromQL)
- 无依赖的分布式存储;单节点服务器都是自治的
- 采用 http 协议,使用pull模式拉取数据,简单易懂
- 监控目标,可以采用服务发现和静态配置方式
- 支持多种统计数据模型和界面展示。可以和Grafana结合展示。
三:Prometheus架构原理
架构
来自官方的一张架构图
主要模块:
- the main Prometheus Server,主要用于抓取数据和存储时序数据,另外还提供查询和 Alert Rule 配置管理。就是数据的采集和存储,用PromQL查询,报警配置。
- client libraries,用于对接Prometheus Server,用于对接Prometheus Server,可以查询和上报数据。
- a push gateway,用于批量,短期的监控数据的汇报总节点,主要用于业务数据汇报等。
- 各种汇报数据的 exporters,例如汇报机器数据的node_exporter,汇报MondogDB信息的 MongoDB_exporter 等等。
- 用于高级通知管理的 alertmanager 。
- 各种各样的支持工具
怎么采集监控数据
要采集目标的监控数据,首先就要在被采集目标地方安装采集组件,这种采集组件被称为Exporter。prometheus.io官网上有很多这种exporter,官方 exporter列表。
采集完了怎么传输到Prometheus?
采集了数据,要传输给prometheus。怎么做?
Exporter 会暴露一个HTTP接口,prometheus通过Pull模式的方式来拉取数据,会通过HTTP协议周期性抓取被监控的组件数据。
不过prometheus也提供了一种方式来支持Push模式,你可以将数据推送到Push Gateway,prometheus通过pull的方式从Push Gateway获取数据。
主要流程
- Prometheus server定期从静态配置的 targets 或者服务发现的 targets 拉取数据(zookeeper,consul,DNS SRV Lookup等方式)
- 当新拉取的数据大于配置内存缓存区的时候,Prometheus会将数据持久化到磁盘,也可以远程持久化到云端。
- Prometheus通过PromQL、API、Console和其他可视化组件展示数据。Prometheus支持很多方式图表可视化,比如Grafana,自带的Promdash。它还提供HTTP API的查询方式,自定义输出。
- Prometheus 可以配置rules,然后定时查询数据,当条件触发的时候,会将alert推送到配置的Alertmanager。
- Alertmanager收到告警的时候,会根据配置,聚合,去重,降噪,最后发出警告。
四:安装Prometheus
要整好prometheus监控系统,还是有很多软件需要安装。
安装的主要组件如下:
- Prometheus Server
- 被监控对象exporter组件
- 数据可视化工具 Grafana
- 数据上报网关 push gateway
- 告警系统 Alertmanager
第1种:直接安装
解压:
tar xvfz prometheus-2.19.2.linux-amd64.tar.gz
运行启动:
cd ./prometheus-2.19.2.linux-amd64
./prometheus --version
./prometheus --config.file=prometheus.yml &
第2种:docker镜像安装(不推荐,详情请百度)
查看web界面
在浏览器上输入 http://192.168.184.128:9090/ , 如果显示下面的web界面,说明promethdus启动成功:
五:Exporter采集监控信息
前面已经讲过,如果要监控服务器或者应用程序的各种信息,比如cpu、内存、网卡流量等等。就要在监控目标上安装指标收集程序,并暴露HTTP接口供Prometheus拉取数据,这个指标收集程序就是Exporter。不同的指标需要不同的Exporter收集。
这种Exporter需要自己写吗?
