VS版本VS2015 opencv版本3.4.1
简单介绍流程:
opencv自带有ANN-MLP(神经网络--多层感知器)的模块,该模块在我们编写训练程序时提供很大的帮助
首先简单介绍多层感知机构的概念
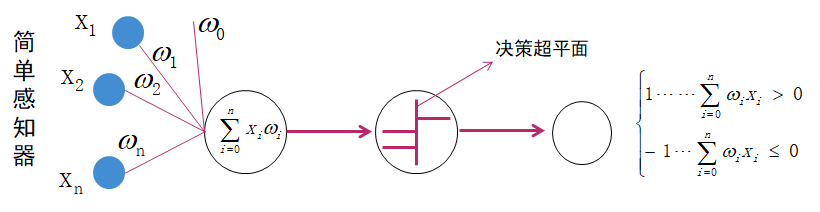
上图为一个简单的感知器,其中X1,X2....Xn为图像的基本特征,W1,W2....Wn代表每个特征的权重,对所有特征进行简单的线性求和可以得到一个函数输出结果,通过决策超平面进行逻辑判断,可以对函数结果进行分类,大于0的分为一类,小于0的分为另一类。
如果把上图的X1-Xn表示为数字1的特征,那么另一张数字1通过相同的权重求后通过决策面后的结果不一定是1,也就是说第二张1的分类是错误的,所以,第二张图片输入时需要对每个特征的权重进行调整,调整后可以使得分类正确;这也就是我们说的样本训练,样本训练的目的就是为了调整所有特征的权重值,直到训练出来的一套权重值可以满足所有的样本分类。那么可以预知样本越多,训练出来的权重参数的适用性也就越广。
不过存在另一个问题是现实的情况不可能是简单的将特征加权求和,要分类的结果也远远不止两类,所以简单的神经感知结构就不适用了,需要引入激活函数的概念,激活函数有几种固定的类型,常用的是S型激活函数sigmoid,激活的特征是可对所有的权重求导,若将(实际输出-期望输出)作为每次训练后的误差函数(误差肯定越小越好),那么将该误差函数对所有权重求导可以得到误差与每一个权重之间的关系,可以知道在所有权重中哪个是影响误差的最大因素,利用梯度下降原则调整该权重值,即可使得误差减小,每一次训练都会重复进行这一过程,那么在足够多的样本训练下就可以得到期望的分类集。

上面介绍了大概的思想,接下来就是如何实现:
一、特征的寻找与存取
如何寻找特征,在本例子中要识别的是0-9共10个数字,选取什么作为特征,如何提取特征就是第一步要考虑的。对于这些简单的数字,最简单的方式就是先对所有样本归一化为同一大小,然后提取每一个像素值作为特征输入;另外的特征提取方法还有梯度特征提取,通过sobel算子提取数字图片的水平、垂直特征作为特征输入。
在本例子中采用的是直接提取图片每一个像素值作为特征
那么在程序中如何实现将特征提取与存取:
1、将样本图片归一化为统一大小,这里归一化为8x16像素大小;
2、明确样本总数以及分类结果数,这里要识别0-9共10个数,如果每张数字的样本用50张,那么样本总数为10x50=500张,分类结果数自然为10(10个数嘛);
3、程序实现将所有样本图片进行遍历二值化把所有像素点存入一个样本数据数组中,这个数组的行列分别为样本总数500和每一张图片的特征总数8x16,目的是使得每一行代表一张样本的特征数据;
4、第三步中的特征数据就是感知器里提到的x1-Xn特征输入,那么输出是什么,输出是指定每一张样本图片的输出结果,输出对应于输入,有500个输入,那么就有500个输出,可是500个输出要分为10类,那么最直接的就是0-49为一类,50-99为另一类,以此类推;输出在程序里的体现也是用一个数组表示,定义一个500x10的数组,样本数字0输出为前50行,可定义输出为[1,0,0,0,0,0,0,0,0,0];样本数字1的输出为下50行,可定义输出为[0,1,0,0,0,0,0,0,0,0];依此可得到一个500x10的输出数组;
5、输入输出都有了,最后就是对这些样本参数进行训练,设置训练模型的参数,包括训练网络的层数,训练原理,训练终止条件,训练激活函数等等。
const int imageRows = 8; const int imageCols = 16; //图片共有10类 const int classSum = 10; //每类共50张图片 const int imagesSum = 50; //每一行一个训练图片 float trainingData[classSum*imagesSum][imageRows*imageCols] = { { 0 } };//特征存放数组 //训练样本标签 float labels[classSum*imagesSum][classSum] = { { 0 } }; //结果分类输出数组 Mat src, resizeImg, trainImg; for (int i = 0; i < classSum; i++) { //目标文件夹路径 std::string inPath = "E:\study\VS2015\practice\charSamples\";//存放的样本的目录 char temp[256]; int k = 0; sprintf_s(temp, "%d", i); inPath = inPath + temp + "\*.png"; std::cout << inPath; //用于查找的句柄 long long handle; struct _finddata_t fileinfo; //第一次查找 handle = _findfirst(inPath.c_str(), &fileinfo);//遍历文件夹下的.png文件 //std::cout << "handle :"<<fileinfo.name; if (handle == -1) return -1; do { //找到的文件的文件名 std::string imgname = "E:/study/VS2015/practice/charSamples/"; imgname = imgname + temp + "/" + fileinfo.name; src = imread(imgname, 0); if (src.empty()) { std::cout << "can not load image " << std::endl; return -1; } //将所有图片大小统一转化为8*16 resize(src, resizeImg, Size(imageRows, imageCols), (0, 0), (0, 0), INTER_AREA); threshold(resizeImg, trainImg, 0, 255, CV_THRESH_BINARY | CV_THRESH_OTSU); for (int j = 0; j<imageRows*imageCols; j++) { trainingData[i*imagesSum + k][j] = (float)resizeImg.data[j]; } // 设置标签数据,标签数据里就是500x10的输出数据,训练时会按照这个结果进行误差调节,调整各个特征参数的权重值 for (int j = 0; j < classSum; j++) { if (j == i) labels[i*imagesSum + k][j] = 1; else labels[i*imagesSum + k][j] = 0; } k++; } while (!