import numpy as np import pandas as pd from sklearn.neighbors import KNeighborsClassifier # 导入knn学习包
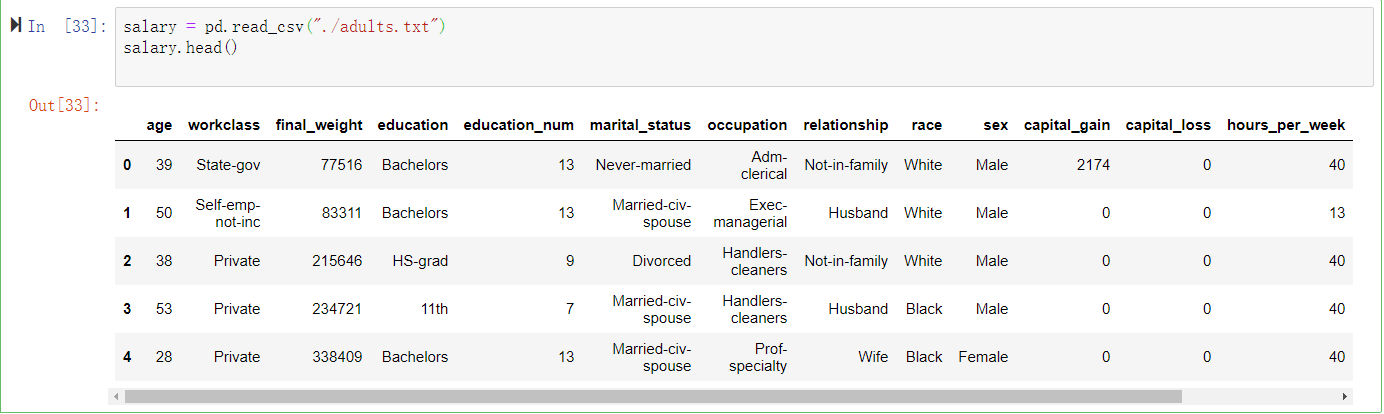
salary = pd.read_csv("./adults.txt") salary.head()
#样本数据的提取
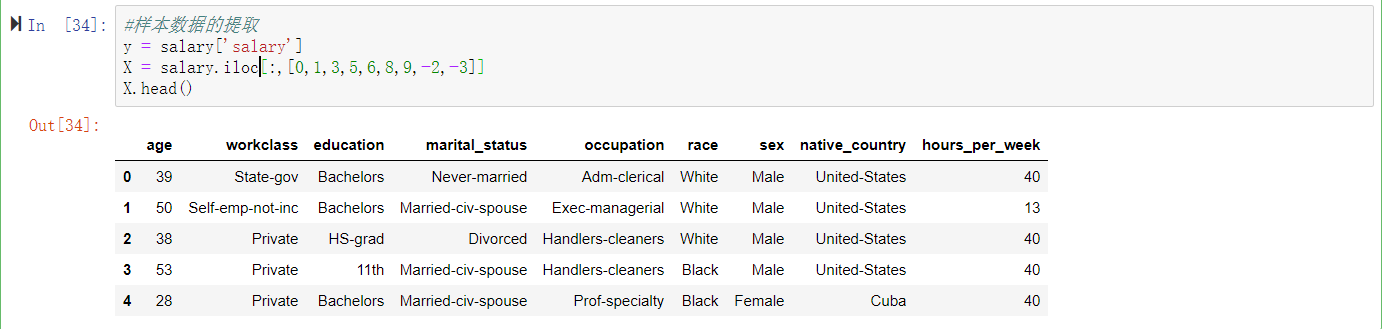
y = salary['salary']
X = salary.iloc[:,[0,1,3,5,6,8,9,-2,-3]]
X.head()
# 数据去重 用于下面函数的理解
u = X['occupation'].unique()
u

# np.argwhere此方法找到对应名称的索引 np.argwhere(u == "Exec-managerial")[0,0] # np.argwhere
X.columns[2:-1]

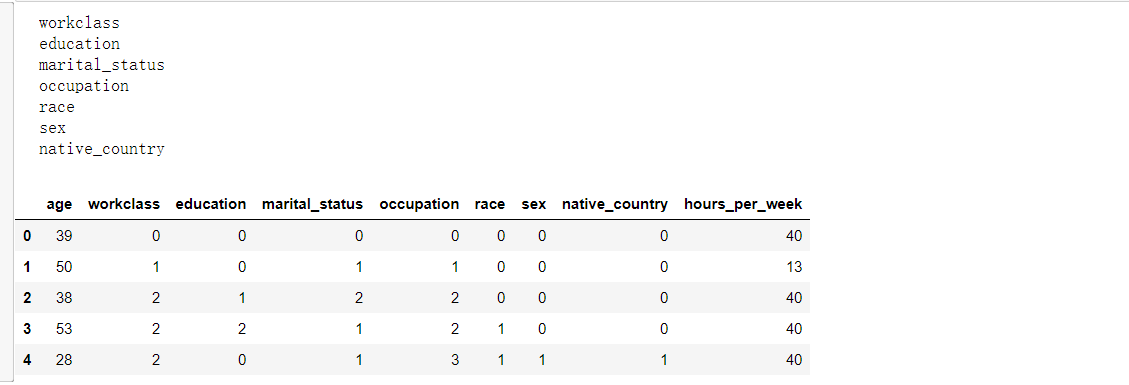
# 2:-1列的所有数据映射 for col in X.columns[1:-1]: # 遍历所有类名 u = X[col].unique() # 类似上面的u = X['occupation'].unique() 得出每个分类下面的种类名称 # print(col) def convert(x): # 将上面得出的u 进行索引映射 # print(x) return np.argwhere(u == x)[0,0] # 将上面得出的u 进行索引映射 X[col] = X[col].map(convert) # 将上面得出的u 进行索引映射 X.head()
# 切分训练集跟测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2) # 切分
print(X_train.shape,X_test.shape,y_train.shape,y_test.shape)
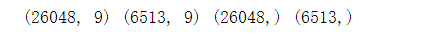
# 预测测试
knn = KNeighborsClassifier(n_neighbors=8)
knn.fit(X_train,y_train) # 计算公式
y_ = knn.predict(X_test) # 预测值
from sklearn.metrics import accuracy_score # 计算分类预测的准确率
# 求出预测准确率
accuracy = accuracy_score(y_test, y_)
print("预测准确率: ", accuracy)

总结:难度在于数据的预处理