一般不需要,官网上已经有大量的Exporter,上面我们已经列出过官网的Exporter清单 地址。
而且有的软件已经集成了Prometheus的Exporter,也就是说软件本身就提供了Prometheus需要的各种指标数据。最典型的就是k8s,他们是云原生基金会的第一和第二个项目。
如果需要特殊的监控,可能就要你自己写Exporter了。
实例: node-exporter监控服务器
上面prometheus已经安装好了,现在来安装一个Exporter监控实例。
来安装一个监控服务器主机cpu、内存和磁盘等信息的exporter,直接用node-exporter。它主要用于收集类 UNIX 系统的信息。
步骤:
1.先修改prometheus.yml信息,
global:
scrape_interval: 15s
external_labels:
monitor: 'first-monitor'
scrape_configs:
- job_name: prometheus
scrape_interval: 5s
static_configs:
- targets: ['127.0.0.1:9090']
- targets: ['127.0.0.1:9100'] # 这里开始增加的监控信息
labels:
group: 'local-node-exporter'
2.安装并启动node-exporter:
进入官网下载:https://prometheus.io/download/

解压后执行下面命令:
systemctl daemon-reload
systemctl start node_exporter
systemctl restart node_exporter
3.先用ps -ef | grep prometheus查出端口号,kill -9 杀掉,然后重启prometheus:./prometheus --config.file=prometheus.yml & 。然后在浏览器上直接输入: http://192.168.184.128:9090/targets。或者,你在界面上点击 Status 菜单 -> Targets 菜单,来浏览metrics信息。
浏览器输出的web界面如下:
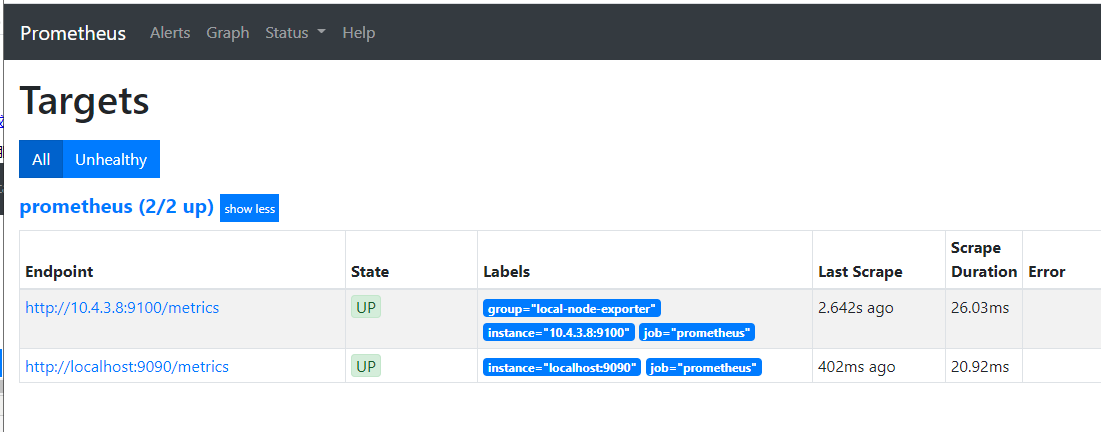
可以看到里面有一个 9100 端口的 metrics 连接,点进去后,就可以看到一些采集信息。
说明刚才配置的node-exporter已经加入到prometheus的targets中了。如下图:
查看监控信息
点击web界面最上面的菜单 Graph
选择下面的 Graph,然后我们选择一个 node_memory_Active_bytes 来看一看,
然后点击 Execute 按钮 , 就会出来如下图所示图形: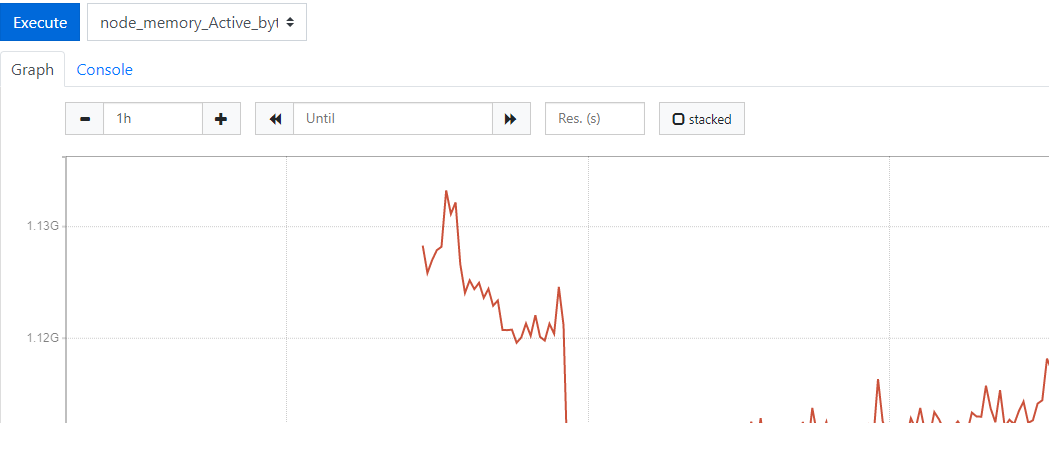
六:可视化系统:Grafana
上面我们通过Prometheus自带的UI,查看不同指标视图,但是它的功能很简单。如果需要强大的展示系统,能定制不同指标的面板,支持不同类型的展示方式,如曲线图、热点图,TopN等,那么grafana比较合适。它可以对promethdus数据进行可视化的展示。
grafana是一个大型可视化系统,功能强大,可以创建自己的自定义面板,支持多种数据来源,
比如:OpenTSDB、Elasticsearch、Prometheus 等,可以到官网去查看支持的数据源种类,而且它插件也很多。
安装
官网安装文档,它有不同平台安装的Doc。