_findnext(handle, &fileinfo)); Mat labelsMat(classSum*imagesSum, classSum, CV_32FC1, labels); _findclose(handle); } //训练样本数据及对应标签 Mat trainingDataMat(classSum*imagesSum, imageRows*imageCols, CV_32FC1, trainingData); Mat labelsMat(classSum*imagesSum, classSum, CV_32FC1, labels);
二、模型参数的设置
Ptr<ANN_MLP>model = ANN_MLP::create(); Mat layerSizes = (Mat_<int>(1, 5) << imageRows*imageCols, 128, 128, 128, classSum);//设置的网络层数为5层,数组值为每一层的的节点数,输入为8x16=128,输出为10 model->setLayerSizes(layerSizes); model->setTrainMethod(ANN_MLP::BACKPROP, 0.001, 0.1); //训练方式为反向传播 model->setActivationFunction(ANN_MLP::SIGMOID_SYM, 1.0, 1.0);//设置激活函数 model->setTermCriteria(TermCriteria(TermCriteria::MAX_ITER | TermCriteria::EPS, 10000, 0.0001));//设置终止条件,迭代次数满足10000或者误差小于0.0001 Ptr<TrainData> trainData = TrainData::create(trainingDataMat, ROW_SAMPLE, labelsMat); model->train(trainData); //保存训练结果 model->save("E:/study/VS2015/practice/MLPModel.xml"); //保存训练好的模型
设置完毕后即可点击运行进行训练,这里训练的时间会稍稍费点时间,不要以为是程序卡死了,等待3-5分钟即可
三、调用模型进行测试
模型有了之后需要验证,下面就是对模型进行验证,注意在对图片测试时同样要对图片的特征进行提取,只是此时的输出是通过输入特征经过模型计算后得到的,该输出会与原有的10个输出进行比对,比较更接近哪个结果,由此实现识别,所以由此也可以看出样本数量越多或者特征选取更恰当会使得训练出来的模型适用性更高。
int main() { //将所有图片大小统一转化为8*16 const int imageRows = 8; const int imageCols = 16; //读取训练结果 Ptr<ANN_MLP> model = StatModel::load<ANN_MLP>("E:/study/VS2015/practice/MLPModel.xml");//模型存放路径 ////==========================预测部分==============================//// //读取测试图像 Mat test, dst; test = imread("E:/study/VS2015/practice/model4.png", 0); if (test.empty()) { std::cout << "can not load image " << std::endl; return -1; } //将测试图像转化为1*128的向量,为什么是128列,应为训练使采用的输入节点数就是500x128的数组 resize(test, test, Size(imageRows, imageCols), (0, 0), (0, 0), INTER_AREA);//测试图片的特征存放数组 threshold(test, test, 0, 255, CV_THRESH_BINARY | CV_THRESH_OTSU);//测试图片二值化 Mat_<float> testMat(1, imageRows*imageCols); for (int i = 0; i < imageRows*imageCols; i++) { testMat.at<float>(0, i) = (float)test.at<uchar>(i / 8, i % 8);//提取每个点的像素 } //使用训练好的MLP model预测测试图像 model->predict(testMat, dst); std::cout << "testMat: " << testMat << " " << std::endl; std::cout << "dst: " << dst << " " << std::endl;//模型计算得到的输出 double maxVal = 0; Point maxLoc; minMaxLoc(dst, NULL, &maxVal, NULL, &maxLoc); std::cout << "测试结果:" << maxLoc.x << "置信度:" << maxVal * 100 << "%" << std::endl; imshow("test", test); waitKey(0); return 0; }
结尾附上样本集的文件下载链接链接:https://pan.baidu.com/s/14zy7_oGpw8VXG4uAzZ8zBg
提取码:yqt7