我选择比较简单的一种,命令如下:
wget https://dl.grafana.com/oss/release/grafana-8.0.6-1.x86_64.rpm
sudo yum install grafana-8.0.6-1.x86_64.rpm
然后启动:
sudo systemctl daemon-reload
sudo systemctl start grafana-server
sudo systemctl status grafana-server
sudo systemctl enable grafana-server
我们在浏览器上看看界面,输入下面地址:
http://192.168.184.128:3000/login
然后输入初始密码 admin/admin 登录进入。
grafana设置
增加prometheus数据源并展示
1.点击如下图的Data Source:
2.点击 Add data source 按钮后,出来下面界面:
3.鼠标移到 Prometheus 上,点击 Select 按钮:
4.prometheus相关设置: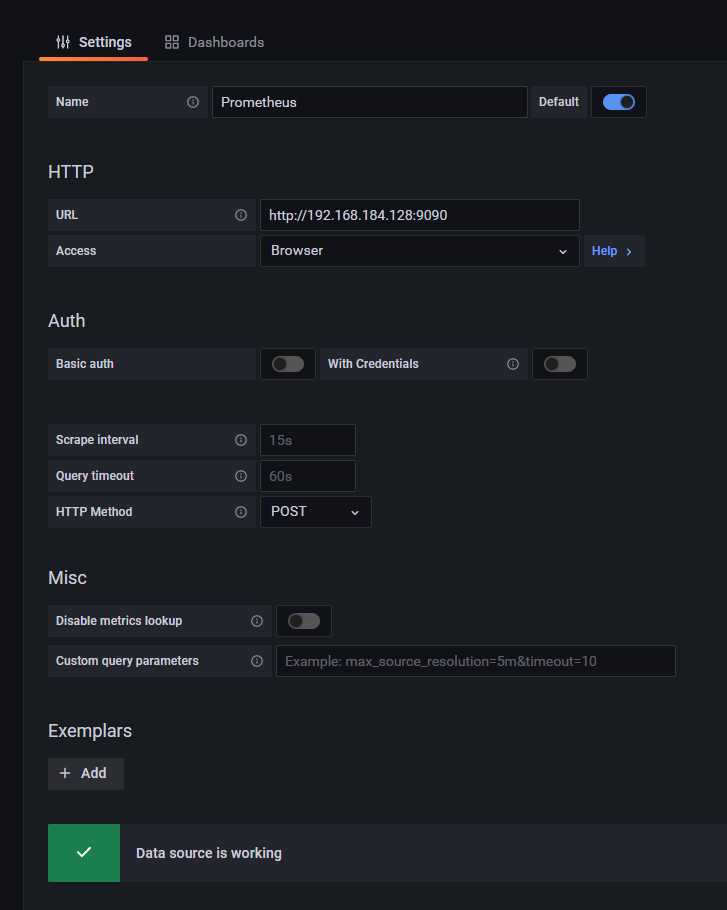
最主要设置获取数据的HTTP URL。
5.点击 save&test 按钮,它会提示你是否设置成功。
6.设置Dashboards
7.回到home
8:点击 prometheus
9:出来很多图表展示
其他dashboard模板设置
grafana不仅有我们上面设置的那些图表模板,它还有其他很多模板,我们也可以设置。
官方模板dashboard 地址。
比如我们查找node exportet的模板,https://grafana.com/grafana/dashboards?search=node%20exporter,有一个模板 downloads 比较多,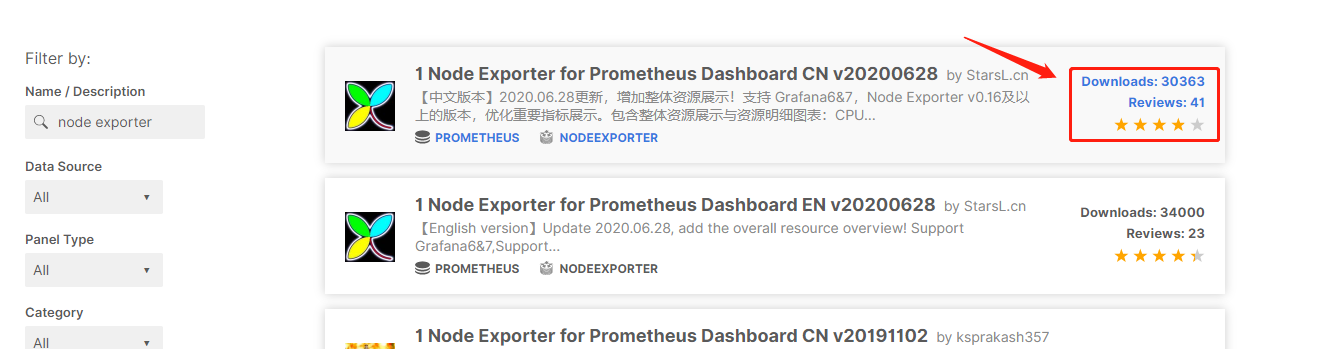
它的地址为:
https://grafana.com/grafana/dashboards/8919
我们在grafana上来设置这个dashboard,import进来:
可以填写id和url,我们填写id,为 8919: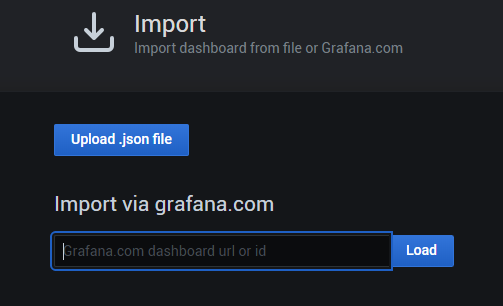
点击 load 出来下面界面:
然后选择prometheus-1,点击 import, 出来如下图的界面:
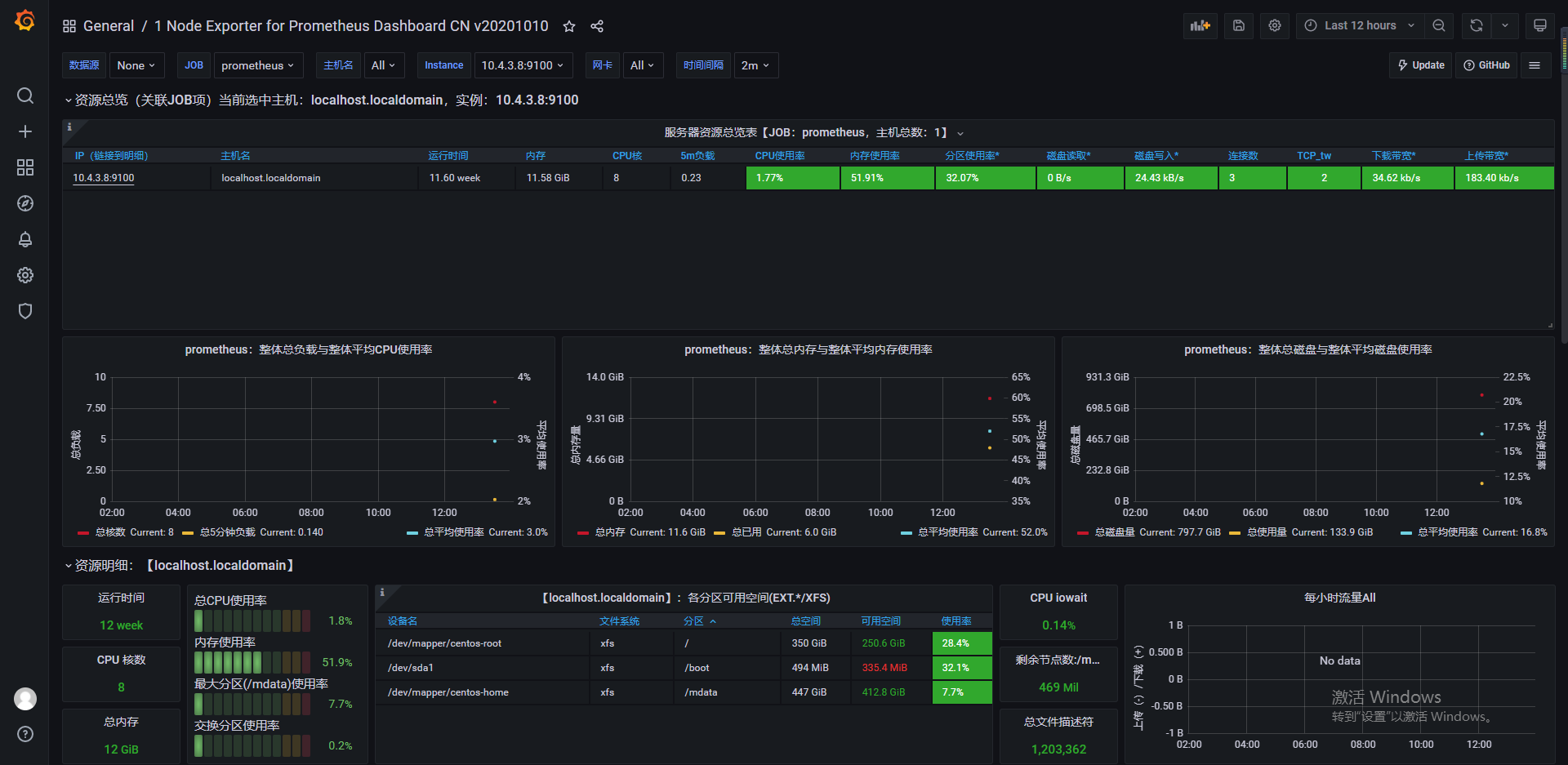
七、告警通知
我们已经能够对收集的数据,通过grafana展示出来了,能查看数据。想一想,系统还缺失什么功能?
监控最重要的目的是什么?
- 第一:监控系统是否正常
- 第二:系统不正常时,可以告知相关人员及时的排查和解除问题,这就是告警通知。
所以,还缺一个告警通知的模块。
prometheus的告警机制由2部分组成:
- 告警规则
prometheus会根据告警规则rule_files,将告警发送给Alertmanager - 管理告警和通知
模块是Alertmanager。它负责管理告警,去除重复的数据,告警通知。通知方式有很多如Email、HipChat、Slack、WebHook等等。
配置
1.告警规则配置
告警文档地址:告警规则官方文档。
我们新创建一个规则文件:alert_rules.yml,把它和prometheus.yml放在一起,官方有一个模板 Templating,直接copy过来:
groups:
- name: example
rules:
# Alert for any instance that is unreachable for >5 minutes.
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
# Alert for any instance that has a median request latency >1s.
- alert: APIHighRequestLatency
expr: api_http_request_latencies_second{quantile="0.5"} > 1
for: 10m
annotations:
summary: "High request latency on {{ $labels.instance }}"
description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"
上面规则文件大意:就是创建了2条alert规则 alert: InstanceDown 和 alert: APIHighRequestLatency :
- InstanceDown 就是实例宕机(up==0)触发告警,5分钟后告警(for: 5m);
- APIHighRequestLatency 表示有一半的 API 请求延迟大于 1s 时(api_http_request_latencies_second{quantile="0.5"} > 1)触发告警
更多rules规则说明,请看这里 recording_rules。
然后把alrt_rules.yml添加到prometheus.yml 里: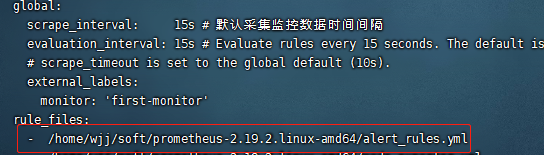
然后在浏览器上查看,rules是否添加成功,在浏览器上输入地址 http://192.168.184.128:9090/rules
也可以查看alers情况,点击菜单 Alerts: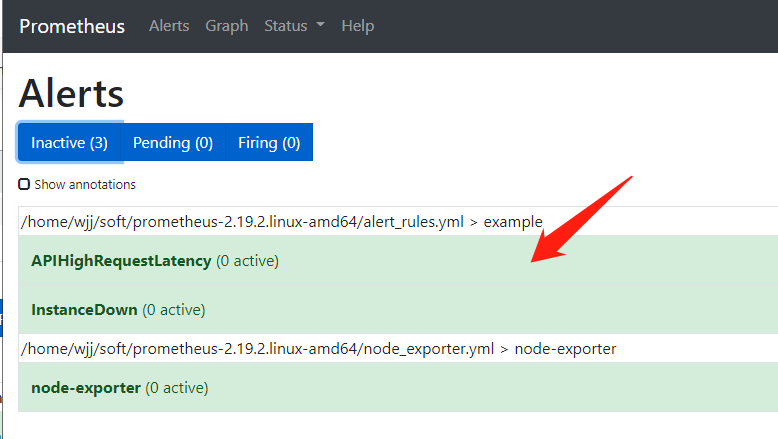

告警通知配置
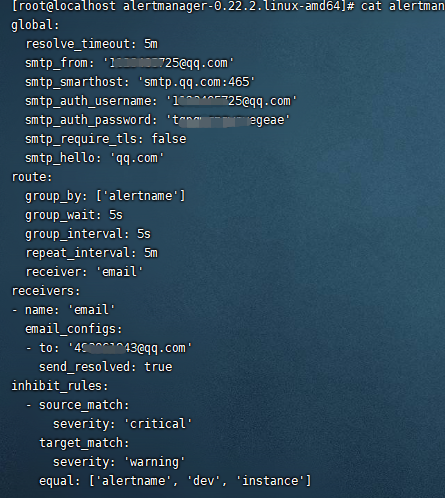
在上面我们可以看到alerts页面的告警信息,但是怎么通知到研发和业务相关人员呢?这里以QQ邮箱为例,这个就是由Alertmanager完成,先配置alertmanager文件 alertmanager.yml,
global:
resolve_timeout: 5m
smtp_from: 'xxxxxxxx@qq.com'
smtp_smarthost: 'smtp.qq.com:465'
smtp_auth_username: 'xxxxxxxx@qq.com'
smtp_auth_password: 'xxxxxxxxxxxxxxx'
smtp_require_tls: false
smtp_hello: 'qq.com'
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: 'xxxxxxxx@qq.com'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
启动alertmanager服务:
./alertmanager --config.file=alertmanager.yml &
在浏览器上输入 : http://192.168.184.128:9093,出现下面界面:
prometheus配置:
在promethdus加上下面的配置,
alerting:
alertmanagers:
- static_configs:
- targets: ['127.0.0.1:9093']
重启prometheus。
最后一步,测试告警发邮件。
之前配置了9100端口的报警信息,这个端口是node_exporter默认端口(node_exporter所在服务器ip这里我实际改为了:10.4.3.8)

现在停止node-exporter,执行命令:systemctl stop node-exporter,过一会儿就能收到报警邮件

再重新启动:systemctl start node-exporter,又会收到邮件 
大功告成!